
推廣
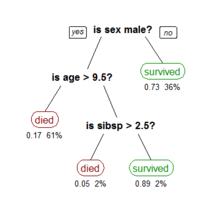 一個描述鐵達尼號上乘客生存的決策樹
一個描述鐵達尼號上乘客生存的決策樹在數據挖掘中決策樹訓練是一個常用的方法。目標是創建一個模型來預測樣本的目標值。例如右圖。每個內部節點 對應於一個輸入屬性,子節點代表父節點的屬性的可能取值。每個葉子節點代表輸入屬性得到的可能輸出值。
一棵樹的訓練過程為:根據一個指標,分裂訓練集為幾個子集。這個過程不斷的在產生的子集裡重複遞歸進行,即遞歸分割。當一個訓練子集的類標都相同時 遞歸停止。這種決策樹的自頂向下歸納 (TDITD) 是貪心算法的一種, 也是當前為止最為常用的一種訓練方法。
數據以如下方式表示:
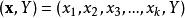 決策樹學習
決策樹學習其中Y是目標值,向量x由這些屬性構成, x1, x2, x3 等等,用來得到目標值。
決策樹的類型
在數據挖掘中,決策樹主要有兩種類型:
•分類樹的輸出是樣本的類標。
•回歸樹的輸出是一個實數 (例如房子的價格,病人待在醫院的時間等)。
術語分類和回歸樹 (CART) 包含了上述兩種決策樹, 最先由Breiman 等提出。分類樹和回歸樹有些共同點和不同點—例如處理在何處分裂的問題。
有些集成的方法產生多棵樹:
•裝袋算法(Bagging), 是一個早期的集成方法,用有放回抽樣法來訓練多棵決策樹,最終結果用投票法產生。
•隨機森林(Random Forest) 使用多棵決策樹來改進分類性能。
•提升樹(Boosting Tree) 可以用來做回歸分析和分類決策。
•旋轉森林(Rotation forest) – 每棵樹的訓練首先使用主元分析法 (PCA)。
還有其他很多決策樹算法,常見的有:
•ID3算法
•C4.5算法
•CHi-squared Automatic Interaction Detector (CHAID), 在生成樹的過程中用多層分裂 。
•MARS可以更好的處理數值型數據。
模型表達式
構建決策樹時通常採用自上而下的方法,在每一步選擇一個最好的屬性來分裂。"最好" 的定義是使得子節點中的訓練集儘量的純。不同的算法使用不同的指標來定義"最好"。本部分介紹一些最常見的指標。
基尼不純度指標
在CART算法中, 基尼不純度表示一個隨機選中的樣本在子集中被分錯的可能性。基尼不純度為這個樣本被選中的機率乘以它被分錯的機率。當一個節點中所有樣本都是一個類時,基尼不純度為零。
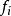 決策樹學習
決策樹學習假設y的可能取值為{1, 2, ..., m},令是樣本被賦予i的機率,則基尼指數可以通過如下計算:
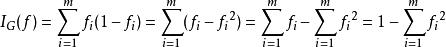 決策樹學習
決策樹學習信息增益
ID3,C4.5 和C5.0決策樹的生成使用信息增益。信息增益 是基於資訊理論中信息熵的理論。
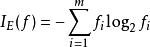 決策樹學習
決策樹學習決策樹的優點
與其他的數據挖掘算法相比,決策樹有許多優點:
•易於理解和解釋 人們很容易理解決策樹的意義。
•只需很少的數據準備 其他技術往往需要數據歸一化。
•即可以處理數值型數據也可以處理類別型 數據。其他技術往往只能處理一種數據類型。例如關聯規則只能處理類別型的而神經網路只能處理數值型的數據。
•使用白箱 模型. 輸出結果容易通過模型的結構來解釋。而神經網路是黑箱模型,很難解釋輸出的結果。
•可以通過測試集來驗證模型的性能 。可以考慮模型的穩定性。
•強健控制. 對噪聲處理有好的強健性。
•可以很好的處理大規模數據 。
缺點
•訓練一棵最優的決策樹是一個完全NP問題。因此, 實際套用時決策樹的訓練採用啟發式搜尋算法例如 貪心算法 來達到局部最優。這樣的算法沒辦法得到最優的決策樹。
•決策樹創建的過度複雜會導致無法很好的預測訓練集之外的數據。這稱作過擬合。 剪枝機制可以避免這種問題。
•有些問題決策樹沒辦法很好的解決,例如 異或問題。解決這種問題的時候,決策樹會變得過大。 要解決這種問題,只能改變問題的領域或者使用其他更為耗時的學習算法 (例如統計關係學習 或者 歸納邏輯編程).
•對那些有類別型屬性的數據, 信息增益 會有一定的偏置 。
延伸
決策圖
在決策樹中, 從根節點到葉節點的路徑採用匯合或與。 而在決策圖中, 可以採用 最小訊息長度 (MML)來匯合兩條或多條路徑。
用演化算法來搜尋
演化算法可以用來避免局部最優的問題 。
