
後組式索引也稱概念組配索引,其基本出發點是認為各種完整的、複雜的概念,都可以分解成更為一般的單元性概念。反之,各種完整的、複雜的概念都可以通過一般的單元性概念的組合或組配來構成。後組式索引就是基於這種思想建立起來的。後組式索引在文獻標引時,是把文獻的主題分析成一些獨立的概念單元,把這篇文獻號分別標在這些概念單元之下,而在檢索時,通過把有關的概念單元進行邏輯乘,邏輯或,邏輯非等方式來構成自己的檢索提問 。
 後組式標引
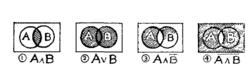
後組式標引那么,什麼是邏輯乘、邏輯或、邏輯非?及其它們怎樣被用來與各種概念單元有機聯繫在一起來構成檢索提問的呢?下面用文氏圖說明之:
圖①陰影部分表示A且B("∧"是邏輯乘符號),意思是既屬於集合A也屬於集合B(A和B是兩個不同的集合)。
圖②陰影部分表示A或B(“∨”是邏輯加符號),意思是或者屬於集合A或者屬於集合B。
圖③陰影部分表示A且非(B“-”是邏輯非符號),意思是屬於集合A但不屬於集合B。
圖④的陰影部分表示不是既屬於A一也屬於B的,是同圖①完全相反的。
①一④式為邏輯表達式,當然還可以舉出很多。如果將集合A與集合B分別賦予不同的內容,則上面的文氏圖分別代表著不同的含義。下面說明後組式索引的標引與檢索。
 後組式標引
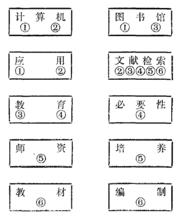
後組式標引假定有下列幾篇文獻其主題及其文獻代號為:
計算機在圖書館中的套用 ①
計算機在文獻檢索中的套用 ②
利用圖書館進行文獻檢索的教育 ③
試論文獻檢索教育的必要性 ④
關於文獻檢索教育的必要性 ⑤
關於文獻檢索教材的編制 ⑥
我們可以將上述六篇文獻分析出“計算機”,“圖書館”,“套用”,“文獻檢索“,“教育,“必要勝,“師資,“培養,“教材,“編制”十個概念單元,然後為每一個單元詞作一卡片,以該詞作標識,在其下記下相應的文獻號。
檢索時,根據檢索提問,可以選取有關的概念單元卡片進行組配。所謂組配,就是尋找出構成檢索提問的各有關概念單元,根據檢索提問的不同,分別找出相應的文獻號碼。若是邏輯乘的關係,則在有關的概念單元之下找出相同的文獻號碼,即為命中文獻。
例如,我們要查找“計算機在圖書館中的套用”這篇文獻,就可以將“計算機”、“圖書館”和“套用”三張卡片中的文獻號相比較,可以發現在這三張卡片中相同的文獻號只有①,故①號文獻即為命中文獻。若是邏輯或的關係,則處於“或”關係之下的相應的概念單元卡上的文獻號碼皆為命中文獻。若是邏輯非的關係,則是將被否定概念單元卡上的文獻號排除在外。
如要查找不是在圖書館中的計算機套用方面的文獻,只有②號文獻符合檢索命題,②號文獻即為所求。後組式索引可以靈活地提高檢索提間的專指度。如要查找一篇有關文獻檢索師資的培養問題方面的文獻,則只有⑤號文獻符合命題。另外還可以任意擴大提間的泛指度。如要查找有關文獻檢索方面的文獻,則②③④⑥⑥五篇文獻皆為命中文獻。顯然,後組式索引對於手工操作是十分不便的,如一個概念單元之下標有兒百篇文獻,對一個有若干個概念單元組合而成的複雜提問,那么手工操作是非常麻煩的事情,而且速度慢,效果差。
 後組式標引
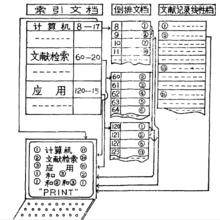
後組式標引然而,後組式索引為計算機檢索作了有益的探討,為實現自動化檢索提供了可能,計算機的高速準確的邏輯匹配功能,使後組式索引得到了進一步的利用。後組式索引系統在計算機中的存貯可以建立三個文檔,一個是索引文檔,一個是倒排文檔,一個是文獻記錄線性文檔。存貯結構如圖。在索引文檔中,每個詞附有兩個數據項目,第一個表示屬於該詞之下的文獻存貯的起始地址,第二個表示被標定在該詞之下的文獻數目。倒排文檔為索引文檔中出現的每個詞存貯該詞的全部文獻號碼,即標定在該詞之下的全部文獻號碼錶。文獻記錄線性文檔是一種按文獻號組織的文檔,這個文檔為資料庫中的每一篇文獻存貯各種查找數據,如文獻篇名、出處,作者或者文獻的文摘等。下面舉一實例說明後組式索引的在線上檢索過程,見圖。
假設我們要查找有關計算機在文獻檢索方面的套用的文獻,檢索人員就可以通過終端分別將概念單元“計算機”、“文獻檢索”、“套用”分別輸入給計算機檢索系統。當檢索人員輸入提問①“計算機”時,系統很快回響,通知檢索者有17篇滿足提問的文獻。當檢索人員輸入提問②“文獻檢索”時,系統馬上通知有20篇滿足提問的文獻。當檢索人員輸入提問③“套用”時,系統馬上給出數字15,表示有15篇文獻滿足提問。當檢索人員需要更專指的提問輸入①和③時,系統馬上給出數字2,表示有兩篇是關於計算機套用的文獻。假設檢索人員還需要更專指的檢索提間,輸入①和②和③,(即需要查找計算機在文獻檢索中的套用)時,系統馬上通知只有一篇滿足提問。當檢索人員需要了解他查找的文獻的有關信息的時候,即可給計算機下達輸出命令,此時,系統則馬上在文獻記錄線性文檔中查找出有關的記錄並輸出。限於篇幅,在此只能對後組式索引的原理及其存貯與檢索作一簡單地介紹。隨著計算機技術的不斷發展,後組式索引將會得到廣泛的套用。
