
簡介
 在線上分析處理
在線上分析處理 在線上分析處理是共享多維信息的、針對特定問題的在線上數據訪問和分析的快速軟體技術。它通過對信息的多種可能的觀察形式進行快速、穩定一致和互動性的存取,允許管理決策人員對數據進行深入觀察。決策數據是多維數據,多維數據就是決策的主要內容。 OLAP專門設計用於支持複雜的分析操作,側重對決策人員和高層管理人員的決策支持,可以根據分析人員的要求快速、靈活地進行大數據量的複雜查詢處理,並且以一種直觀而易懂的形式將查詢結果提供給決策人員,以便他們準確掌握企業( 公司)的經營狀況,了解對象的需求,制定正確的方案。
在線上分析處理具有靈活的分析功能、直觀的數據操作和分析結果可視化表示等突出優點,從而使用戶對基於大量複雜數據的分析變得輕鬆而高效,以利於迅速做出正確判斷。它可用於證實人們提出的複雜的假設,其結果是以圖形或者表格的形式來表示的對信息的總結。它並不將異常信息標記出來,是一種知識證實的方法。
由來
 在線上分析處理
在線上分析處理 當今的數據處理大致可以分成兩大類:在線上事務處理OLTP(on-line transaction processing)、在線上分析處理OLAP(On-Line Analytical Processing)。OLTP是傳統的關係型資料庫的主要套用,主要是基本的、日常的事務處理,例如銀行交易。OLAP是數據倉庫系統的主要套用,支持複雜的分析操作,側重決策支持,並且提供直觀易懂的查詢結果。下表列出了OLTP與OLAP之間的比較。
發展背景
隨著資料庫技術的廣泛套用,企業信息系統產生了大量的數據,如何從這些海量數據中提取對企業決策分析有用的信息成為企業決策管理人員所面臨的重要難題。傳統的企業資料庫系統(管理信息系統)即在線上事務處理系統(On-LineTransactionProcessing,簡稱OLTP)作為數據管理手段,主要用於事務處理,但它對分析處理的支持一直不能令人滿意。因此,人們逐漸嘗試對OLTP資料庫中的數據進行再加工,形成一個綜合的、面向分析的、更好的支持決策制定的決策支持系統(DecisionSupportSystem,簡稱DSS)。企業目前的信息系統的數據一般由DBMS管理,但決策資料庫和運行運算元據庫在數據來源、數據內容、數據模式、服務對象、訪問方式、事務管理乃至無力存儲等方面都有不同的特點和要求,因此直接在運行操作的資料庫上建立DSS是不合適的。數據倉庫(DataWarehouse)技術就是在這樣的背景下發展起來的。數據倉庫的概念提出於20世紀80年代中期,20世紀90年代,數據倉庫已從早起的探索階段走向實用階段。業界公認的數據倉庫概念創始人W.H.Inmon在《BuildingtheDataWarehouse》一書中對數據倉庫的定義是:“數據倉庫是支持管理決策過程的、面向主題的、集成的、隨時間變化的持久的數據集合”。構建數據倉庫的過程就是根據預先設計好的邏輯模式從分布在企業內部各處的OLTP資料庫中提取數據並對經過必要的變換最終形成全企業統一模式數據的過程。當前數據倉庫的核心仍是RDBMS管理下的一個資料庫系統。數據倉庫中數據量巨大,為了提高性能,RDBMS一般也採取一些提高效率的措施:採用並行處理結構、新的數據組織、查詢策略、索引技術等等。
