![Gan[生成式對抗網路]](/img/1/cc5/nBnauM3X3YDO5gTO5YjN1ATN0UTMyITNykTO0EDMwAjMwUzL2YzLxczLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg "Gan[生成式對抗網路]")
發展歷史
Ian J. Goodfellow等人於2014年10月在Generative Adversarial Networks中提出了一個通過對抗過程估計生成模型的新框架。框架中同時訓練兩個模型:捕獲數據分布的生成模型G,和估計樣本來自訓練數據的機率的判別模型D。G的訓練程式是將D錯誤的機率最大化。這個框架對應一個最大值集下限的雙方對抗遊戲。可以證明在任意函式G和D的空間中,存在唯一的解決方案,使得G重現訓練數據分布,而D=0.5。在G和D由多層感知器定義的情況下,整個系統可以用反向傳播進行訓練。在訓練或生成樣本期間,不需要任何馬爾科夫鏈或展開的近似推理網路。實驗通過對生成的樣品的定性和定量評估證明了本框架的潛力。
方法
機器學習的模型可大體分為兩類,生成模型(Generative Model)和判別模型(Discriminative Model)。判別模型需要輸入變數 ,通過某種模型來預測 。生成模型是給定某種隱含信息,來隨機產生觀測數據。舉個簡單的例子,
•判別模型:給定一張圖,判斷這張圖裡的動物是貓還是狗
•生成模型:給一系列貓的圖片,生成一張新的貓咪(不在數據集裡)
對於判別模型,損失函式是容易定義的,因為輸出的目標相對簡單。但對於生成模型,損失函式的定義就不是那么容易。我們對於生成結果的期望,往往是一個曖昧不清,難以數學公理化定義的範式。所以不妨把生成模型的回饋部分,交給判別模型處理。這就是Goodfellow他將機器學習中的兩大類模型, Generative和 Discrimitive給緊密地聯合在了一起。
GAN的基本原理其實非常簡單,這裡以生成圖片為例進行說明。假設我們有兩個網路,G(Generator)和D(Discriminator)。正如它的名字所暗示的那樣,它們的功能分別是:
•G是一個生成圖片的網路,它接收一個隨機的噪聲z,通過這個噪聲生成圖片,記做G(z)。
•D是一個判別網路,判別一張圖片是不是“真實的”。它的輸入參數是x,x代表一張圖片,輸出D(x)代表x為真實圖片的機率,如果為1,就代表100%是真實的圖片,而輸出為0,就代表不可能是真實的圖片。
在訓練過程中,生成網路G的目標就是儘量生成真實的圖片去欺騙判別網路D。而D的目標就是儘量把G生成的圖片和真實的圖片分別開來。這樣,G和D構成了一個動態的“博弈過程”。
最後博弈的結果是什麼?在最理想的狀態下,G可以生成足以“以假亂真”的圖片G(z)。對於D來說,它難以判定G生成的圖片究竟是不是真實的,因此D(G(z)) = 0.5。
這樣我們的目的就達成了:我們得到了一個生成式的模型G,它可以用來生成圖片。
Goodfellow從理論上證明了該算法的收斂性,以及在模型收斂時,生成數據具有和真實數據相同的分布(保證了模型效果)。
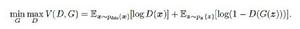 GAN公式
GAN公式公式中x表示真實圖片,z表示輸入G網路的噪聲,G(z)表示G網路生成的圖片,D(·)表示D網路判斷圖片是否真實的機率。
套用
圖像生成
![Gan[生成式對抗網路]](/img/d/74f/nBnauM3X2YjNzQDO5UTM1kTM2UTM1QDN5MjM5ADMwAjMwUzL1EzL2YzLt92YucmbvRWdo5Cd0FmLyE2LvoDc0RHa.jpg) Gan[生成式對抗網路]
Gan[生成式對抗網路]目前GAN最常使用的地方就是圖像生成,如超解析度任務,語義分割等等。
數據增強
用GAN生成的圖像來做數據增強,如圖。主要解決的問題是
對於小數據集,數據量不足, 如果能生成一些就好了。
如果GAN生成了圖片?怎么給這些數據label呢?因為他們相比原始數據也不屬於預定義的類別。
1.對於小數據集,數據量不足, 如果能生成一些就好了。
2.如果GAN生成了圖片?怎么給這些數據label呢?因為他們相比原始數據也不屬於預定義的類別。
![Gan[生成式對抗網路]](/img/0/2cb/nBnauM3XxYDM4cjN5UTM1kTM2UTM1QDN5MjM5ADMwAjMwUzL1EzLzgzLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg) Gan[生成式對抗網路]
Gan[生成式對抗網路]在中,都做了一些嘗試。實驗想法也特別簡單,先用原始數據(即使只有2000張圖)訓練一個GAN,然後生成圖片,加入到訓練集中。 總結一下就是:
GAN 生成數據是可以用在實際的圖像問題上的(不僅僅是像mnist 這種toy dataset上work)作者在兩個行人重識別數據集 和 一個細粒度識別 鳥識別數據集上都有提升。
GAN 數據有三種給pseudo label的方式, 假設我們做五分類
1.GAN 生成數據是可以用在實際的圖像問題上的(不僅僅是像mnist 這種toy dataset上work)作者在兩個行人重識別數據集 和 一個細粒度識別 鳥識別數據集上都有提升。
2.GAN 數據有三種給pseudo label的方式, 假設我們做五分類
•把生成的數據都當成新的一類, 六分類,那么生成圖像的 label 就可以是 (0, 0, 0, 0, 0, 1) 這樣給。
•按照置信度最高的 動態去分配,那個機率高就給誰 比如第三類機率高(0, 0, 1, 0, 0)
•既然所有類都不是,那么可以參考inceptionv3,搞label smooth,每一類置信度相同(0.2, 0.2, 0.2, 0.2, 0.2) 註:作者16年12月寫的代碼,當時GAN效果沒有那么好,用這個效果好也是可能的, 因為生成樣本都不是很“真”,所以起到了正則作用。
