![storm[英文單詞]](/img/a/9a7/nBnauM3X2YDN1UTO2EDN0kTO0UTMyITNykTO0EDMwAjMwUzLxQzLwYzLt92YucmbvRWdo5Cd0FmL0E2LvoDc0RHa.jpg "storm[英文單詞]")
單詞釋義
storm
英[stɔːm] 美[stɔrm]
•n. 暴風雨;大動盪
•vi. 起風暴;橫衝直撞;狂怒咆哮
•vt. 猛攻;怒罵
風暴的英文名,是一個天體的大氣的任何不穩定狀態,尤其影響天體的表面,通常會帶來惡劣天氣。風暴可能伴隨著強風、雷和閃電(例如雷暴)、強降水或隨風在大氣中移動的物質(例如沙塵暴、暴風雪和雹暴)。
遊戲人物
風暴之靈- Raijin Thunderkeg - 英雄簡稱:(Storm): 作為近衛軍團在最黑暗的年代所召喚的聖靈,風暴之靈決定在一個卑微的元素使身上證明自己的價值。由於熊貓人自身的靈魂已經在沛不可當的純粹的電子精華的衝擊下被毀滅,加上聖靈又無法使用自己的身體,就乾脆降臨至這個元素使的身上。儘管被凡人的軀體所束縛,風暴之靈仍然表現出極為強大的力量。通過以一種極為神秘的方式操縱廣闊而無窮無忌的力之本源,在近衛軍團的敵人面前召喚出毀滅性的電子火花,碾碎所有敢於在他面前出現的敵人。
日用品名
概述
Storm,是於90年代突然崛起,頗受年輕消費者追崇的,一個專注於時尚生活的品牌,主要產品集中在時尚腕錶、珠寶首飾、箱包、雨傘以及香水等。她是由其創始人Steve Sun於1989年創立。
自誕生之日起,Storm就以獨特的設計理念、優良的產品質量表現及年輕、積極、性感的品牌形象迅速吸引了一大批品牌簇擁者。Storm僅僅用了幾年時間,就躋身倫敦時尚的前沿,迅速成為時尚腕錶的領航者。
每年,無論是優雅的社會名流、還是親民的時尚一族,都對Storm的新品,特別是一些限量款和特別款,翹首企盼。連David Beckham、Justin Timberlake這樣的巨星也是要在Storm的專門店前排隊,購買Storm的限量版產品。發展歷程
發展歷程
與其他偉大的品牌一樣,Storm的誕生也有其浪漫的歷史。
1985年,Steve Sun 發現當時的手錶大都是黑、銀色相間的刻度盤。價格便宜的手錶都非常的單調,並且與昂貴的手錶外觀設計非常相似。Steve突然產生了一個想法,他想建立一個公司來生產人們能夠買得起的有趣的手錶。於是,Steve將彩色的刻度盤和其他革新性的細節引進到手錶中來。因此,他成立了Sun 99有限公司。
1989年,Steve在一次飛機旅途中突然得到靈感,創立了Storm這個品牌。
當時,所有的手錶都是在珠寶店內銷售。Steve則開始與品牌時尚店合作,並開始向他們出售手錶。從此,將手錶作為時尚的飾品進行銷售。崇尚潮流的消費者會在不同的商店比較不同的手錶,並且由於Storm強烈反叛傳統腕錶設計的獨特風格、平易近人的價格,使得人們可以購買更多的手錶,來配合不同的服飾、場合。隨之而來的就是,Storm品牌的壯大,Storm的fans越來越多。
作為一個時尚品牌,Storm逐漸開始向除手錶外的其他產品領域進軍,將更多的產品列入發展計畫。如今,Storm產品類別已經涵蓋了手錶、太陽眼鏡、箱包、皮夾、傘及香水等。通過其業務在全球地擴展,Storm目前已經迅速發展成為一個國際型的知名時尚品牌。
播放軟體
暴風影音是暴風網際公司推出的一款視頻播放器,該播放器兼容大多數的視頻和音頻格式。連續獲得《電腦報》、《電腦迷》、《電腦愛好者》等權威IT專業媒體評選的消費者最喜愛的網際網路軟體榮譽以及編輯推薦的優秀網際網路軟體榮譽。
實時平台
Twitter將Storm正式開源了,這是一個分散式的、容錯的實時計算系統,它被託管在GitHub上,遵循 Eclipse Public License 1.0。Storm是由BackType開發的實時處理系統,BackType現在已在Twitter麾下。GitHub上的最新版本是Storm 0.8.0,基本是用Clojure寫的。