包括在線上分析處理(On-LineAnalyticalProcessing,簡稱OLAP)在內的諸多套用牽引驅動了數據倉庫技術的出現和發展;而數據倉庫技術反過來又促進了OLAP技術的發展。在線上分析處理的概念最早由關係資料庫之父E.F.Codd於1993年提出的。Codd認為在線上事務處理(OLTP)已不能滿足終端用戶對資料庫查詢分析的要求,SQL對大資料庫的簡單查詢也不能滿足用戶分析的需求。用戶的決策分析需要對關係資料庫進行大量計算才能得到結果,而查詢的結果並不能滿足決策者提出的需求。因此,Codd提出了多維資料庫和多維分析的概念,即OLAP。OLAP委員會對在線上分析處理的定義為:使分析人員、管理人員或執行人員能夠從多種角度對從原始數據中轉化出來的、能夠真正為用戶所理解的、並真實反映企業維特性的信息進行快速、一致、互動地存取,從而獲得對數據的更深入了解的一類軟體技術。OLAP的目標是滿足決策支持或多維環境特定的查詢和報表需求,它的技術核心是“維”這個概念,因此OLAP也可以說是多維數據分析工具的集合。
處理特點
 在線上分析處理
在線上分析處理 在線上分析處理的用戶是企業中的專業分析人員及管理決策人員,他們在分析業務經營的數據時,從不同的角度來審視業務的衡量指標是一種很自然的思考模式。例如分析銷售數據,可能會綜合時間周期、產品類別、分銷渠道、地理分布、客戶群類等多種因素來考量。這些分析角度雖然可以通過報表來反映,但每一個分析的角度可以生成一張報表,各個分析角度的不同組合又可以生成不同的報表,使得IT人員的工作量相當大,而且往往難以跟上管理決策人員思考的步伐。
在線上分析處理的主要特點,是直接仿照用戶的多角度思考模式,預先為用戶組建多維的數據模型,在這裡,維指的是用戶的分析角度。例如對銷售數據的分析,時間周期是一個維度,產品類別、分銷渠道、地理分布、客戶群類也分別是一個維度。一旦多維數據模型建立完成,用戶可以快速地從各個分析角度獲取數據,也能動態的在各個角度之間切換或者進行多角度綜合分析,具有極大的分析靈活性。這也是在線上分析處理在近年來被廣泛關注的根本原因,它從設計理念和真正實現上都與舊有的管理信息系統有著本質的區別。
事實上,隨著數據倉庫理論的發展,數據倉庫系統已逐步成為新型的決策管理信息系統的解決方案。數據倉庫系統的核心是在線上分析處理,但數據倉庫包括更為廣泛的內容。概括來說,數據倉庫系統是指具有綜合企業數據的能力,能夠對大量企業數據進行快速和準確分析,輔助做出更好的商業決策的系統。它本身包括三部分內容:
數據層。實現對企業運算元據的抽取、轉換、清洗和匯總,形成信息數據,並存儲在企業級的中心信息資料庫中。
套用層。通過在線上分析處理,甚至是數據挖掘等套用處理,實現對信息數據的分析。
表現層。通過前台分析工具,將查詢報表、統計分析、多維在線上分析和數據發掘的結論展現在用戶面前。
從套用角度來說,數據倉庫系統除了在線上分析處理外,還可以採用傳統的報表,或者採用數理統計和人工智慧等數據挖掘手段,涵蓋的範圍更廣;就套用範圍而言,在線上分析處理往往根據用戶分析的主題進行套用分割,例如:銷售分析、市場推廣分析、客戶利潤率分析等等,每一個分析的主題形成一個OLAP套用,而所有的OLAP套用實際上只是數據倉庫系統的一部分。
典型操作
OLAP展現在用戶面前的是一幅幅多維視圖。
維(Dimension):是人們觀察數據的特定角度,是考慮問題時的一類屬性,屬性集合構成一個維(時間維、地理維等)。維的層次(Level):人們觀察數據的某個特定角度(即某個維)還可以存在細節程度不同的各個描述方面(時間維:日期、月份、季度、年)。維的成員(Member):維的一個取值,是數據項在某維中位置的描述。(“某年某月某日”是在時間維上位置的描述)。
