
單呼言語識別
發音時每發一次識別單位(單字、詞、詞組或短語、語句),必須停頓一下,停頓時間一般要求100~150毫秒,而每個單位(例如短句)內部不允許短於 100毫秒。例如,口呼地名的識別,一個地名與另一個地名之間要求隔開 100毫秒以上,但是在一個地名內部不得超過 100毫秒的間隙,一個地名作為一個單位來識別,而並不識別一個地名由哪些字音構成。連呼言語識別
發音人一口氣說了一些話,字音之間不存在間隙,而是連續發音,要求機器識別話中每一個字。例如說“北京”這兩個字音, 要求機器識別"北"與"京"兩個字。這就存在著音節切分的問題。 要將"北”與“京”兩個音的分界點找出來,可根據第二字的輔音來判斷;但如果第二字的輔音是濁音或是零聲母,切分就非常困難。專人言語識別
機器要求發音人首先把所用的字表念一遍或幾遍,以適應這個發音人的特點,識別這個專門人的話音。當換一個人發音時,一般識別精度會明顯下降。通用言語識別
不用訓練,機器即能識別很多人在一定範圍內的話音。不用訓練,指不需要適應專門人的臨時訓練。國外發表的一些實驗結果,雖然能夠與專人言語識別系統的結果相比擬,但是在計算機里存放的信息遠較專人言語識別系統多。語言理解系統
發音人說話後,計算機能懂其意思,並能分析關鍵字的含義,而不必逐字逐句地識別,這叫做語言理解系統。發音人的識別與驗證 從話音來識別發音人,稱發音人的識別。發音人的驗證是讓機器對話音及發音人作出是與否的判定。
工作原理
①模式匹配法的識別:以專人單呼言語識別系統為例,最常見的是“模式匹配法”。假定要求計算機能識別100個口呼中國地名(“北京”、“上海”、……),用戶就得按照 100個地名表,逐個訓練計算機──呼一遍或幾遍,計算機在它的存貯器里建立參考模式,每個地名有一個或幾個參考模式,用戶可以隨便呼出地名表中的任何一個地名, 計算機將新呼進來的語音模式(參數)與存好的參數模式,逐個地進行比較,算好未知語音模式與每個參考模式的距離(或相似性),根據這個距離表,找出距離最小者(或相似性最好者)所對應的參考模式,從而判定發音人發的是哪個地名。構成模式的參數,一般用短時頻譜數據。分析語音的短時頻譜,可以用軟體對經過模/數轉換後進入計算機的數字式語言波來完成,也可以用專門的硬體──濾波器──組(模擬的或數字式的)來分析,這稱為前置分析。(圖1)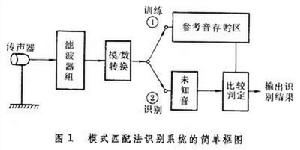 言語識別
言語識別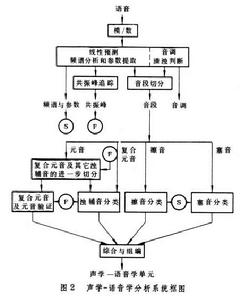 言語識別
言語識別就目前人們所掌握的技能來說,下列項目已經完全能夠實現聲控:如自動分檢郵包,機器人的動作,傳輸帶上的產品檢驗,話控鎖,數據輸入並算帳,一定範圍的編輯系統,軍事指揮命令的下達,航天器上的儀器操作,生產線上的控制等等,言語識別的研究成果還將深入到家庭,如聲控開門、關門、拉窗簾、電視開關選台、電話撥號、家用機器傭人等等。
參考書目
S.R.Hyde, Automɑtic Speech Recoɡnition:A Cri-ticɑl Survey ɑnd Discussion of the Literɑture,E.E.David,Jr.(ed.),Human
Communication:A Unified View,McGraw-Hill Book Co.,New York,1972.
D.R. Reddy (ed.), Speech Recoɡnition, AcademicPress,New York,1975.