Storm為分散式實時計算提供了一組通用原語,可被用於“流處理”之中,實時處理訊息並更新資料庫。這是管理佇列及工作者集群的另一種方式。 Storm也可被用於“連續計算”(continuous computation),對數據流做連續查詢,在計算時就將結果以流的形式輸出給用戶。它還可被用於“分散式RPC”,以並行的方式運行昂貴的運算。 Storm的主工程師Nathan Marz表示:
Storm可以方便地在一個計算機集群中編寫與擴展複雜的實時計算,Storm用於實時處理,就好比 Hadoop 用於批處理。Storm保證每個訊息都會得到處理,而且它很快——在一個小集群中,每秒可以處理數以百萬計的訊息。更棒的是你可以使用任意程式語言來做開發。
Storm的主要特點如下:
簡單的編程模型。類似於MapReduce降低了並行批處理複雜性,Storm降低了進行實時處理的複雜性。
可以使用各種程式語言。你可以在Storm之上使用各種程式語言。默認支持Clojure、Java、Ruby和Python。要增加對其他語言的支持,只需實現一個簡單的Storm通信協定即可。
容錯性。Storm會管理工作進程和節點的故障。
水平擴展。計算是在多個執行緒、進程和伺服器之間並行進行的。
可靠的訊息處理。Storm保證每個訊息至少能得到一次完整處理。任務失敗時,它會負責從訊息源重試訊息。
快速。系統的設計保證了訊息能得到快速的處理,使用ØMQ作為其底層訊息佇列。
本地模式。Storm有一個“本地模式”,可以在處理過程中完全模擬Storm集群。這讓你可以快速進行開發和單元測試。
Storm集群由一個主節點和多個工作節點組成。主節點運行了一個名為“Nimbus”的守護進程,用於分配代碼、布置任務及故障檢測。每個工作節 點都運行了一個名為“Supervisor”的守護進程,用於監聽工作,開始並終止工作進程。Nimbus和Supervisor都能快速失敗,而且是無 狀態的,這樣一來它們就變得十分健壯,兩者的協調工作是由ApacheZooKeeper來完成的。
Storm的術語包括Stream、Spout、Bolt、Task、Worker、Stream Grouping和Topology。Stream是被處理的數據。Spout是數據源。Bolt處理數據。Task是運行於Spout或Bolt中的 執行緒。Worker是運行這些執行緒的進程。Stream Grouping規定了Bolt接收什麼東西作為輸入數據。數據可以隨機分配(術語為Shuffle),或者根據欄位值分配(術語為Fields),或者 廣播(術語為All),或者總是發給一個Task(術語為Global),也可以不關心該數據(術語為None),或者由自定義邏輯來決定(術語為 Direct)。Topology是由Stream Grouping連線起來的Spout和Bolt節點網路。在Storm Concepts頁面里對這些術語有更詳細的描述。
可以和Storm相提並論的系統有Esper、Streambase、HStreaming和Yahoo S4。其中和Storm最接近的就是S4。兩者最大的區別在於Storm會保證訊息得到處理。Storm,如果需要持久化,可以使用一個類似於Cassandra或Riak這樣的外部資料庫。Storm是分散式數據處理的框架,本身幾乎不提供複雜事件計算,而Esper、Streambase屬於CEP系統。
入門的最佳途徑是閱讀GitHub上的官方《Storm Tutorial》。 其中討論了多種Storm概念和抽象,提供了範例代碼以便你可以運行一個Storm Topology。開發過程中,可以用本地模式來運行Storm,這樣就能在本地開發,在進程中測試Topology。一切就緒後,以遠程模式運行 Storm,提交用於在集群中運行的Topology。