度量(Measure):多維數組的取值。(2000年1月,上海,筆記本電腦,0000)。OLAP的基本多維分析操作有鑽取(Drill-up和Drill-down)、切片(Slice)和切塊(Dice)、以及鏇轉(Pivot)等。
鑽取:是改變維的層次,變換分析的粒度。它包括向下鑽取(Drill-down)和向上鑽取(Drill-up)/上卷(Roll-up)。Drill-up是在某一維上將低層次的細節數據概括到高層次的匯總數據,或者減少維數;而Drill-down則相反,它從匯總數據深入到細節數據進行觀察或增加新維。
切片和切塊:是在一部分維上選定值後,關心度量數據在剩餘維上的分布。如果剩餘的維只有兩個,則是切片;如果有三個或以上,則是切塊。 鏇轉:是變換維的方向,即在表格中重新安排維的放置(例如行列互換)。
體系結構
 在線上分析處理
在線上分析處理 OLAP系統按照其存儲器的數據存儲格式可以分為 關係OLAP(RelationalOLAP,簡稱ROLAP)、多維OLAP(MultidimensionalOLAP,簡稱MOLAP)和混合型OLAP(HybridOLAP,簡稱HOLAP)三種類型。
1.ROLAP
ROLAP將分析用的多維數據存儲在關係資料庫中並根據套用的需要有選擇的定義一批實視圖作為表也存儲在關係資料庫中。不必要將每一個SQL查詢都作為實視圖保存,只定義那些套用頻率比較高、計算工作量比較大的查詢作為實視圖。對每個針對OLAP伺服器的查詢,優先利用已經計算好的實視圖來生成查詢結果以提高查詢效率。同時用作ROLAP存儲器的RDBMS也針對OLAP作相應的最佳化,比如並行存儲、並行查詢、並行數據管理、基於成本的查詢最佳化、點陣圖索引、SQL的OLAP擴展(cube,rollup)等等。
2.MOLAP
MOLAP將OLAP分析所用到的多維數據物理上存儲為多維數組的形式,形成“立方體”的結構。維的屬性值被映射成多維數組的下標值或下標的範圍,而總結數據作為多維數組的值存儲在數組的單元中。由於MOLAP採用了新的存儲結構,從物理層實現起,因此又稱為物理OLAP(PhysicalOLAP);而ROLAP主要通過一些軟體工具或中間軟體實現,物理層仍採用關係資料庫的存儲結構,因此稱為虛擬OLAP(VirtualOLAP)。
3.HOLAP
由於MOLAP和ROLAP有著各自的優點和缺點(如下表所示),且它們的結構迥然不同,這給分析人員設計OLAP結構提出了難題。為此一個新的OLAP結構——混合型OLAP(HOLAP)被提出,它能把MOLAP和ROLAP兩種結構的優點結合起來。迄今為止,對HOLAP還沒有一個正式的定義。但很明顯,HOLAP結構不應該是MOLAP與ROLAP結構的簡單組合,而是這兩種結構技術優點的有機結合,能滿足用戶各種複雜的分析請求。
實現方式
同樣是仿照用戶的多角度思考模式,在線上分析處理有三種不同的實現方法:關係型在線上分析處理(ROLAP,Relational OLAP);多維在線上分析處理(MOLAP,Multi-Dimensional OLAP);前端展示在線上分析處理(Desktop OLAP)。
其中,前端展示在線上分析需要將所有數據下載到客戶機上,然後在客戶機上進行數據結構/報表格式重組,使用戶能在本機實現動態分析。該方式比較靈活,然而它能夠支持的數據量非常有限,嚴重地影響了使用的範圍和效率。因此,隨著時間的推移,這種方式已退居次要地位,在此不作討論。 以下就ROLAP和MOLAP的具體實施方法進行討論,關係型在線上分析處理的具體實施方法:
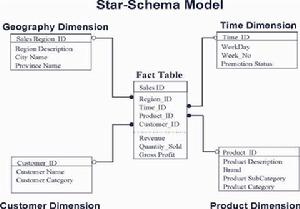
