
程式錯誤類型
程式錯誤類型主要有語法錯誤、語義錯誤和邏輯錯誤,其中,語法錯誤和邏輯錯誤能通過編譯器發現,邏輯錯誤只能由編程人員通過比對結果和設計方案發現錯誤並處理。
語法錯誤
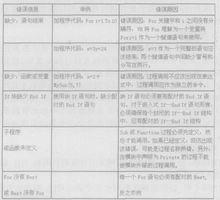 圖1常見語法錯誤
圖1常見語法錯誤語法錯誤是因為源程式中不正確的代碼產生的,即在編寫程式時沒有遵守語法(或詞法)規則,書寫了錯誤的語法代碼,從而導致編譯器無法正確解釋原始碼而產生的錯誤,通常是由於錄入的錯誤引起的,它在詞法分析或語法分析時檢測出來。如“非法字元”、“括弧不匹配”、“缺少;”之類的錯誤。圖1為一些常見語法錯誤。
語義錯誤
語義錯誤是指源程式中不符合語義規則的錯誤,即一條語句試圖執行一條不可能執行的操作而產生的錯誤。語義錯誤有的在語義分析時檢測處來,有的在運行時才能檢測出來。如變數聲明錯誤、作用域錯誤、數據存儲區的溢出等錯誤。
邏輯錯誤
邏輯錯誤是指程式的運行結果和程式設計師的構想有出入時產生的錯誤。這類錯誤並不直接導致程式在編譯期間和運行期間出現錯誤,但是程式未按預期方式執行,產生了不正確的運行結果,較難發現。這種錯誤只能通過分析結果,將結果與設計方案進行對比來發現。
錯誤處理規範
按照錯誤類型
按照錯誤類型,通常的處理方式如下:
| 錯誤類型 | 範圍 | 處理方式 |
| 操作員錯誤 | 與人機界面互動時不滿足輸入規則、輸入範圍等發生的錯誤 |
|
| 運行時錯誤 | 與外部資源互動時發生的錯誤,如網路、檔案系統、資料庫、其它業務套用系統等 |
|
| 程式設計師錯誤 | 與客戶模組互動時不滿足前置條件後置條件發生的錯誤,如類庫被其他程式設計師調用時參數超出範圍等 |
|
按照調用類型
按照調用類型,通常的處理方式如下:
| 調用類型 | 處理方式 |
| 同步調用 |
|
| 異步調用 |
|
按照展現方式
按照展現方式,通常的分類如下:
| 展現方式 | 涉及模組 |
| 界面提示 |
|
| 記錄日誌 |
|
錯誤處理技術
編譯器檢查出源程式中的錯誤後,首先要向用戶報告錯誤信息,以便可以進一步改正錯誤。另外還要對錯誤進行適當的處理,以便分析過程可以繼續下去,對錯誤的處理主要有兩種方法:錯誤改正和錯誤局部化處理。
語法錯誤處理
詞法分析中的錯誤局部化處理比較簡單,而編譯過程中大部分查錯和改錯工作集中在語法分析階段,下文為自上而下語法分析中的錯誤局部化處理策略。
處理措施
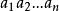 錯誤處理
錯誤處理在語法分析過程的每一時刻,總可以把源程式輸入符號串 劃分為如下形式(式1):
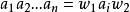 錯誤處理
錯誤處理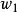 錯誤處理
錯誤處理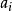 錯誤處理
錯誤處理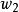 錯誤處理 錯誤處理 錯誤處理
錯誤處理 錯誤處理 錯誤處理其中, 是已經掃描和加工過的部分, 為現行輸入符號, 是輸入串的餘留部分。假定編譯程式現在發現了源程式中的一個語法錯誤,這對自上而下分析來說,就意味著分析器目前已為輸入串建立了一棵部分語法樹,並且此部分語法樹已經覆蓋了子串 ,但卻無法再擴大而覆蓋 。此時,就必須確定如何修改源程式來“更正”這個錯誤。可供採用的修改措施如下:
錯誤處理(1) 刪去符號 再進行分析;
錯誤處理 錯誤處理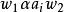 錯誤處理
錯誤處理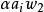 錯誤處理