要運行Storm集群,你需要Apache Zookeeper、ØMQ、JZMQ、Java 6和Python 2.6.6。ZooKeeper用於管理集群中的不同組件,ØMQ是內部訊息系統,JZMQ是ØMQ的Java Binding。有個名為storm-deploy的子項目,可以在AWS上一鍵部署Storm集群。關於詳細的步驟,可以閱讀Storm Wiki上的《Setting up a Storm cluster》。
出現的背景
在過去10 年中,隨著網際網路套用的高速發展,企業積累的數據量越來越大,越來越多。隨著Google MapReduce、Hadoop 等相關技術的出現,處理大規模數據變得簡單起來,但是這些數據處理技術都不是實時的系統,它們的設計目標也不是實時計算。畢竟實時的計算系統和基於批處理模型的系統(如Hadoop)有著本質的區別。
但是隨著大數據業務的快速增長,針對大規模數據處理的實時計算變成了一種業務上的需求,缺少“實時的Hadoop 系統”已經成為整個大數據生態系統中的一個巨大缺失。Storm 正是在這樣的需求背景下出現的,Storm 很好地滿足了這一需求。
在Storm 出現之前,對於需要實現計算的任務,開發者需要手動維護一個訊息佇列和訊息處理者所組成的實時處理網路,訊息處理者從訊息佇列中取出訊息進行處理,然後更新資料庫,傳送訊息給其他佇列。所有這些操作都需要開發者自己實現。這種編程實現的模式存在以下缺陷。
● 單調乏味性:開發者需要花費大部分時間去配置訊息如何傳送,訊息傳送到哪裡,如何部署訊息的處理者,如何部署訊息的中間處理節點等。如果使用Storm 進行處理,那么開發者只需要很少的訊息處理邏輯代碼,這樣開發者就可以專注於業務邏輯的開發,從而大大提高了開發實時計算系統的效率。
● 脆弱性:程式不夠健壯,開發者需要自己編寫代碼以保證所有的訊息處理者和訊息佇列的正確運行。
● 可伸縮性差:當一個訊息處理者能處理的訊息達到自己能處理的峰值時,就需要對訊息流進行分流,這時需要配置新的訊息處理者,以讓它們處理分流訊息。
對於需要處理大量訊息流的實時系統來說,訊息處理始終是實時計算的基礎,訊息處理的最後就是對訊息佇列和訊息處理者之間的組合。訊息處理的核心是如何在訊息處理的過程中不丟失數據,而且可以使整個處理系統具有很好的擴展性,以便能夠處理更大的訊息流。而Storm 正好可以滿足這些要求。
套用領域
Storm 有許多套用領域,包括實時分析、線上機器學習、信息流處理(例如,可以使用Storm 處理新的數據和快速更新資料庫)、連續性的計算(例如,使用Storm 連續查詢,然後將結果返回給客戶端,如將微博上的熱門話題轉發給用戶)、分散式RPC(遠過程調用協定,通過網路從遠程電腦程式上請求服務)、ETL(Extraction Transformation Loading,數據抽取、轉換和載入)等。
Storm 的處理速度驚人,經測試,每個節點每秒可以處理100 萬個數據元組。Storm 可擴展且具有容錯功能,很容易設定和操作。Storm 集成了佇列和資料庫技術,Storm 拓撲網路通過綜合的方法,將數據流在每個數據平台間進行重新分配。圖1 所示為Storm 處理訊息流的示意圖。
圖1 Storm 數據流圖
在Storm 訊息處理模型中,訊息源就像圖1 中所示的水龍頭,它可以源源不斷地將訊息傳送到訊息處理者那裡,訊息處理者接收訊息,進行處理,然後訊息處理者既可以將訊息傳送到其他訊息處理者那裡,或者不傳送訊息,表示訊息處理結束。
設計特徵
如同Hadoop 由於定義了並行計算原語,大大簡化了對大規模數據的並行批處理一樣,Storm 也為實時計算定義了一些計算原語,從而簡化了並行實時數據處理的複雜性。Storm 在官方網站中列舉了它的幾大關鍵特徵。
● 適用場景廣:Storm 可以用來處理訊息和更新資料庫(訊息的流處理),對一個數據量進行持續的查詢並將結果返回給客戶端(連續計算),對於耗費資源的查詢進行並行化處理(分散式方法調用),Storm 提供的計算原語可以滿足諸如以上所述的大量場景。
