
簡介
信息以統一的形式集成在一起的好處是方便檢查和比較。例如比較不同的招聘和商品信息。還有一個好處是能對數據作自動化處理。例如用數據挖掘方法發現和解釋數據模型。信息抽取技術並不試圖全面理解整篇文檔,只是對文檔中包含相關信息的部分進行分析。至於哪些信息是相關的,那將由系統設計時定下的領域範圍而定。
 信息抽取
信息抽取技術
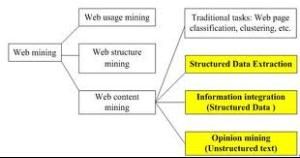
信息抽取技術對於從大量的文檔中抽取需要的特定事實來說是非常有用的。網際網路上就存在著這么一個文檔庫。在網上,同一主題的信息通常分散存放在不同網站上,表現的形式也各不相同。若能將這些信息收集在一起,用結構化形式儲存,那將是有益的。由於網上的信息載體主要是文本,所以,信息抽取技術對於那些把網際網路當成是知識來源的人來說是至關重要的。信息抽取系統可以看作是把信息從不同文檔中轉換成資料庫記錄的系統。因此,成功的信息抽取系統將把網際網路變成巨大的資料庫!結構化數據抽取(StructuredDataExtraction)的目標是從Web頁面中抽取結構化數據。這些結構化數據往往存儲在後台資料庫中,由網頁按一定格式承載著展示給用戶。例如論壇列表頁面、Blog頁面、搜尋引擎結果頁面等。
信息集成(Informationintegration)是針對結構化數據而言的。其目標是將從不同網站中抽取出的數據統一化後集成入庫。其關鍵問題是如何從不同網站的數據表中識別出意義相同的數據並統一存儲。
觀點挖掘(Opinionmining)是針對網頁中的純文本而言的。其目標是從網頁中抽取出帶有主觀傾向的信息。
工具
傳統的網路數據抽取是針對抽取對象手工編寫一段專門的抽取程式,這個程式稱為包裝器(wrapper)。近年來,越來越多的網路數據抽取工具被開發出來,替代了傳統的手工編寫包裝器的方法。目前的網路數據抽取工具可分為以下幾大類(實際上,一個工具可能會歸屬於其中若干類):開發包裝器的專用語言(LanguagesforWrapperDevelopment):用戶可用這些專用語言方便地編寫包裝器。例如Minerva,TSIMMIS,Web-OQL,florid,Jedi等。
 工具1
工具1以HTML為中間件的工具(HTML-awareTools):這些工具在抽取時主要依賴HTML文檔的內在結構特徵。在抽取過程之前,這些工具先把文檔轉換成標籤樹;再根據標籤樹自動或半自動地抽取數據。代表工具有Knowlesys,MDR。
基於NLP(Naturallanguageprocessing)的工具(NLP-basedTools):這些工具通常利用filtering、part-of-speechtagging、lexicalsemantictagging等NLP技術建立短語和句子元素之間的關係,推導出抽取規則。這些工具比較適合於抽取那些包含符合文法的頁面。代表工具有RAPIER,SRV,whisk。
包裝器的歸納工具(WrapperInductionTools):包裝器的歸納工具從一組訓練樣例中歸納出基於分隔設定的抽取規則。這些工具和基於NLP的工具之間最大的差別在於:這些工具不依賴於語言約束,而是依賴於數據的格式化特徵。這個特點決定了這些工具比基於NLP的工具更適合於抽取HTML文檔。代表工具有:WIEN,SoftMealy,STALKER。
 工具2
工具2基於模型的工具(Modeling-basedTools):這些工具讓用戶通過圖形界面,建立文檔中其感興趣的對象的結構模型,“教”工具學會如何識別文檔中的對象,從而抽取出對象。代表工具有:NoDoSE,DEByE。
