
業務價值
1)海量數據存儲:完全分散式架構,可以按需橫向擴展,輕鬆實現PB級別數據管理;數據線上彈性擴展,無需終端業務,保證企業7x24連續運營,數據永遠線上;生產環境實測支持超過1000個節點集群。
2)高並發數據查詢讀寫:分散式架構與高性能數據引擎,支持海量數據高並發讀寫,各業務套用可隨需使用,實時快速回響。PB級別數據毫秒查詢回響。
3)多模數據管理:靈活的數據存儲類型,支持非結構化、結構化和半結構化數據全覆蓋,實現多模(Multi-Model)數據統一管理。
4)高可用與災備雙活:分散式下數據多副本保證數據高可用,在異地災備基礎上,巨杉資料庫已經實現同城“雙活”,滿足“兩地三中心”的要求,極大提升數據安全。
5)HTAP混合事務/分析處理模式:巨杉資料庫通過SQL的完全支持以及Spark的整合,實現HTAP混合事務、分析處理,快速實現業務套用的彈性開發。
6)高效運維、運營最佳化:多模數據管理,數據自動切分,彈性架構擴容和兼容性,幫助有效提升運維效率,最佳化數據運營方法。
原廠專業技術支持服務:作為第一家真正的原廠分散式資料庫公司,巨杉的團隊提供了原始碼級別的原廠技術支持服務,幫助用戶更好使用,保證系統持續線上與性能穩定高效。
分散式架構
SequoiaDB使用分散式架構。
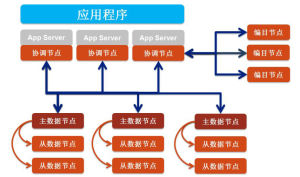 SequoiaDB巨杉資料庫架構圖
SequoiaDB巨杉資料庫架構圖SequoiaDB的整體架構圖如圖所示。
1)協調節點:負責調度、分配、匯總,是SequoiaDB的數據分發節點,本身不存儲任何數據,主要負責接收應用程式的訪問請求;
2)編目節點:負責存儲整個資料庫的部署結構與節點狀態信息,並且記錄集合空間與集合的參數信息,同時記錄每個集合的數據切分狀況;
3)數據節點:承載數據存儲、計算的進程,為用戶提供高性能的讀寫服務,並且在多索引的支持下針對海量數據查詢性能優越。多個數據節點可以組成一個數據節點組,採取一主多備結構。
標準SQL支持
SequoiaDB巨杉資料庫,作為企業級分散式資料庫,目前全面支持標準SQL,提供高性能的SQL引擎組件。SequoiaDB目前支持標準SQL的訪問,包含了標準SQL2003引擎、深度數據壓縮等多項全新功能,在100%支持和兼容原有JSON特性的基礎上,提供了標準SQL2003的語法支持,能夠兼容傳統套用大大降低遷移成本,做到學習成本最小化,並最大程度滿足傳統套用開發人員對於資料庫SQL訪問方式的需求。
版本發布
2013年02月20日,SequoiaDBV1.0產品開發完成並發布,該版本採用全新分散式架構。
2013年04月06日,SequoiaDBV1.3發布,該版本完善了分散式特性,支持節點間數據複製、可配置的一致性級別與跨節點跨集合的事務功能,並可與Hadoop進行對接。
2013年10月23日,SequoiaDBV1.5發布,此版本包括了一些性能最佳化,功能增強以及bug修復。
2014年03月14日,SequoiaDBV1.6發布,此版本包括了新版圖形化管理界面與一些功能性修復,且能夠與Storm進行對接。
2014年07月04日,SequoiaDBV1.8發布 ,此版本包括了邏輯域的概念,與PostgreSQL對接並有大幅度性能提升,能夠與Spark進行對接,也是目前最新的穩定版。
2015年3月發布SequoiaDBv1.12