● 可伸縮性強:Storm 的可伸縮性可以讓Storm 每秒處理的訊息量達到很高,如100 萬。實現計算任務的擴展,只需要在集群中添加機器,然後提高計算任務的並行度設定。Storm 網站上給出了一個具有伸縮性的例子,一個Storm套用在一個包含10 個節點的集群上每秒處理1 000 000 個訊息,其中包括每秒100 多次的資料庫調用。Storm 使用Apache ZooKeeper 來協調集群中各種配置的同步,這樣Storm 集群可以很容易地進行擴展。
● 保證數據不丟失:實時計算系統的關鍵就是保證數據被正確處理,丟失數據的系統使用場景會很窄,而Storm 可以保證每一條訊息都會被處理,這是Storm 區別於S4(Yahoo 開發的實時計算系統)系統的關鍵特徵。
● 健壯性強:不像Hadoop 集群很難進行管理,它需要管理人員掌握很多Hadoop 的配置、維護、調優的知識。而Storm 集群很容易進行管理,容易管理是Storm 的設計目標之一。
● 高容錯:Storm 可以對訊息的處理過程進行容錯處理,如果一條訊息在處理過程中失敗,那么Storm 會重新安排出錯的處理邏輯。Storm 可以保證一個處理邏輯永遠運行。
● 語言無關性:Storm 套用不應該只能使用一種編程平台,Storm 雖然是使用Clojure 語言開發實現,但是,Storm 的處理邏輯和訊息處理組件都可以使用任何語言來進行定義,這就是說任何語言的開發者都可以使用Storm。
關鍵概念
(1)計算拓撲(Topologies)
在 Storm 中,一個實時計算應用程式的邏輯被封裝在一個稱為Topology 的對象中,也稱為計算拓撲。Topology 有點類似於Hadoop 中的MapReduce Job,但是它們之間的關鍵區別在於,一個MapReduce Job 最終總是會結束的,然而一個Storm 的Topology 會一直運行。在邏輯上,一個Topology 是由一些Spout(訊息的傳送者)和Bolt(訊息的處理者)組成圖狀結構,而連結Spouts 和Bolts 的則是Stream Groupings。
(2)訊息流(Streams)
訊息流是 Storm 中最關鍵的抽象,一個訊息流就是一個沒有邊界的tuple序列,tuple 是一種Storm 中使用的數據結構,可以看作是沒有方法的Java 對象。這些tuple 序列會被一種分散式的方式並行地在集群上進行創建和處理。對訊息流的定義主要就是對訊息流裡面的tuple 進行定義,為了更好地使用tuple,需要給tuple 里的每個欄位取一個名字,並且不同的tuple 欄位對應的類型要相同,即兩個tuple 的第一個欄位類型相同,第二個欄位類型相同,但是第一個欄位和第二個欄位的類型可以不同。默認情況下,tuple 的欄位類型可以為integer、long、short、byte、string、double、float、boolean 和byte array 等基本類型,也可以自定義類型,只需要實現相應的序列化接口。每一個訊息流在定義的時候需要被分配一個id,最常見的訊息流是單向的訊息流,在Storm 中OutputFieldsDeclarer 定義了一些方法,讓你可以定義一個Stream 而不用指定這個id。在這種情況下,這個Stream 會有個默認的id: 1。
(3)訊息源(Spouts)
Spouts 是Storm 集群中一個計算任務(Topology)中訊息流的生產者,Spouts一般是從別的數據源(例如,資料庫或者檔案系統)載入數據,然後向Topology中發射訊息。在一個Topology 中存在兩種Spouts,一種是可靠的Spouts,一種是非可靠的Spouts,可靠的Spouts 在一個tuple 沒有成功處理的時候會重新發射該tuple,以保證訊息被正確地處理。不可靠的Spouts 在發射一個tuple 之後,不會再重新發射該tuple,即使該tuple 處理失敗。每個Spouts 都可以發射多個訊息流,要實現這樣的效果,可以使用OutFieldsDeclarer.declareStream 來定義多個Stream,然後使用SpoutOutputCollector 來發射指定的Stream。
