原理
圖1給出了D-AMPS系統7950bit/s的全速率VSELP語音編碼器原理方框圖。編碼器用了3個激勵源,最上面的是長期濾器狀態,第二、第三是兩個VSELP激勵碼本。
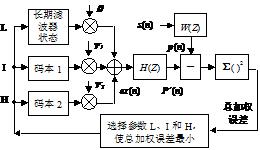 圖1 VSELP編碼器框圖
圖1 VSELP編碼器框圖20ms的語音幀被分成四個5ms的子幀,對於每個子幀,語音編碼器必須確定和編碼上述解碼器所需的參數:長期預測器L、兩個碼字I和H、增益β、γ1和γ2。在編碼器中,輸入語音必須通過感覺加權濾波器的濾波。而其合成濾波器,在每一子幀後,合成激勵源的ex(n)要修正長期預測器的狀態。接收端的解碼器也有相應的合成濾波器。但是編碼器的合成包括噪聲加權參數,因此稱為加權合成濾波器,用以匹配加權輸入語音。在所有的子幀參數已被確定和量化後,長期濾波器狀態和加權合成濾波器狀態必須被更改,為處理下一子幀作準備。短期濾波器與傳統的LPC合成濾波器相同,這裡採用的是10階全極點濾波器。LPC係數每20ms幀編碼一次,並在每5ms子幀中通過內插法修正。3個激勵矢量順序地挑選,每一步的碼本搜尋都是為了使誤差最小。
參數及計算
下面是VSELP語音編解碼器的基本參數:
抽樣速率(幀速率) 8kHz
幀長度NF 160樣點(20ms)
子幀長度N 40樣點(5ms)
短期預測器即LPC的階數NP 10
長期預測器抽頭數 l
碼字1的位數即基矢量數M1 7
碼字2的基矢量數M2 7
語音編碼器的基本比特率是7950bit/s。每語音幀(20ms)含159bit。
代表短期預測器參數的10個反射係數,即LPC係數是各自被量化的。
反映20ms期間輸入語音平均信號功率的能量值為R(0)。每一幀計算和編碼一次。三個激勵增益被矢量量化到每子幀8bit(GSP0)碼。159個bit的分配如下:
短期濾波器參數α 38bit/幀
幀能量R(0) 5bit/幀
滯後L 28bit/幀(7bit/子幀)
碼字I、H 56bit/幀(7+7bit/子幀)
增益β、γ1和γ2 32bit/幀(8bit/子幀)
VSELP編碼器使用兩個激勵碼本,各含2M碼矢量,這些碼矢量都由兩組M個基矢量構成,其中M=7。定義VK,m(n)為第K碼本的第m個基矢量;UK,i(n)為第K個碼本中第i個碼矢量。則:
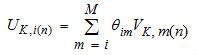 D-AMPS系統的語音編碼標準
D-AMPS系統的語音編碼標準式中:K=1指第1碼本;K=2指第2碼本;並且0≤i≤2M-1,0≤n≤N-1。
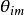 D-AMPS系統的語音編碼標準
D-AMPS系統的語音編碼標準碼本中每個碼矢量都是M個基矢量的線性組合。線性組合是由參數θ定義。 定義如下:
D-AMPS系統的語音編碼標準=+1表示i碼字的m位為1
D-AMPS系統的語音編碼標準=-1表示i碼字的m位為0
對碼字i的全部比特位取反,則相應碼矢量就是碼字i的負矢量。每個碼矢量的負矢量也在碼本中,這對碼矢量稱為互補碼矢量。
每個碼本有7個基矢量,含128個碼矢量,每個基矢量有40個抽樣樣本。
