基本概念
話務量是電信業務流量的簡稱,也稱為電信負載量。它既表示電信設備承受的負載,也表示用戶對通信需求的程度。話務量的大小與用戶數量、用戶通信的頻繁程度、每次用戶通信占用的時長及所考察的時長(是一分鐘,是一小時或是一天等)有關。如果單位時間內的通信次數越多,每次通信占用的時間越長,而且所考察的時間也越長,那么話務量也就越大。由於用戶呼叫的發生和完成一次通信所需時間的長短,都是隨機的和變化的,所以話務量是一個隨時間變化的隨機變數。
測量方法
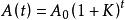 話務量預測
話務量預測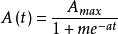 話務量預測
話務量預測話務總量的預測方法可以分為兩類:一是從預測區域的話務源總量N(t),例如話機總數(也可以是用戶數或人口數)乘以平均各話務源發出的話務量a(t),即為預測t時間該區域的話務總量A(t)=N(t)*a(t)它們都是時間t的函式。這個方法要求調查研究出可信的N(t)值,當a(t)變化範圍較小時,預測得較準;另一類方法是根據歷年的話務總量,用時間序列回歸外延,或同時利用社會經濟發展的歷年與今後預計值進行相關回歸,這個方法中選用的模式很重要,在電話網起步階段,最簡單的模式可用指教法,即,式中A0為基礎年的總量,K為用歷年數據回歸得到的年均增長率,但當近年實際話務總量增加太快時,就不宜再簡單地運用這種外延法,否則便可能計算出明顯偏高的結果,因為近期的太高增長有可能不會持續不變。此時,應該利用飽和曲線模式。Amax為預計飽和值,m及a是歷年數據回歸待求的參數。關鍵是確定Amax值,可參考電信已開發國家或地區的平均單機(或人均)話務量,推算出適合預測區域的量乘以話機總數得到。
套用
話務流量流向的預測,一般都利用各局的預測話務總量及全網中反映流量流向的各局間已有話務量矩陣進行再分配的辦法得出,矩陣的再分配一般可用雙因子法。當已有歷年的統計資料是全年或全月的實際接通次數時,首先應乘以忙月、忙日、忙時等集中係數,折算到忙時的量。從實際接通次數換算到以愛爾蘭為單位的話務量時,應考慮每次接通的平均占線時長,以及電路群上溢呼比的影響,即應考慮有多少潛在話務量。由於各參數都會隨各種條件與時間的變化而改變,因此預測時必須注意這些因素的影響。
意義
接通率是呼叫中心最重要的績效指標,人員成本是呼叫中心最大的成本項目,追求高接通率和低人力成本是呼叫中心日常管理的最重要內容,兩者具有內在的矛盾性和目標層面的統一性,均依賴於話務量這一因素。因此,對話務量的準確預測決定了呼叫中心的運營效率。
話務量預測有兩大目的:一是為呼入現場的排班做支持,二是為人力資源部門的招聘和培訓做決策參考。沒有良好的話務量預測,對人員的需求測算就無從談起,更加實現不了科學的排班和管理,通常不是造成客戶滿意率下降就是造成人員冗餘,嚴重干擾了客戶服務中心的科學決策。
現狀
當前,幾乎所有呼叫中心均面臨話務量預測的不準確問題,或者說話務量的預測沒能給排班作出很好的支持,一方面是誤差過大,另一方面是沒有體系化支撐,對異常情況反映不靈敏,話務量預測停留在簡單的序列模型和手工計算上。
