
簡介
現代控制系統中控制對象可能是複雜、分散的,而且往往是並行、獨立工作的,但整體上它們是相互關聯的有機組合。因此,控制信號的時序邏輯則要求更加精確。 網路延時控制多以可程式線延時晶片和單片機為基礎,通過設計可程式延時控制系統,以達到對時間進行精密時延控制的需求。 同時,作為大型複雜控制裝置的一個重要組成部分,多感測器延時控制系統(Multi—sensorDelay Control System,MDCS系統)還要負責給出一個關鍵延時參數的估計。
系統結構
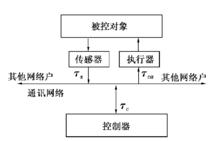 網路延時控制系統結構圖
網路延時控制系統結構圖閉環網路延時控制系統的結構如圖所示。τ表示感測器到控制器的傳輸延時; τ表示控制器對從感測器接收到的數據包進行解包、解碼,實施控制算法並將結果編碼、打包所需要的時間,稱為控制器計算延時; τ表示控制器到執行器的傳輸延時。因此,網路總延時可以表示為τ = τ+ τ + τ。τ可以認為是恆定值,並可以等價地歸入τ中。而τ和τ則根據控制網路的不同或是恆定的或是時變的。所以系統的總延時可以簡單地表示為
τ = τ + τ。
基本問題
在網路延時控制系統中,網路是控制系統的各種信息進行傳輸和交換的唯一通道。網路數據傳輸中存在的一些基本問題,包括時變傳送周期、網路誘導時延、對象輸入輸出的單包和多包數據傳送以及網路的數據丟包等,影響到延時控制系統的建模、系統的分析和設計。
時變傳送周期
常規的計算機延時控制系統理論中,假定對象的輸出是等間隔採樣的,也就是說是在時間間隔k( k = 0,1,…) 上周期地採樣的,這裡的h 就是固定的採樣周期。這種假設就引出了線性時不變採樣系統,並且大地簡化了系統的穩定性和性能分析。然而,這種等間隔採樣的假設不能用於對網路延時控制系統的分析。在網路延時延時控制系統中樣本的傳送可能是周期性的或非周期性的。這主要取決於控制網路的介質訪問控制協定( Medium Access Control protocol,簡稱MAC 協定) 。MAC 一般分成兩類: 隨機訪問和調度。載波偵聽多路存取( CSMA) 就常用於隨機訪問網路中,而令牌傳送( TP) 和時分多址( TDMA) 一般使用於調度網路。
網路誘導時延
網路延時控制系統中的網路誘導時延是當感測器、執行器和控制器在網路中傳輸數據時產生的。如果不考慮這種時延將會降低延時控制系統的性能,甚至會引起系統不穩定。隨機訪問的網路中數據包受隨機時延的響,數據包最壞的傳輸時間是無限。因此,CSMA 網路通常被認為是不確定的。然而,如果網路信息被區了優先權,則較高優先權的信息具有一個比較好的及時傳輸的機會( 如CAN 和設備網) 。
單包和多包數據傳輸
單包傳輸的意思就是把感測器和執行器的數據打成一個網路數據包,然後在同一時間傳輸,而多包傳輸中,感測器和執行器數據以各自的網路數據包形式傳輸,它們有可能不同時到達控制器和對象。多包傳輸現的原因:
1) 由於受數據包大小的限制,數據包轉換網路在一個數據包中只能攜帶有限的信息,因此,大的數據必須分成多個包傳輸;
2) 網路延時控制系統中的感測器和執行器常常分布在一個很大的範圍內,這樣就不可能把數據都放到一個網路包裡面。常規的數據採樣系統假定對象輸出和控制輸入是在同一時間內傳的,這可能在多包傳輸的網路延時控制系統中是不正確的。由於網路訪問時延,控制器可能在控制計算時不能接收到對象輸出的所有更新數據。
網路的數據丟包
網路的數據丟包發生在出現節點傳送失敗或信息衝突的網路延時控制系統中。儘管大多數網路協定都有重發機制,但重發次數有限,最後一次中斷之後,包就丟失了。此外,對於實時反饋控制數據,比如感測器測量值和計算出的控制信號,如果可能的話,丟棄舊的和未傳送的數據,然後重新傳送一個新的數據包可能會更好,這樣,控制器一直都能接收到用於控制計算的最新數據。
研究現狀
確定性狀態增廣離散時間模型方法
