可加模型
簡介
可加模型是一種非參數模型,如果說二維散點圖的平滑是簡單線性回歸模型的一般化,那么加性模型就是多元回歸模型的一般化。加性模型非常具有靈活性,因為它不象參數模型那樣需要假設某種函式形式,只要預測變數對回響變數的影響是獨立即可,也稱為可加和假設。
擬合
加性模型的擬合是通過一個疊代過程(向後擬合算法)對每個預測變數進行樣條平滑。其算法要在擬合誤差和自由度之間進行權衡最終達到最優。在R中可以利用mgcv包中的gam函式實現加性模型,我們仍以trees數據集作為例子,其中Volume為回響變數,Girth和Height為預測變數。
------------------------
model=gam(Volume~s(Girth)+s(Height),data=trees)
par(mfrow=c(1,2))
plot(model,se=T,resid=T,pch=16)
------------------------
上面顯示的是各預測變數的偏殘差圖,表示了各預測變數對回響變數的獨立影響,縱軸括弧中的數字表示EDF(estimated degrees of freedom),Height的估計自由度為1,即是線性關係。建模結果存在model變數中,它同樣可以用summary、predict、anova等泛型函式作進一步處理
------------------------
summary(model)
Approximate significance of smooth terms:
edf Ref.df F p-value
s(Girth) 2.693 3.368 203.8 < 2e-16 ***
s(Height) 1.000 1.000 16.0 0.000459 ***
R-sq.(adj) = 0.973 Deviance explained = 97.7%
GCV score = 8.4734 Scale est. = 7.1905 n = 31
------------------------
從上面的結果報告可以觀察到各預測變數的EDF值,後面的P值表示平滑函式是否顯著的減少了模型誤差。偽判定係數R-sq顯示了模型的解釋能力為97.7%。
弱點
加性模型容易被誤用往往是因為沒有注意到其前提假設,在本例中樹圍和樹高對樹木體積的影響並非是可加性的,顯然二者之間存在互動作用,應該用s(Girth,Height)作為預測變數。
gam函式中也能加入線性預測變數,構成半參數加性模型,還可以設定family參數實現廣義加性模型。
此外,加性模型的弱點在於其結果不象參數模型那樣容易解釋,但它用於探索性數據分析和預測工作時是非常有用的分析工具。如果把加性模型當作模型擬合工具而非探索性工具時,其平滑參數的設定就變得非常重要
線性可加模型
一個試驗觀察值按其變異來源劃分的線性分解式。若從一個均數為μ方差為σ2的正態總體中隨機抽取的觀察值xi可分解為總體平均和隨機誤差兩部分,所以其線性可加模型為:
x=μ+ε(1)
式中 ε為隨機誤差服從常態分配N(0,σ)。假如將上述總體分成k個亞總體,各施以不同的處理,設第i處理的效應為τi (i=1,2,…,k),則第i亞總體的平均數為μ=μ+τ。從任一亞總體隨機抽出的觀察值x(i=1,2,…,k,j=1,2,…表示觀察序數)的線性可加模型為:
x=μ+τ+ε(2)
這就是單向分組資料中觀察值的數學模型。根據試驗設計不同可以有不同的線性可加模型,但它們有一共同特點,即各分量都取一次項,故稱之為線性可加模型。如雙向分組資料中觀察值x的線性可加模型為:
x=μ+τ+ρ+ε(3)
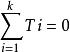 可加模型
可加模型式中 τ為因素A第i水平的效應,ρ為區組j的效應。在式(2)中,ε服從常態分配N(0,σ),但根據τ的性質不同,可分為固定模型和隨機模型。所謂固定模型是指試驗的各處理都抽自特定的處理總體,分別遵循常態分配N(μ,σ),處理效應τ=μ-μ是固定的常量,並滿足 ,試驗目的在於研究τ。如重複做試驗,所用的處理將是同一套的,即處理效應是固定的。根據式(2)模型可導出方差分析中誤差均方S是σ的估值,處理均方S是σ+nk的估值。
所謂隨機模型是指試驗中各處理皆抽自常態分配N(0,σ)的一組隨機樣本,即處理效應τ是隨機的遵循常態分配N(0,σ),試驗目的不在於研究τ本身的大小,而在於研究τ的變異程度,即σ。所以,方差分析所測驗的是H:σ=0,HA:σ>0,統計推斷的不是某些供試處理的效應大小,而是關於抽出這些處理的總體情況,這裡誤差均方S誤估計是σ,而處理均方S估計的是σ+nσ,因此
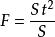 可加模型
可加模型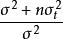 可加模型
可加模型是 的估值
在H:σ=0的假設下,F才能與F比較。顯然固定模型和隨機模型的分析重點不同,前者在於對τ的分析,後者在於對σ的分析。農化研究的試驗資料大多屬於固定模型,如肥料用量試驗和肥料品種試驗等均為固定模型。連續多年進行的肥料試驗中年份效應為隨機模型。
廣義加性模型
提出背景
編輯
非參數回歸不需要模型滿足線性的假設前提,可以靈活地探測數據間的複雜關係,但是當模型中自變數數目較多時 ,模型的估計方差會加大,另外,基於核與光滑樣條估計的非參數回歸中自變數與因變數間關係的解釋也有難度,1985 年 Stone 提出加性模型 (additive models) ,模型中每一個加性項使用單個光滑函式來估計,在每一加性項中可以解釋因變數如何隨自變數變化而變化,很好地解決了上述問題。 1990 年,Hastie 和 Tibshirani 擴展了加性模型的套用範圍 ,提出了廣義加性模型(generalized additive models)。[1]
廣義加性模型
經典的線性回歸模型假定因變數Y與自變數X1,X2....Xp是線性形式:
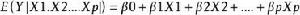 可加模型
可加模型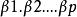 可加模型
可加模型其中, 通過最小二乘法獲得。
加性模型擴展了線性模型:
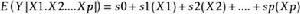 可加模型
可加模型其中,
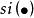 可加模型
可加模型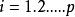 可加模型
可加模型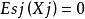 可加模型
可加模型, 是光滑函式, ,
通過backfitting 算法獲得。
廣義加性模型是廣義線性模型的擴展:
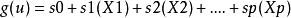 可加模型
可加模型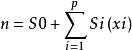 可加模型
可加模型其中,
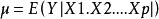 可加模型
可加模型,n為線性預測值,
可加模型是非參數光滑函式 ,它可以是光滑樣條函式、核函式或者局部回歸光滑函式 ,它的非參數形式使得模型非常靈活 ,揭示出自變數的非線性效應。
模型不需要 Y對 X的任何假設 ,由隨機部分Y(random component) 、加性部分n(additive component) 及聯結兩者的連線函式gi(.)(link function) 組成 ,反應變數Y的分布屬於指數分布族 ,可以是二項分布、Poisson 分布 、Gamma 分布等。
模型中不必每一項都是非線性的 ,可以納入線性等參數項 ,因為每個解釋變數的關係如都用非參數擬合會出現計算量大 、過擬合等問題 ,有時因變數與某個預測變數的關係簡化成參數形式會更便於解釋 ,這樣就出現了半參數廣義加性模型 ( semi-parametric generalized additive models) ,其形式為 :
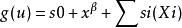 可加模型
可加模型廣義加性模型優缺點
1) 可以引入非線性函式Sj
2) 非線性可能使得對Y預測的更準確
3) 因為是”加性的”,所以,線性模型的假設檢驗的方法仍然可以使用
4) 因為是“加性”假設,所以GAMs中可能會缺失重要的互動作用Xj×Xk,只能通過手動添加互動項來彌補