在Storm 的編程接口中,Spout 類最重要的方法是nextTuple()方法,使用該方法可以發射一個訊息tuple 到Topology 中,或者簡單地直接返回,如果沒有訊息要發射。需要注意的是,nextTuple 方法的實現不能阻塞Spout,因為Storm在同一執行緒上調用Spout 的所有方法。Spout 類的另外兩個重要的方法是ack()和fail(),一個tuple 被成功處理完成後,ack()方法被調用,否則就調用fail()方法。注意,只有對於可靠的Spout,才會調用ack()和fail()方法。
(4)訊息處理者(Bolts)
所有訊息處理的邏輯都在Bolt 中完成,在Bolt 中可以完成如過濾、分類、聚集、計算、查詢資料庫等操作。Bolt 可以做簡單的訊息處理操作,例如,Bolt 可以不做任何操作,只是將接收到的訊息轉發給其他的Bolt。Bolt 也可以做複雜的訊息流的處理,從而需要很多個Bolt。在實際使用中,一條訊息往往需要經過多個處理步驟,例如,計算一個班級中成績在前十名的同學,首先需要對所有同學的成績進行排序,然後在排序過的成績中選出前十名的
成績的同學。所以在一個Topology 中,往往有很多個Bolt,從而形成了複雜的流處理網路。
Bolts 不僅可以接收訊息,也可以像Spout 一樣發射多條訊息流,可以使用OutputFieldsDeclarer.declareStream 定義Stream,使用OutputCollector.emit 來選擇要發射的Stream。在編程接口上,Bolt 類中最終需要的方法是execute()方法,該方法的參數就是輸入Tuple,Bolt 使用OutputCollector 傳送訊息tuple,Bolt 對於每個處理過的訊息tuple 都必須調用OutputCollector 的ack()方法,通知Storm 這個訊息被處理完成,最終會通知到傳送該訊息的源,即Spout。訊息在Bolt 中的處理過程一般是這樣,Bolt 將接收到的訊息tuple 進行處理,然後傳送0 個或多個訊息tuple,之後調用OutputCollector 的ack()方法通知訊息的傳送者。
(5)Stream Groupings(訊息分組策略)
定義一個 Topology 的其中一步是定義每個Bolt 接收什麼樣的流作為輸入。Stream Grouping 就是用來定義一個Stream 應該如何分配給Bolts 上面的多個Tasks。Storm 裡面有6 種類型的Stream Grouping。
● Shuffle Grouping:隨機分組,隨機派發Stream 裡面的tuple,保證每個Bolt 接收到的tuple 數目相同。
● Fields Grouping:按欄位分組,比如按userid 來分組,具有同樣userid 的tuple 會被分到相同的Bolts,而不同的userid 則會被分配到不同的Bolts。
● All Grouping:廣播傳送,對於每一個tuple,所有的Bolts 都會收到。
● Global Grouping: 全局分組,這個tuple 被分配到Storm 中一個Bolt 的其中一個Task。再具體一點就是分配給id 值最低的那個Task。
● Non Grouping:不分組,這個分組的意思是Stream 不關心到底誰會收到它的tuple。目前這種分組和Shuffle Grouping 是一樣的效果,有一點不同的是Storm 會把這個Bolt 放到此Bolt 的訂閱者同一個執行緒裡面去執行。
● Direct Grouping:直接分組,這是一種比較特別的分組方法,用這種分組意味著訊息的傳送者指定由訊息接收者的哪個Task 處理這個訊息。只有被聲明為Direct Stream 的訊息流可以聲明這種分組方法。而且這種訊息tuple 必須使用emitDirect 方法來傳送。訊息處理者可以通過TopologyContext 來獲取處理它的訊息的taskid(OutputCollector.emit 方法也會返回taskid)。