在帶定長時延的離散時間系統中,用的最多最廣泛的一種網路控制方法是狀態增廣法。它通過將經過延遲的對象的輸入輸出變數作為增廣狀態,並建立新的狀態空間方程,與原始狀態方程聯立共同來描述系統。增廣狀態的維數與系統狀態維數、輸入維數以及時延大小有關,因而描述系統的增廣狀態方程的維數常常變得很大,系統的複雜性也相應地大幅度增加。
佇列方式
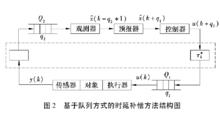 基於佇列方式的時延補償方法結構圖
基於佇列方式的時延補償方法結構圖如圖基於佇列方式的時延補償方法結構圖Luck 和Ray 得出了基於隨機時延的網路延時控制系統的補償方法。時延補償是利用觀測器來估計對象狀態,利用預估器來計算基於過去測量信號的預測控制輸入。時延補償算法的結構框圖如圖所示。
為了保存過去的測量信號,這些數據必須被存儲在一個先進先出的佇列中( 如圖中的Q) ,控制器的預測控制輸入則存放在執行器的另一個佇列( 如圖中的Q) ,因此,感測器到控制器的時延和控制器到執行器的時延都轉換成了不變時延。同時,將具有隨機時延的網路延時控制系統變成不變時延系統,因而系統的控制變得簡單了。
由於觀測器和預估器的性能在很大程度上依賴於模型的準確性,因而要實施這種方法就要求獲得對象的精確模型; 同時,佇列的使用也在系統中引入了額外的時延,因而獲得的控制性能是保守的。
混沌方法
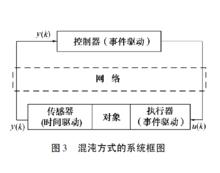 混沌方式的系統框圖
混沌方式的系統框圖混沌方法是由Walsh、Beldiman 和Bushneu 提出的。該方法使用時間驅動的感測器、事件驅動的控制器和事件驅動的執行器。只有從感測器傳送出去的數據信息經過網路傳輸。該控制迴路由一個非線性控制器和一個非線性對象組成。但是,該方法中使用的相似分析也可以用於線性系統,如圖是系統框圖。
這種方法可用於循環系統和隨機訪問類型的網路,但是這些網路必須是嚴格的基於優先權的網路。這意味著網路可以分配不同的優先權給系統中傳輸數據的部件。這些優先權在每個信息的數據幀中以編碼形式存在,優先權編碼的數量取決於不同的協定。這些優先權可以是固定的,也可以是變化的,固定的和變化的優先權調度算法分別叫做靜態調度和動態調度,此外,還有一種新穎的動態調度協定稱為TOD( Try-Once-Discard) ,在TOD 協定中,感測器傳輸信息的優先權由原來和現在的數據誤差決定。當從具有最高優先權的感測器傳輸信息時,其他感測器的信息將會放棄。
不同於原先的辦法,混沌方法的關鍵在於將網路延時控制系統的傳輸時延影響表示為不考慮觀測噪聲時連續時間系統的混合,這時需要採樣周期非常小,這樣網路延時控制系統才能近似於連續時間模型。混沌方法最大的優點是它能套用於非線性系統,然而,這種方法不能用於包含控制器到執行器時延的系統。
採樣時間確定方式
這種方法的基本觀點是為離散時間網路延時控制系統選擇一個合適的足夠長的採樣周期,以致通訊時延不會影響控制性能,並且系統仍能保持穩定。在這種情況下,離散時間控制迴路的控制時延τ必須假設小於控制迴路的採樣周期T。控制迴路由時間驅動的感測器和控制器以及事件驅動的執行器構成。這種方法可以用於循環服務網路,在這種網路中,所有系統元件的連線是事先知道的。這種方法不僅能解決周期性時延問題,而且還能增加網路的利用率。
增益自適應補償方法
增益自適應方法利用增益的自適應調整來補償網路控制中服務品質QoS( Quality of Service) 的變化,通過監測網路QoS,再根據給定的網路QoS 自調整控制器參數,以提供最好的控制性能,克服了擾動方法存在的不足。此方法中採用兩個服務品質QoS 量來定義終端—終端用戶的服務品質: 第一個代表點對點的網路容量QoS1,表明信號打包後通過網路採樣或傳送的速度; 第二個代表最大包點對點的最大時延QoS2,表明一個包從中央控制器傳送到遠程控制器所需時間。增益自適應方法有效解決了延時控制系統的不確定性時延問題,並在快速回響的運動延時控制系統中驗證了有效性,較以往的控制策略具更廣的適用範圍,但控制器參數的自適應調整力度有限,不適用於長時延網路延時控制系統。
