
流處理器管理
 NVIDIA Maxwell架構節能技術
NVIDIA Maxwell架構節能技術Maxwell 針對流式多處理器 (SM) 而採用一種全新設計,可大幅提高每瓦特性能和每單位面積的性能。雖然 Kepler SMX 設計在這一代產品中已經相當高效,但是隨著它的發展,NVIDIA 的 GPU 架構師看到了架構效率再一次重大飛躍的機遇。 Maxwell SM 設計實現了這一願景。
控制邏輯分區、負載平衡、時鐘門控粒度、調度、每時鐘周期發出指令條數等方面的改進以及其它諸多增強之處讓 Maxwell SM (亦稱“SMM”) 能夠在效率上遠超 Kepler SMX。全新的 Maxwell SM 架構讓我們能夠在 GM107中將 SM 的數量增加至五個(相比之下 GK107 中只有兩個),而晶片面積卻僅增加 25%。
負載平衡
 NVIDIA Maxwell架構節能技術
NVIDIA Maxwell架構節能技術Maxwell 效率上的提升主要歸功於全新的 Maxwell SM 架構,即 SMM 。這種全新的 SM 架構可大幅提升節能性,而且在著色器有限的工作場合中可令每個 CUDA 核心的性能提升 35%。實現這些進步需要對架構進行大量重大更改。NVIDIA 重新編寫了 SM 調度器架構和算法,使其更加智慧型,避免了不必要的停頓,同時進一步降低了調度每條指令所需的能耗。
NVIDIA 在 Maxwell 更改了 SM 的組織方式。每個 SM 分為四個獨立的處理塊,每個處理塊具備自己的指令緩衝區、調度器以及 32 個 CUDA 核心。Kepler 的方法是劃分為非2冪 (non-power-of-two) 數量的 CUDA 核心,其中一些是共享核心,這種方法現已棄用。新的劃分方法簡化了設計與調度邏輯、節省了面積與功耗、降低了計算延遲。
成對的處理塊共享四個紋理過濾單元和一個紋理高速快取。計算一級高速快取的功能也與紋理高速快取相結合,而共享顯存是一個獨立的單元(類似首款 CUDA GPU—— G80 中所使用的方法),被全部四個塊共享。
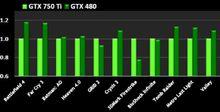
總體而言,在這一全新設計上,每個 SMM 的尺寸得到大幅縮減,而性能卻能夠達到一個 Kepler SMX 的 90%。更小的面積讓 NVIDIA 能夠在每顆 GPU 中實現更多數量的 SMM 。通過對比 GK107 和 GM107 SM 總數的相關指標可發現,GM107 有五個 SM,而前者只有兩個。GM107 的峰值紋理性能比前者高 25%,CUDA 核心數量多 1.7 倍,著色器性能大約高 2.3 倍。
片上快取及顯存
Maxwell 包含了容量大增的二級高速快取設計,GM107 中的容量為 2048KB,而 GK107 中的容量僅為 256KB。由於片上高速快取容量更大,因此需要向顯示卡 DRAM 傳送的請求更少,從而降低了整體顯示卡功耗、提升了性能。
對 GM107 來說,要在顯存位寬與 GK107 相同的情況下實現性能大幅提升的目標,增強顯存系統也同樣重要。內部顯存系統頻寬實現了提升,另外這一設計的效率也得到了改善。此外,2MB 大容量二級高速快取配置(比之前的任何 GPU 設計都大)十分有效地降低了顯存頻寬需求,確保了 DRAM 頻寬不成為瓶頸。