(6)可靠性(Reliability)
Storm 可以保證每個訊息tuple 會被Topology 完整地處理,Storm 會追蹤每個從Spout 傳送出的訊息tuple 在後續處理過程中產生的訊息樹(Bolt 接收到的訊息完成處理後又可以產生0 個或多個訊息,這樣反覆進行下去,就會形成一棵訊息樹),Storm 會確保這棵訊息樹被成功地執行。Storm 對每個訊息都設定了一個逾時時間,如果在設定的時間內,Storm 沒有檢測到某個從Spout 傳送的tuple 是否執行成功,Storm 會假設該tuple 執行失敗,因此會重新傳送該tuple。這樣就保證了每條訊息都被正確地完整地執行。
Storm 保證訊息的可靠性是通過在傳送一個tuple 和處理完一個tuple 的時候都需要像Storm 一樣返回確認信息來實現的,這一切是由OutputCollector 來完成的。通過它的emit 方法來通知一個新的tuple 產生,通過它的ack 方法通知一個tuple 處理完成。
(7)任務(Tasks)
在 Storm 集群上,每個Spout 和Bolt 都是由很多個Task 組成的,每個Task對應一個執行緒,流分組策略就是定義如何從一堆Task 傳送tuple 到另一堆Task。在實現自己的Topology 時可以調用TopologyBuilder.setSpout() 和TopBuilder.setBolt()方法來設定並行度,也就是有多少個Task。
(8)工作進程(Worker)
一個 Topology 可能會在一個或者多個工作進程裡面執行,每個工作進程執行整個Topology 的一部分。比如,對於並行度是300 的Topology 來說,如果我們使用50 個工作進程來執行,那么每個工作進程會處理其中的6 個Tasks(其實就是每個工作進程裡面分配6 個執行緒)。Storm 會儘量均勻地把工作分配給所有的工作進程。
(9)配置
在 Storm 裡面可以通過配置大量的參數來調整Nimbus、Supervisor 以及正在運行的Topology 的行為,一些配置是系統級別的,一些配置是Topology 級別的。所有有默認值的配置的默認配置是配置在default.xml 裡面的,用戶可以通過定義一個storm.xml 在classpath 里來覆蓋這些默認配置。並且也可以使用Storm Submitter 在代碼裡面設定一些Topology 相關的配置信息。當然,這些配置的優先權是default.xml<storm.xml<TOPOLOGY-SPECIFIC 配置。
集群中的組件
Storm 的集群從形式上看和Hadoop 的集群非常相似,也是採用主從架構。但是在Hadoop 上面運行的是MapReduce 的Job, 而在Storm 上面運行的是Topology。它們有很大的不同。它們之間的關鍵區別是,一個MapReduceJob 會有啟動、運行到最終會結束的過程,而一個Topology 在啟動後,會永遠運行。
在Storm 的集群裡面有兩種節點:控制節點和工作節點。控制節點上面運行一個後台進程Nimbus,它的作用類似於Hadoop 裡面的JobTracker。Nimbus 負責在集群裡面分發執行代碼,分配工作給工作節點,並且監控任務的執行狀態。每一個工作節點上面運行一個叫作Supervisor 的守護進程。Supervisor 會監聽分配給自己所在機器的工作,根據需要啟動/關閉工作進程。每一個工作進程執行一個Topology 的一個子集,一個運行的Topology 由運行在很多機器上的很多工作進程組成。
集群中,除了控制節點和工作節點外,Storm 集群使用Apache Zookeeper集群來作為自己的協調系統。下面給出Storm 集群的組織架構,如圖2所示。
