把火狐偽裝成爬蟲有什麼好處呢?對經常光顧verycd的朋友們非常有用。可以免登錄看貼。首先我們用火狐測試一下:打開這裡是不是要求你登錄?
繼續,設定方法,打開火狐,Ctrl+T新建一個瀏覽標籤,輸入:about:config,打開配置頁面,右鍵點擊頁面選擇“新建→字元串”,在彈出的視窗中輸入:general.useragent.override,確定之後,輸入:Googlebot/2.1 (+http://www.googlebot.com/bot.html),繼續確定,關閉視窗。
其實上次Matt所透露的僅僅是其中一方面的內容。今天,Matt再次寫了一篇非常詳細的文章,解釋了Google的各種bot是怎樣抓取網頁的,以及Google最新的BigDaddy在抓取網頁方面有什麼新的變化等等,內容非常的精彩,所以和大家分享一下。
正如本站之前所報導的那樣,Google最新的軟體層面的升級(轉移至BigDaddy)已經接近完成,因此升級後的Google各方面的能力都將得到加強。這些加強包括了更智慧型化的googlebot爬行、改良的規範性以及更好的收錄網頁能力。而在Googlebot爬行抓取網頁方面,Google也採取了節省頻寬的方法。Googlebot也隨著BigDaddy的升級而得到了升級。新的Googlebot已經正式支持了gzip編碼,所以如果你的網站開啟了gzip編碼功能,那么就能節省Googlebot爬行你的網頁時所占的頻寬。
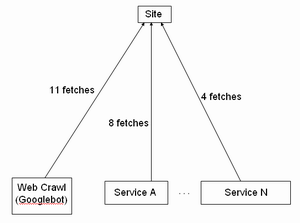
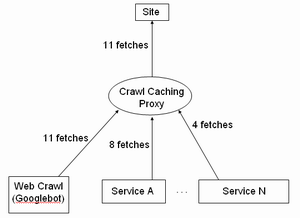
除了改良的Googlebot外,升級後的Google將會採用上面所說到的crawl caching proxy來抓取網頁,以進一步節省頻寬。下面是一個示意圖,顯示了傳統的Googlebot是怎樣爬行一個網站的:
