介紹
我國社會信息化的發展速度一直維持在高水平,銀行業作為領先的龍頭行業,一直進行著大規模的信息技術工程建設。銀行依託網路優勢,按照公司治理架構和商業銀行管理要求,不斷豐富業務品種,不斷拓寬行銷渠道,不斷完善服務功能,並提供更全面、更便捷的基礎金融服務,成為一家資本充足、內控嚴密、營運安全、功能齊全、競爭力強的現代銀行。同時,為了提高郵政儲蓄銀行的服務質量,推進郵政儲蓄銀行體制改革,實現生產管理的自動化和信息化,很有必要開發設計一個客戶信息管理系統。
在實際開發過程中,不免遇到一些問題。比如如何處理大量數據的查詢。在整個開發過程中,用到了幾種方法,加快了大量數據的查詢處理速度,在此進行一些探討。
傳統銀行數據處理
傳統的交易處理是一種串列處理。例如" 客戶從上取款"銀行主機系統的處理流程如圖所示,
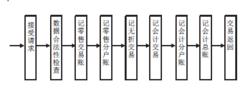 圖1
圖1顯然, 這樣一個在線上交易要占用較多的系統資源。數據大集中後,並發的業務請求很多,交易流程越短,就意味著占用系統資源越少,對提高整個系統的性能越有好處。隨著銀行信息化進程中,銀行業的經營理念從以賬戶和產品為中心向以客戶為中心轉變,銀行業務系統的設計也應該樹立以客戶為中心的思想。 長期以來,銀行有一條原則是先記賬後付款,銀行需要較長的時間來記賬,包括記客戶賬和銀行賬,還要列印銀行所需要的各種傳票。這種服務流程如圖所示,
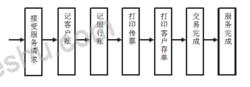 圖2
圖2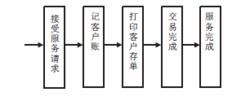 圖3
圖3要更好地服務客戶,縮短客戶的等待時間,就必須改變銀行的服務流程。 銀行受理客戶的服務請求,應該只處理與客戶密切相關的事,銀行的內部賬。銀行的內部傳票可以在完成客戶服務後再予以處理簡化的服務流程如圖所示:
數據大集中後,相同信息集中存放,每一類信息的數量比數據集中前都大為增加,從而使數據的分類處理成為必然。 過去,一個程式往往可以用來完成幾個甚至十幾個資料庫表的操作。 現在我們完全可以把分類的數據用不同的程式來處理,使每個程式做單一的事情。 如,可以寫一個程式根據零售交易更新客戶分戶賬,用另外一個程式寫無折交易表。 會計交易、會計分戶賬、會計總賬都用不同的程式來處理。
銀行數據大集中後,對數據進行深層次的加工、處理,是銀行信息系統要做的重要工作。 運用多級流水線技術,必將大大提高銀行處理海量數據的效率。銀行的數據要經過3 個加工階段:在線上的數據加工階段,日終批量的數據加工階段和數據的深加工階段(運用數據倉庫技術) 。 而客戶通過銀行套用系統做業務,產生基礎數據的階段,可稱之為數據採集階段。 我們可以把數據加工的3個階段,分別交給3個以流水線方式工作的數據處理廠來完成。
數據大集中後,銀行信息系統的設計是個龐大的系統工程。首先在架構上要有全新的思路,滿足銀行經營、管理、決策信息化的要求,同時還要面向未來銀行業務虛擬化的趨勢,在具體實現上採用先進的技術。
最佳化技術
創建聯合索引
通常數據表只有一個索引,就是主鍵。但有時候做數據查詢時,不單單使用主鍵作為查詢條件,而可能用到多個欄位作為條件。而對於信息系統,有些數據表又是無時無刻在做著查詢操作,所以,可以對常用的查詢建立聯合索引以加快查詢速度。
例如SQL語句:select * from tablewhere userid1="a" and userid2="b"。此類語句反覆執行就可以為userid1欄位和userid2欄位建立聯合索引了。
使用PreparedStatement語句
系統運行過程中,面不了要對數據表進行反覆的讀取,所以數據連結這一環節也是非常重要。以往的數據連線都是使用Statement語句,但由於PreparedStatement對象已預編譯過,所以其執行速度要快於Statement對象。因此,多次執行的SQL語句經常創建為PreparedStatement對象,以提高效率。
SQL語句最佳化
合理的編寫SQL語句能避免資源的浪費,提高執行效率。開發中要注意的問題有下列幾點:
1.應當簡化或避免對大型表進行重複的排序。
2.消除對大型表行數據的順序存取。
3.避免困難的正規表達式。
4.可以多用臨時表來空間換時間。
使用分頁技術
分頁技術通常用於海量數據處理中。即把一張大表分割成幾張小表。首先利用索引(或聯合索引)將滿足條件的記錄的主鍵列插入到一個臨時表,然後從該臨時表中獲取滿足條件的記錄總數,再從臨時表中獲取第N頁的主鍵值集合,根據主鍵值集合從目標表中取出對應的記錄以構成所要的頁,最後釋放臨時表。
對海量數據進行分區操作
對海量數據進行分區操作十分必要,分區和分頁又有所不同。例如可以根據信息系統中客戶的行業進行分類,然後進行分區,將不同的數據存於不同的檔案組下,而不同的檔案組存於不同的磁碟分區下,這樣將數據分散開,減小磁碟I/O,減小了系統負荷,而且還可以將日誌,索引等放於不同的分區下。
分批處理
海量數據處理難因為數據量大,那么解決海量數據處理難的問題其中一個技巧是減少數據量。可以對海量數據分批處理,然後處理後的數據再進行合併操作,這樣逐個擊破,有利於小數據量的處理,不至於面對大數據量帶來的問題,不過這種方法也要因時因勢進行,如果不允許拆分數據,還需要另想辦法。不過一般的數據按天、按月、按年等存儲的,都可以採用先分後合的方法,對數據進行分開處理。
使用數據採樣
某些情況下,對大量的數據可以用數據挖掘,一般的方法就是採用數據抽樣。但這種方法需要考慮全面,在保證數據的完整性的前提下來設計一個合理的抽樣方法,可以大大提高數據處理的速度和成功率,並且也要把誤差控制在一定的範圍內。
考慮使用TXT文檔
系統對於讀取資料庫的速度和讀取txt文檔的速度是不同的,讀寫txt文檔的速度要快很多。比如日誌檔案通常包含了海量的信息,而且日誌檔案也不斷得進行著讀寫操作,更重要的是,很多應用程式或者系統的日誌檔案都是txt文檔。所以在開發信息系統過程中,為了解決反覆讀取資料庫所帶來時間上的問題,在條件允許的情況下,可以使用txt文檔做一些中轉處理。
數據查詢各種方法的使用,是要根據具體情況而定:可以提供的硬體環境如何;數據量有多大;使用哪些資料庫工具和開發工具等等。
