
技術特點
SequoiaDB資料庫,提供了基於PC伺服器的大規模集群數據平台,為IT部門在提供穩定,可靠以及高效數據服務的同時,大大降低IT部門應用程式的開發,部署以及維護成本。
SequoiaDB資料庫的主要特點:
1)通過非結構化存儲與分散式處理,提供了近線性的水平擴張能力,讓底層的存儲不再成為瓶頸。
2)提供了完善的企業級功能,讓用戶輕鬆管理高並發性任務,以及海量數據分析。
3)增強的非關係型數據模型,幫助企業快速開發和部署應用程式,做到應用程式的隨需應變。
4)提供了最終一致性與強一致性的雙重機制,從根本上杜絕數據缺失。
5)提供了線上套用與大數據分析的後台資料庫的結合,通過讀寫分離機製做到同系統中數據分析與線上業務互不干擾。
6)提供了精確到分區級別的高可用性,預防伺服器,機房故障以及人為錯誤,讓數據24x7永遠線上。
功能特性
1)SequoiaDB為所有受歡迎的程式語言提供了原生驅動程式,為營造自然的開發環境而提供了框架。支持的驅動程式包括C、C++、Java、.NET、PHP、Python等。
2)SequoiaDB命令行是一個互動式的JavaScript執行環境,幾乎所有SequoiaDB支持的命令都通過命令行執行
3)SequoiaDB提供了與PostgreSQL關係型資料庫連線的外部表驅動,使用戶可以通過標準SQL訪問SequoiaDB。
4)SequoiaDB支持很多類型的查詢。包括了鍵值對查詢、範圍查詢和聚合框架查詢。此外,SequoiaDB還配備了查詢最佳化器,自動最佳化查詢。
5)SequoiaDB包括文檔中任何欄位多種類型的索引,包括唯一索引、複合索引以數組索引。
資料庫架構
SequoiaDB使用分散式架構,下圖提供了對SequoiaDB體系結構的一般概述。
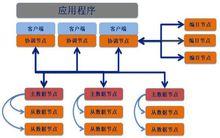 SequoiaDB系統架構圖
SequoiaDB系統架構圖在客戶機端(或應用程式端),本地或/和遠程應用程式都與SequoiaDB客戶機庫連結。協調節點不保存任何用戶數據,僅作為請求分發節點將用戶請求分發至相應的數據節點。
編目節點保存系統的元數據信息,協調節點通過與編目節點通訊從而了解數據在數據節點中的實際分布。數據節點保存用戶的數據信息。一個或多個數據節點構成一個數據分片(Shard),不同的分片中保存的數據無重複。當存在多個數據節點時,節點間數據進行異步複製。分片中可以存在最多一個主節點與若干從節點。其中主節點可以進行讀寫操作,從節點進行唯讀操作。從節點離線不影響主節點的正常工作。主節點離線後會在從節點中自動選舉出新的主節點處理寫請求。節點恢復後,或新的節點加入分片後會進行自動同步,保障數據在同步完成時與主節點一致。
大數據架構的集成
SequoiaDB巨杉資料庫與Hadoop/Spark均有深度集成,可以作為分析架構的底層存儲使用,保證了系統既可以進行實時查詢、又可以通過讀寫分離機制,實現數據的離線分析 。
版本發布
2013年02月20日,SequoiaDBV1.0產品開發完成並發布,該版本採用全新分散式架構。
2013年04月06日,SequoiaDBV1.3發布,該版本完善了分散式特性,支持節點間數據複製、可配置的一致性級別與跨節點跨集合的事務功能,並可與Hadoop進行對接。
2013年10月23日,SequoiaDBV1.5發布,此版本包括了一些性能最佳化,功能增強以及bug修復。
2014年03月14日,SequoiaDBV1.6發布,此版本包括了新版圖形化管理界面與一些功能性修復,且能夠與Storm進行對接。
2014年07月04日,SequoiaDBV1.8發布,此版本包括了邏輯域的概念,與PostgreSQL對接並有大幅度性能提升,能夠與Spark進行對接。
2014年11月,SequoiaDB V1.10發布,此版本增加了LOB大對象功能,自動化安裝功能以及python驅動等。
2014年12月19日,文檔型 NoSQL 資料庫 SequoiaDB 宣布開源 。
2015年3月發布 SequoiaDB V1.12 穩定版本
2016年,發布SequoiaDB V2.0穩定版本。
2016年下半年,SequoiaDB V2.8.4穩定版推出 。
