jsoup 簡介
Java 程式在解析HTML 文檔時,相信大家都接觸過htmlparser 這個開源項目,我曾經在IBM DW 上發表過兩篇關於htmlparser 的文章,分別是:從HTML中攫取你所需的信息 和擴展HTMLParser 對自定義標籤的處理能力。但現在我已經不再使用htmlparser 了,原因是htmlparser 很少更新,但最重要的是有了jsoup 。
jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似於jQuery的操作方法來取出和運算元據。
1. 從一個URL,檔案或字元串中解析HTML;
2. 使用DOM或CSS選擇器來查找、取出數據;
3. 可操作HTML元素、屬性、文本;
jsoup是基於MIT協定發布的,可放心使用於商業項目。
jsoup 的主要類層次結構如下圖所示:

接下來我們專門針對幾種常見的套用場景舉例說明jsoup 是如何優雅的進行HTML 文檔處理的。文檔輸入
jsoup 可以從包括字元串、URL地址以及本地檔案來載入HTML 文檔,並生成Document 對象實例。
下面是相關代碼:
// 直接從字元串中輸入HTML 文檔
String html = "<html><head><title>開源中國社區</title></head>"
+"<body><p>這裡是jsoup 項目的相關文章</p></body></html>";
Document doc = Jsoup.parse(html);
// 從URL直接載入HTML 文檔
Document doc =Jsoup.connect("網址/").get();
String title = doc.title();
Document doc =Jsoup.connect("網址/")
.data("query", "Java") //請求參數
.useragent("I’mjsoup") //設定User-Agent
.cookie("auth", "token") //設定cookie
.timeout(3000) //設定連線逾時時間
.post(); //使用POST方法訪問URL
// 從檔案中載入HTML 文檔
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","網址/");
請大家注意最後一種HTML 文檔輸入方式中的parse 的第三個參數,為什麼需要在這裡指定一個網址呢(雖然可以不指定,如第一種方法)?因為HTML 文檔中會有很多例如連結、圖片以及所引用的外部腳本、css檔案等,而第三個名為baseURL 的參數的意思就是當HTML 文檔使用相對路徑方式引用外部檔案時,jsoup會自動為這些URL 加上一個前綴,也就是這個baseURL。
例如<a href=/project>開源軟體</a> 會被轉換成<a href=網址>開源軟體</a>。
這部分涉及一個HTML 解析器最基本的功能,但jsoup使用一種有別於其他開源項目的方式——選擇器,我們將在最後一部分詳細介紹jsoup選擇器,本節中你將看到jsoup是如何用最簡單的代碼實現。
不過jsoup也提供了傳統的DOM 方式的元素解析,看看下面的代碼:
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8","網址/");
Element content =doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref =link.attr("href");
String linkText =link.text();
}
你可能會覺得jsoup的方法似曾相識,沒錯,像getElementById 和getElementsByTag 方法跟JavaScript 的方法名稱是一樣的,功能也完全一致。你可以根據節點名稱或者是HTML 元素的id 來獲取對應的元素或者元素列表。
與htmlparser 項目不同的是,jsoup 並沒有為HTML 元素定義一個對應的類,一般一個HTML 元素的組成部分包括:節點名、屬性和文本,jsoup 提供簡單的方法供你自己檢索這些數據,這也是jsoup保持瘦身的原因。
而在元素檢索方面,jsoup 的選擇器簡直無所不能,
File input = new File("D:\test.html");
Document doc =Jsoup.parse(input,"UTF-8","網址");
Elements links = doc.select("a[href]"); // 具有href 屬性的連結
Elements pngs = doc.select("img[src$=.png]");//所有引用png圖片的元素
Element masthead =doc.select("div.masthead").first();
// 找出定義了class=masthead 的元素
Elements resultLinks = doc.select("h3.r >a"); // direct a after h3
這是jsoup 真正讓我折服的地方,jsoup使用跟jQuery 一模一樣的選擇器對元素進行檢索,以上的檢索方法如果換成是其他的HTML 解釋器,至少都需要很多行代碼,而jsoup 只需要一行代碼即可完成。
jsoup 的選擇器還支持表達式功能,我們將在最後一節介紹這個超強的選擇器。
在解析文檔的同時,我們可能會需要對文檔中的某些元素進行修改,例如我們可以為文檔中的所有圖片增加可點擊連結、修改連結地址或者是修改文本等。
下面是一些簡單的例子:
doc.select("div.commentsa").attr("rel", "nofollow");
//為所有連結增加rel=nofollow 屬性
doc.select("div.commentsa").addClass("mylinkclass");
//為所有連結增加class=mylinkclass 屬性
doc.select("img").removeAttr("onclick");//刪除所有圖片的onclick屬性
doc.select("input[type=text]").val("");//清空所有文本輸入框中的文本
道理很簡單,你只需要利用jsoup 的選擇器找出元素,然後就可以通過以上的方法來進行修改,除了無法修改標籤名外(可以刪除後再插入新的元素),包括元素的屬性和文本都可以修改。
修改完直接調用Element(s) 的html() 方法就可以獲取修改完的HTML 文檔。
jsoup 在提供強大的API 同時,人性化方面也做得非常好。在做網站的時候,經常會提供用戶評論的功能。有些用戶比較淘氣,會搞一些腳本到評論內容中,而這些腳本可能會破壞整個頁面的行為,更嚴重的是獲取一些機要信息,例如XSS 跨站點攻擊之類的。
jsoup 對這方面的支持非常強大,使用非常簡單。看看下面這段代碼:
String unsafe = "<p><a href="網址">開源中國社區</a></p>";
String safe = Jsoup.clean(unsafe, Whitelist.basic());
// 輸出:
// <p><ahref="網址" rel="nofollow">開源中國社區</a></p>
jsoup 使用一個Whitelist 類用來對HTML 文檔進行過濾,該類提供幾個常用方法:
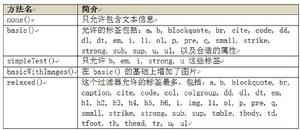
如果這五個過濾器都無法滿足你的要求呢,例如你允許用戶插入flash 動畫,沒關係,Whitelist提供擴展功能,例如whitelist.addTags("embed","object","param","span","div");也可調用addAttributes 為某些元素增加屬性。jsoup 的過人之處——選擇器
前面我們已經簡單的介紹了jsoup是如何使用選擇器來對元素進行檢索的。本節我們把重點放在選擇器本身強大的語法上。下表是jsoup選擇器的所有語法詳細列表。
基本用法
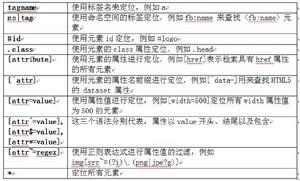
以上是最基本的選擇器語法,這些語法也可以組合起來使用,下面是jsoup支持的組合用法:

除了一些基本的語法以及這些語法進行組合外,jsoup 還支持使用表達式進行元素過濾選擇。下面是jsoup支持的所有表達式一覽表:

總結
jsoup 的基本功能到這裡就介紹完畢,但由於jsoup 良好的可擴展性API 設計,你可以通過選擇器的定義來開發出非常強大的HTML 解析功能。再加上jsoup 項目本身的開發也非常活躍,因此如果你正在使用Java ,需要對HTML 進行處理,不妨試試。
