
原理
轉碼過程例子:
3*8=4*6
記憶體1個位元組占8位
轉前: s 1 3
先轉成ascii:對應 115 49 51
2進制: 01110011 00110001 00110011
6個一組(4組) 011100110011 000100110011
然後才有後面的 011100 110011 000100 110011
然後計算機是8位8位的存數 6不夠,自動就補兩個高位0了
所有有了 高位補0
科學計算器輸入 00011100 00110011 00000100 00110011
得到 28 51 4 51
查對下照表 c z E z
先以“迅雷下載”為例: 很多下載類網站都提供“迅雷下載”的連結,其地址通常是加密的迅雷專用下載地址。
其實迅雷的“專用地址”也是用Base64"加密"的,其過程如下:
一、在地址的前後分別添加AA和ZZ
二、對新的字元串進行Base64編碼
另: Flashget的與迅雷類似,只不過在第一步時加的“料”不同罷了,Flashget在地址前後加的“料”是[FLASHGET]
而QQ鏇風的乾脆不加料,直接就對地址進行Base64編碼了
套用
Base64編碼可用於在HTTP環境下傳遞較長的標識信息。例如,在Java Persistence系統Hibernate中,就採用了Base64來將一個較長的唯一標識符(一般為128-bit的UUID)編碼為一個字元串,用作HTTP表單和HTTP GET URL中的參數。在其他應用程式中,也常常需要把二進制數據編碼為適合放在URL(包括隱藏表單域)中的形式。此時,採用Base64編碼不僅比較簡短,同時也具有不可讀性,即所編碼的數據不會被人用肉眼所直接看到。
然而,標準的Base64並不適合直接放在URL里傳輸,因為URL編碼器會把標準Base64中的“/”和“+”字元變為形如“%XX”的形式,而這些“%”號在存入資料庫時還需要再進行轉換,因為ANSI SQL中已將“%”號用作通配符。
為解決此問題,可採用一種用於URL的改進Base64編碼,它不僅在末尾去掉填充的'="號,並將標準Base64中的“+”和“/”分別改成了“-”和“_”,這樣就免去了在URL編解碼和資料庫存儲時所要作的轉換,避免了編碼信息長度在此過程中的增加,並統一了資料庫、表單等處對象標識符的格式。
另有一種用於正則表達式的改進Base64變種,它將“+”和“/”改成了“!”和“-”,因為“+”,“/”以及前面在IRCu中用到的“[”和“]”在正則表達式中都可能具有特殊含義。
此外還有一些變種,它們將“+/”改為“_-”或“._”(用作程式語言中的標識符名稱)或“.-”(用於XML中的Nmtoken)甚至“_:”(用於XML中的Name)。
其他套用
Mozilla Thunderbird和Evolution用Base64來保密電子郵件密碼
Base64 也會經常用作一個簡單的“加密”來保護某些數據,而真正的加密通常都比較繁瑣。
垃圾訊息傳播者用Base64來避過反垃圾郵件工具,因為那些工具通常都不會翻譯Base64的訊息。
在LDIF檔案,Base64用作編碼字串。
簡介
標準的Base64並不適合直接放在URL里傳輸,因為URL編碼器會把標準Base64中的“/”和“+”字元變為形如“%XX”的形式,而這些“%”號在存入資料庫時還需要再進行轉換,因為ANSI SQL中已將“%”號用作通配符。
為解決此問題,可採用一種用於URL的改進Base64編碼,它在末尾填充"="號,並將標準Base64中的“+”和“/”分別改成了“-”和“_”,這樣就免去了在URL編解碼和資料庫存儲時所要作的轉換,避免了編碼信息長度在此過程中的增加,並統一了資料庫、表單等處對象標識符的格式。
另有一種用於正則表達式的改進Base64變種,它將“+”和“/”改成了“!”和“-”,因為“+”,“*”以及前面在IRCu中用到的“[”和“]”在正則表達式中都可能具有特殊含義。
此外還有一些變種,它們將“+/”改為“_-”或“._”(用作程式語言中的標識符名稱)或“.-”(用於XML中的Nmtoken)甚至“_:”(用於XML中的Name)。
Base64要求把每三個8Bit的位元組轉換為四個6Bit的位元組(3*8 = 4*6 = 24),然後把6Bit再添兩位高位0,組成四個8Bit的位元組,也就是說,轉換後的字元串理論上將要比原來的長1/3。
規則
關於這個編碼的規則:
①.把3個字元變成4個字元。
②每76個字元加一個換行符。
③.最後的結束符也要處理。
例子(1)
轉換前 11111111, 11111111, 11111111 (二進制)
轉換後 00111111, 00111111, 00111111, 00111111 (二進制)
上面的三個位元組是原文,下面的四個位元組是轉換後的Base64編碼,其前兩位均為0。
轉換後,我們用一個碼錶來得到我們想要的字元串(也就是最終的Base64編碼),這個表是這樣的:(摘自RFC2045)
轉換表
Table 1: The Base64 Alphabet
| 索引 | 對應字元 | 索引 | 對應字元 | 索引 | 對應字元 | 索引 | 對應字元 |
| 0 | A | 17 | R | 34 | i | 51 | z |
| 1 | B | 18 | S | 35 | j | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v | ||
| 14 | O | 31 | f | 48 | w | ||
| 15 | P | 32 | g | 49 | x | ||
| 16 | Q | 33 | h | 50 | y |
例子(2)
轉換前 10101101,10111010,01110110
轉換後 00101011, 00011011 ,00101001 ,00110110
十進制 43 27 41 54
對應碼錶中的值 r b p 2
所以上面的24位編碼,編碼後的Base64值為 rbp2
解碼同理,把 rbq2 的二進制位連線上再重組得到三個8位值,得出原碼。
(解碼只是編碼的逆過程,有關MIME的RFC還有很多,如果需要詳細情況請自行查找。)
第一個位元組,根據源位元組的第一個位元組處理。
規則:源第一位元組右移兩位,去掉低2位,高2位補零。
既:00 + 高6位
第二個位元組,根據源位元組的第一個位元組和第二個位元組聯合處理。
規則如下,第一個位元組高6位去掉然後左移四位,第二個位元組右移四位
即:源第一位元組低2位 + 源第2位元組高4位
第三個位元組,根據源位元組的第二個位元組和第三個位元組聯合處理,
規則第二個位元組去掉高4位並左移兩位(得高6位),第三個位元組右移6位並去掉高6位(得低2位),相加即可
第四個位元組,規則,源第三位元組去掉高2位即可
//用更接近於編程的思維來說,編碼的過程是這樣的:
//第一個字元通過右移2位獲得第一個目標字元的Base64表位置,根據這個數值取到表上相應的字元,就是第一//個目標字元。
//然後將第一個字元與0x03(00000011)進行與(&)操作並左移4位,接著第二個字元右移4位與前者相或(|),即獲得第二個目標字元。
//再將第二個字元與0x0f(00001111)進行與(&)操作並左移2位,接著第三個字元右移6位與前者相或(|),獲得第三個目標字元。
//最後將第三個字元與0x3f(00111111)進行與(&)操作即獲得第四個目標字元。
//在以上的每一個步驟之後,再把結果與 0x3F 進行 AND 位操作,就可以得到編碼後的字元了。
可是等等……聰明的你可能會問到,原文的位元組數量應該是3的倍數啊,如果這個條件不能滿足的話,那該怎么辦呢?
我們的解決辦法是這樣的:原文剩餘的位元組根據編碼規則繼續單獨轉(1變2,2變3;不夠的位數用0補全),再用=號補滿4個位元組。這就是為什麼有些Base64編碼會以一個或兩個等號結束的原因,但等號最多只有兩個。因為:
一個原位元組至少會變成兩個目標位元組
所以餘數任何情況下都只可能是0,1,2這三個數中的一個。如果餘數是0的話,就表示原文位元組數正好是3的倍數(最理想的情況)。如果是1的話,轉成2個Base64編碼字元,為了讓Base64編碼是4的倍數,就要補2個等號;同理,如果是2的話,就要補1個等號。
代碼實現
JavaScript版
BASH版
Java版
PHP版
[下列代碼僅在GBK中實現,UTF8代碼請把 if($button=="迅雷地址->普通地址") echo substr(base64_decode(str_ireplace("thunder://","",$txt1)),2,-2); 這句改為if($button=="迅雷地址->普通地址") echo substr(mb_convert_encoding(base64_decode(str_ireplace("thunder://","",$txt1))),2,-2); 並把charset=gb2312改為charset=utf-8]
VB版
注:其中DigestStrToHexStr為可在程式外部調用加密函式
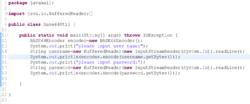
C#版
MIME
 base64
base64在MIME格式的電子郵件中,base64可以用來將binary的位元組序列數據編碼成ASCII字元序列構成的文本。使用時,在傳輸編碼方式中指定base64。使用的字元包括大小寫字母各26個,加上10個數字,和加號“+”,斜槓“/”,一共64個字元,等號“=”用來作為後綴用途。
完整的base64定義可見 RFC1421和 RFC2045。編碼後的數據比原始數據略長,為原來的4/3。在電子郵件中,根據RFC822規定,每76個字元,還需要加上一個回車換行。可以估算編碼後數據長度大約為原長的135.1%。
轉換的時候,將三個byte的數據,先後放入一個24bit的緩衝區中,先來的byte占高位。數據不足3byte的話,於緩衝區中剩下的Bit用0補足。然後,每次取出6個bit,按照其值選擇ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/中的字元作為編碼後的輸出。不斷進行,直到全部輸入數據轉換完成。
如果最後剩下兩個輸入數據,在編碼結果後加1個“=”;如果最後剩下一個輸入數據,編碼結果後加2個“=”;如果沒有剩下任何數據,就什麼都不要加,這樣才可以保證資料還原的正確性。
舉例來說,一段引用自Thomas Hobbes"s Leviathan的文句:
Man is distinguished, not only by his reason, but by this singular passion from other animals, which is a lust of the mind, that by a perseverance of delight in the continued and indefatigable generation of knowledge, exceeds the short vehemence of any carnal pleasure.
經過base64編碼之後變成:
TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCBieSB0aGlz
IHNpbmd1bGFyIHBhc3Npb24gZnJvbSBvdGhlciBhbmltYWxzLCB3aGljaCBpcyBhIGx1c3Qgb2Yg
dGhlIG1pbmQsIHRoYXQgYnkgYSBwZXJzZXZlcmFuY2Ugb2YgZGVsaWdodCBpbiB0aGUgY29udGlu
dWVkIGFuZCBpbmRlZmF0aWdhYmxlIGdlbmVyYXRpb24gb2Yga25vd2xlZGdlLCBleGNlZWRzIHRo
ZSBzaG9ydCB2ZWhlbWVuY2Ugb2YgYW55IGNhcm5hbCBwbGVhc3VyZS4=