基於本體的工具(Ontology-basedTools):這些工具首先需要專家參與,人工建立某領域的知識庫,然後工具基於知識庫去做抽取操作。如果知識庫具有足夠的表達能力,那么抽取操作可以做到完全自動。而且由這些工具生成的包裝器具有比較好的靈活性和適應性。代表工具有:BYU,X-tract。
流程
其具體步驟如下(以最通用的‘Knowlesys採集’步驟為例)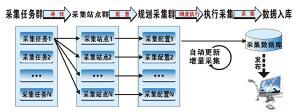 流程
流程第二步:提取特徵信息,即根據目標網站的網頁格式,提取出採集目標數據的通性。
第三步:網路信息獲取,即利用工具自動的把頁面數據把存到資料庫。
挑戰
信息抽取技術是近十年來發展起來的新領域,遇到許多新的挑戰。 信息抽取原來的目標是從自然語言文檔中找到特定的信息,是自然語言處理領域特別有用的一個子領域。所開發的信息抽取系統既能處理含有表格信息的結構化文本,又能處理自由式文本(如新聞報導)。IE系統中的關鍵組成部分是一系列的抽取規則或模式,其作用是確定需要抽取的信息。網上文本信息的大量增加導致這方面的研究得到高度重視。IR和IE的區別
IR的目的是根用戶的查詢請求從文檔庫中找出相關的文檔。用戶必須從找到的文檔中翻閱自己所要的信息。、就其目的而言,IR和IE的不同可表達如下:IR從文檔庫中檢索相關的文檔,而IE是從文檔中取出相關信息點。這兩種技術因此是互補的。若結合起來可以為文本處理提供強大的工具。
IR和IE不單在目的上不同,而且使用的技術路線也不同。部分原因是因為其目的差異,另外還因為它們的發展歷史不同。多數IE的研究是從以規則為基礎的計算語言學和自然語言處理技術發源的。而IR則更多地受到信息理論、機率理論和統計學的影響。
IE的歷史
自動信息檢索已是一個成熟的學科,其歷史與文檔資料庫的歷史一樣長。但自動信息抽取技術則是近十年來發展起來的。有兩個因素對其發展有重要的影響:一是線上和離線文本數量的幾何級增加,另一是“訊息理解研討會”(MUC)近十幾年來對該領域的關注和推動。 IE的前身是文本理解。人工智慧研究者一直致力於建造能把握整篇文檔的精確內容的系統。這些系統通常只在很窄的知識領域範圍內運行良好,向其他新領域移植的性能卻很差。
八十年代以來,美國政府一直支持MUC對信息抽取技術進行評測。各屆MUC吸引了許多來自不同學術機構和業界實驗室的研究者參加信息抽取系統競賽。每個參加單位根據預定的知識領域,開發一個信息抽取系統,然後用該系統處理相同的文檔庫。最後用一個官方的評分系統對結果進行打分。
研討會的目的是探求IE系統的量化評價體系。在此之前,評價這些系統的方法沒有章法可循,測試也通常在訓練集上進行。MUC首次進行了大規模的自然語言處理系統的評測。如何評價信息抽取系統由此變成重要的問題,評分標準也隨之制定出來。各屆研討會的測試主題各式各樣,包括拉丁美洲恐怖主義活動、合資企業、微電子技術和公司管理層的人事更迭。
過去五、六年,IE研究成果豐碩。英語和日語姓名識別的成功率達到了人類專家的水平。通過 MUC用現有的技術水平,我們已有能力建造全自動的 IE系統。在有些任務方面的性能達到人類專家的水平[53]。不過自1993年以來,每屆最高組別的有些任務,其成績一直沒有提高(但要記住MUC的任務一屆比一屆複雜)。一個顯著的進步是,越來越多的機構可以完成最高組別的任務。這要歸公於技術的普及和整合。目前,建造能達到如此高水平的系統需要大量的時間和專業人員。另外,目前大部分的研究都是圍繞書面文本,而且只有英語和其他幾種主要的語言。