顧名思義,關係型在線上分析處理是以關係型資料庫為基礎的。唯一特別之處在於在線上分析處理中的數據結構組織的方式。讓我們考察一個例子,假設我們要進行產品銷售的財務分析,分析的角度包括時間、產品類別、市場分布、實際發生與預算四方面內容,分析的財務指標包括:銷售額、銷售支出、毛利(=銷售額-銷售支出)、費用、純利(=毛利-費用)等內容,則我們可以建立如下的數據結構:
該數據結構的中心是主表,裡面包含了所有分析維度的外鍵,以及所有的財務指標,可計算推導的財務指標不計在內,我們稱之為事實表(Fact Table)。周圍的表分別是對應於各個分析角度的維表(Dimension Table),每個維表除了主鍵以外,還包含了描述和分類信息。無論原來的業務數據的數據結構為何,只要原業務數據能夠整理成為以上模式,則無論業務人員據此提出任何問題,都可以用SQL語句進行表連線或匯總(table join and group by)實現數據查詢和解答。(當然,有一些現成的ROLAP前端分析工具是可以自動根據以上模型生成SQL語句的)。這種模式被稱為星型模式(Star-Schema),可套用於不同的在線上分析處理套用中。以下是另一個採用星型模式的例子,分析的角度和指標截然不同,但數據結構模式一樣。我們看到的不是表的數據,而是表的結構。在在線上分析處理的數據模型設計中,這種表達方式更為常見:
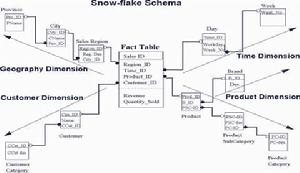
有時候,維表的定義會變得複雜,例如對產品維,既要按產品種類進行劃分,對某些特殊商品,又要另外進行品牌劃分,商品品牌和產品種類劃分方法並不一樣。因此,單張維表不是理想的解決方案,可以採用以下方式,這種數據模型實際上是星型結構的拓展,我們稱之為雪花型模式(snow-flake schema).
基本特點
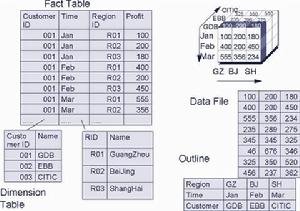 在線上分析處理
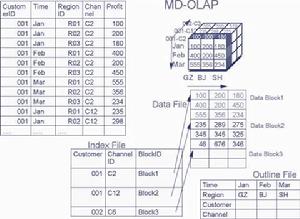
在線上分析處理 某些客戶只通過某些分銷渠道才購買,但是只要該客戶存在,他在各個月和各個地區內均有消費(例如,華南IBM只通過熊貓國旅定購南航機票,但在華南四省在每個月均有機票訂購)。則時間和地區維是密集維,客戶和分銷渠道是稀疏維,MOLAP將稀疏維建成索引檔案(Index File),密集維所對應的數值仍然保留在數據檔案中,索引檔案不存儲空紀錄。這樣保持了對空間的合理利用。我們也可以看到,如果所有維都是稀疏維,則MOLAP的索引檔案就退化成ROLAP的事實表, 兩者沒有區別了。
在實際套用中,不可能所有分析的維度都是密集的,也絕少存在所有分析的維度都是稀疏的,因此稀疏維和密集維並用的模式幾乎主導了所有的MOLAP套用。而稀疏維和密集維的定義全部集中在概要檔案中,因此,只要預先定義好概要檔案,所有的數據分布就自動確定了。在這種模式中,密集維的組合組成了的數據塊(Data Block),每個數據塊是I/O讀寫的基礎單位(如上圖),所有的數據塊組成了數據檔案。稀疏維的組合組成了索引檔案,索引檔案的每一個數據紀錄的末尾都帶有一個指針,指向要讀寫的數據塊。因此,進行數據查詢時,系統先搜尋索引檔案紀錄,然後直接調用指針指向的數據塊進行I/O讀寫(如果該數據塊尚未駐留記憶體),將相應數據塊調入記憶體後,根據密集維的數據放置順序直接計算出要查詢的數據距離數據塊頭的偏移量,直接提取數據下傳到客戶端。因此,MOLAP 方式基本上是索引搜尋與直接定址的查詢方式相結合,比起ROLAP的表/索引搜尋和表連線方式,速度要快得多。