錯誤處理(2) 在 與 之間插入一終結符號串α,即把式(1)修改為(式2): ,然後再從 的首部開始分析;
錯誤處理 錯誤處理 錯誤處理(3) 在 與 之間插入終結符號串α(見式(2)),但從 開始分析;
錯誤處理(4) 從 的尾部刪去若干個符號。
以上各種修改措施既可單獨使用,也可聯合使用。但(3)、(4)兩種措施需對源程式已加工部分進行修改,從而可能更改相應語義信息,因此實現起來比較困難而較少採用。
處理算法
錯誤處理假定在語法分析過程中,當掃描到輸入符號 時發現了一個語法錯誤(見式(1)),且已構造的部分語法樹不能進行擴展,則可執行下面的算法對該語法錯誤進行校正:
(1) 建立一個符號表L,它由所有未完成分支的各個未完成部分中的符號組成。
錯誤處理 錯誤處理 錯誤處理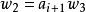 錯誤處理
錯誤處理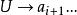 錯誤處理
錯誤處理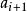 錯誤處理
錯誤處理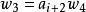 錯誤處理
錯誤處理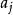 錯誤處理
錯誤處理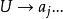 錯誤處理
錯誤處理(2) 對於從出錯點開始的餘留輸入串 ,刪去 並考察 ,看L中是否存在這樣的一個符號U且滿足 U ai+1…。如果這樣的U不存在,則再刪去 並繼續考察 ,直到找到某個 滿足 為止。
(3) 根據(2)所得到的U確定它所在的那個未完成分支。
錯誤處理(4) 確定一個符號串α,使得若把α插入到 之前便能使分析繼續下去。為了確定這樣的α,只需要考察(3)所找到的那個未完成分支以及其各子樹的未完成分支,並對它們都確定一個終結符號串以補齊相應的分支,最後再把這些終結符號串依次排列在一起就得到了所需的α。
錯誤處理(5) 把α插到 之前並從α的首部開始繼續分析過程。
語義錯誤處理
遏止錯誤株連信息
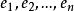 錯誤處理
錯誤處理錯誤株連,是指當源程式出現一個錯誤時,此錯誤將導致發生其它錯誤,而後者可能並不是一個真正的錯誤。例如,當編譯程式處理一個形如A[ ]的下標變數時,,假定由查符號表得知A不是一個數組名,這就出現了一個錯誤;而其後核對此下標變數的下標個數是否與相應數組的維數一致時,由於A不是數組名而查不到內情向量,從而只能認為兩者不一致,於是又株連產生了第二個錯誤。
為了遏止這種株連信息,一種簡單的辦法是在源程式中用一個“正確”的標識符去替換出錯的標識符,同時把新標識符登入符號表中並儘可能填入各種屬性。在此,這種符號表登記項是為改正錯誤而臨時插入的,故對它們加以特殊標誌。這樣就可按下述方法實現遏止株連信息:每當發現一個引起錯誤的標識符時,就以該標識符的符號表登記項指針作為參數去調用輸出出錯信息子程式,這個子程式將查看相應的登記項,如果它已加以標誌,則不再輸出出錯信息。
遏止重複出錯信息
在源程式中,如果某一標識符未加說明或者說明不正確,則會導致程式中對該標識符的錯誤使用。例如下面的程式:
 錯誤處理
錯誤處理由於未在函式f中對整型變數c加以說明,因而賦值句中對c的每次引用都將輸出“變數的類型不相容”錯誤信息。當在源程式中發現使用了一個未經說明的標識符時,就將它登入符號表中,並根據上下文填寫所查出的一些屬性;再建立另一張表,其中各個登記項有相應標識符的各種錯誤用法,在遇到一個錯用的標識符時就順序檢查這張表。如果以前曾按同樣方式使用過該標識符,就不再輸出出錯信息;否則,除輸出出錯信息外,還要將本次錯用的情況登入該表。