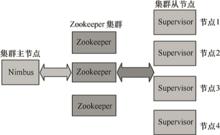 圖2 Storm 集群的組織結構
圖2 Storm 集群的組織結構Nimbus 和Supervisor 之間的所有協調工作都是通過一個Zookeeper 集群來完成的。並且,Nimbus 進程和Supervisor 都是快速失敗和無狀態的。所有的狀態要么在Zookeeper 裡面,要么在本地磁碟上。這也就意味著你可以用kill -9來“殺死”Nimbus 和Supervisor 進程,然後再重啟它們,它們可以繼續工作,就好像什麼都沒有發生過似的。這個設計使得Storm 的運行可以非常穩定。
高效實現信息的可靠性
在Storm中運行著一類特殊的Task,稱為acker。acker 能夠監控每個從Spout傳送的tuple 產生的訊息樹。當acker 發現一個tuple 產生的訊息樹被完整地處理後,會向產生該tuple 的Task 傳送一條通知訊息,表示該訊息已經執行完成。用戶可以通過配置Config.TOPOLOGY_ACKERS 的值來設定一個Topology 中acker 的數量,默認值為1。如果一個Topology 中tuple 的數量較多,就可以將acker 的數量設定得大一些,以此提高整個Topology 運行時的性能。
容錯
Storm 的容錯分為如下幾種類型。
(1)工作進程worker 失效:如果一個節點的工作進程worker“死掉”,supervisor 進程會嘗試重啟該worker。如果連續重啟worker 失敗或者worker 不能定期向Nimbus 報告“心跳”,Nimbus 會分配該任務到集群其他的節點上執行。
(2)集群節點失效:如果集群中某個節點失效,分配給該節點的所有任務會因逾時而失敗,Nimbus 會將分配給該節點的所有任務重新分配給集群中的其他節點。
(3)Nimbus 或者supervisor 守護進程失敗:Nimbus 和supervisor 都被設計成快速失敗(遇到未知錯誤時迅速自我失敗)和無狀態的(所有的狀態信息都保存在Zookeeper 上或者是磁碟上)。Nimbus 和supervisor 守護進程必須在一些監控工具(例如,daemontools 或者monitor)的輔助下運行,一旦Nimbus 或者supervisor 失敗,可以立刻重啟它們,整個集群就好像什麼事情也沒發生。最重要的是,沒有工作進程worker 會因為Nimbus 或supervisor 的失敗而受到影響,Storm 的這個特性和Hadoop 形成了鮮明的對比,如果JobTracker 失效,所有的任務都會失敗。
(4)Nimbus 所在的節點失效:如果Nimbus 守護進程駐留的節點失敗,工作節點上的工作進程worker 會繼續執行計算任務,而且,如果worker 進程失敗,supervisor 進程會在該節點上重啟失敗的worker 任務。但是,沒有Nimbus的影響時,所有worker 任務不會分配到其他的工作節點機器上,即使該worker所在的機器失效。
歌曲名稱
Mr. - Storm
作曲:Tom/MJ
作詞:Ronny
編曲:Mr.
監製:Gary Tong/Davy Chan/C Y Kong
你發病了 吃藥了 也沒法治療
按按脈搏 似亂跳 全身都發燒
到最後也 撲盡了 信念卻動搖
你退席了 缺席了 嘆結局似造謠
放肆在叫 笑著跳 全場新聞對焦
到散席了 喊或笑 諷刺是這結局 難料
誰在意真假 玩弄這差價
不再介意 不想深究大義
丟架 別主宰我的身價
你的眼淚 我沒法掉下
暗角在拍照 疑似與舊愛約會
設計著斜線 從眼角拉到腳尖
有意或無意 如冷箭射向背面
誰在意真假 玩弄這差價
不再介意 不想深究大義
丟架 別主宰我的身價 你的笑話
誰在意真假 玩弄這差價
不再介意 不想深究大義
丟架 別主宰我的身價 你的笑話
誰自製真假 玩弄這差價
只當說笑 倘真相被換掉
虛假 在摧毀你的身價 你的笑話
