
簡介
 Heritrix 有Web 控制管理界面
Heritrix 有Web 控制管理界面它的執行是遞歸進行的,主要有以下幾步:
1。在預定的URI中選擇一個。
2。獲取URI
3。分析,歸檔結果
4。選擇已經發現的感興趣的URI。加入預定佇列。
5。標記已經處理過的URI
它是IA的開放原始碼,可擴展的,基於整個Web的,歸檔網路爬蟲工程
Heritrix工程始於2003年初,IA的目的是開發一個特殊的爬蟲,對網上的
資源進行歸檔,建立網路數字圖書館,在過去的6年裡,IA已經建立了400TB的數據。
最新版本:heritrix-3.1.0
IA期望他們的crawler包含以下幾種:
寬頻爬蟲:能夠以更高的頻寬去站點爬。
主題爬蟲:集中於被選擇的問題。
持續爬蟲:不僅僅爬更當前的網頁還負責爬日後更新的網頁。
實驗爬蟲:對爬蟲技術進行實驗,以決定該爬什麼,以及對不同協定的爬蟲 爬行結果進行分析的。
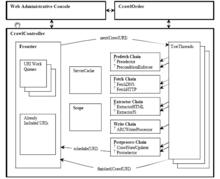
部件
主要部件
Heritrix主要有三大部件:範圍部件,邊界部件,處理器鏈
範圍部件:主要按照規則決定將哪個URI入隊。
邊界部件:跟蹤哪個預定的URI將被收集,和已經被收集的URI,選擇下一個 URI,剔除已經處理過的URI。
處理器鏈:包含若干處理器獲取URI,分析結果,將它們傳回給邊界部件
其餘部件
WEB管理控制台:大多數都是單機的WEB套用,內嵌JAVA HTTP 伺服器。
操作者可以通過選擇Crawler命令來操作控制台。
Crawler命令處理部件:包含足夠的信息創建要爬的URI。
Servercache(處理器快取):存放伺服器的持久信息,能夠被爬行部件隨時查到,包括IP位址,歷史記錄,機器人策略。
處理器鏈:
預取鏈:主要是做一些準備工作,例如,對處理進行延遲和重新處理,否決隨後的操作。
提取鏈:主要是獲得資源,進行DNS轉換,填寫請求和回響表單
抽取鏈:當提取完成時,抽取感興趣的HTML,JavaScript,通常那裡有新的也適合的URI,此時URI僅僅被發現,不會被評估
寫鏈:存儲爬行結果,返回內容和抽取特性,過濾完存儲。
提交鏈:做最後的維護,例如,測試那些不在範圍內的,提交給邊界部件
關鍵特性
Heritrix 1.0.0包含以下關鍵特性:
1.用單個爬蟲在多個獨立的站點一直不斷的進行遞歸的爬。
2.從一個提供的種子進行爬,收集站點內的精確URI,和精確主機。
3.主要是用廣度優先算法進行處理。
4.主要部件都是高效的可擴展的
5.良好的配置,包括:
a.可設定輸出日誌,歸檔檔案和臨時檔案的位置
b.可設定下載的最大位元組,最大數量的下載文檔,和最大的下載時間。
c.可設定工作執行緒數量。
d.可設定所利用的頻寬的上界。
e.可在設定之後一定時間重新選擇。
f.包含一些可設定的過濾機制,表達方式,URI路徑深度選擇等等。
Heritrix的局限:
1.單實例的爬蟲,之間不能進行合作。
2.在有限的機器資源的情況下,卻要複雜的操作。
3.只有官方支持,僅僅在Linux上進行了測試。
4.每個爬蟲是單獨進行工作的,沒有對更新進行修訂。
5.在硬體和系統失敗時,恢復能力很差。
