
定義
行人重識別(Person re-identification)也稱行人再識別,是利用計算機視覺技術判斷圖像或者視頻序列中是否存在特定行人的技術。廣泛被認為是一個圖像檢索的子問題。 給定一個監控行人圖像,檢索跨設備下的該行人圖像。旨在彌補目前固定的攝像頭的視覺局限,並可與行人檢測/行人跟蹤技術相結合 ,可廣泛套用於智慧型視頻監控、智慧型安保等領域。
發展歷史
行人重識別的研究起始於二十世紀九十年代中期。研究者們借鑑、引入了一些圖像處理、模式識別領域的成熟方法,側重研究了行人的可用特徵、簡單分類算法。自2014 年以來,行人重識別技術的訓練庫趨於大規模化,廣泛採用深度學習框架。隨著高校、研究所以及一些廠商的研究持續深入,行人重識別技術得到了飛速的發展。
目前,海外主要的行人重識別系統的研究機有悉尼科技大學(UTS)、倫敦瑪麗女王大學(QMUL)等;中國大陸及港澳台的主要有清華大學、北京大學、復旦大學、香港中文大學、西安交通大學、中國科學技術大學、中山大學,中科院自動化所等。
技術難點
1. 能不能用人臉識別做重識別?
理論上是可以的。但是有兩個原因導致人臉識別較難套用:首先,廣泛存在後腦勺和側臉的情況,做正臉的人臉識別難。其次,攝像頭拍攝的像素可能不高,尤其是遠景攝像頭裡面人臉截出來很可能都沒有32x32的像素。所以人臉識別在實際的重識別套用中很可能有限。
2.有些人靠衣服的顏色就可以判斷出來了,還需要行人重識別么?
衣服顏色確實是行人重識別做出判斷一個重要因素,但光靠顏色是不足的。首先,攝像頭之間是有色差,並且會有光照的影響。其次,有撞衫(顏色相似)的人怎么辦,要找細節,但比如顏色直方圖這種統計的特徵就把細節給忽略了。在多個數據集上的測試表明,光用顏色特徵是難以達到50%的top1正確率的。
方法
基於部件匹配的方法
基於人體在三維空間中的結構(結構信息),人體圖像可以進行分割,按部件來執行匹配。
1.常見方案是水平切割,就是將圖像切為幾個水平的條。由於人體身材往往差不多,所以可以用簡單的水平條來做一一比較。
2.在領域中做匹配,採用的是一個正方形的鄰域。
3.另一個較新的方案是先在人體上檢測部件(手,腿,軀幹等等)再進行匹配,這樣的話可以減少位置的誤差,但可能引入檢測部件的誤差。
4. 類似LSTM的attention匹配,但必須pair輸入,測試時間較長,不適合快速圖像檢索。
5. 如圖,類似人臉對齊,使用STN 將行人整個圖像先利用熱度圖對齊,再匹配。
 行人匹配熱度圖
行人匹配熱度圖基於損失函式的方法
基於高層語義信息,設定一些輔助任務,幫助模型學習到好的特徵表達。
1. 身份損失(Identification loss)直接拿身份label做多類分類。
2. 鑑定損失(Verification loss)比較兩個輸入圖像是否為同一人。
3. 身份損失(Identification loss)+鑑定損失(Verification loss),將以上兩種損失函式混合。
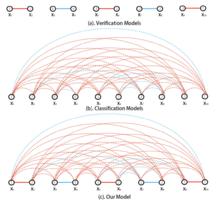 行人重識別
行人重識別4. 三樣本損失 (Triplet loss) 以3個樣本為一組,同一人的圖像特徵距離應小於不同人。
5. 加入屬性任務 (attribute)比如判斷是否背包,是男生還是女生等等。人們遇見陌生人也是利用這些屬性來描述。
6. 數據增強 混合多數據集訓練 ,加入訓練集上 生成對抗網路(GAN)生成的數據。
 行人重識別
行人重識別數據集
DukeMTMC-reID
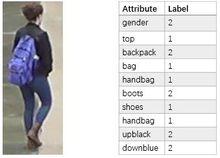
該數據集在杜克大學內採集,圖像來自8個不同攝像頭。該數據集提供訓練集和測試集。 訓練集包含16,522張圖像,測試集包含 17,661 張圖像。訓練數據中一共有702人,平均每類(每個人)有23.5 張訓練數據。是目前最大的行人重識別數據集,並且提供了行人屬性(性別/長短袖/是否背包等)的標註。
 DukeMTMC-reID數據集示例
DukeMTMC-reID數據集示例DukeMTMC-attribute
該數據集基於DukeMTMC-reID數據集,加入了行人屬性(如性別gender/是否背包bag等23種屬性),並且提升了DukeMTMC 行人重識別的效果。
 行人重識別
行人重識別Market-1501
 Market-1501數據集
Market-1501數據集該數據集在清華大學校園中採集,圖像來自6個不同的攝像頭,其中有一個攝像頭為低像素。同時該數據集提供訓練集和測試集。 訓練集包含12,936張圖像,測試集包含19,732 張圖像。圖像由檢測器自動檢測並切割,包含一些檢測誤差(接近實際使用情況)。訓練數據中一共有751人,測試集中有750人。所以在訓練集中,平均每類(每個人)有17.2張訓練數據。
Market1501-attribute
該數據集基於Market-1501數據集,加入了行人屬性(如性別/是否背包等27種屬性),並且提升了Market-1501上行人重識別的效果。
CUHK03
 CUHK03數據集
CUHK03數據集該數據集在香港中文大學內採集,圖像來自2個不同攝像頭。該數據集提供 機器檢測和手工檢測兩個數據集。 其中檢測數據集包含一些檢測誤差,更接近實際情況。平均每個人有9.6張訓練數據。
發展方向
1.自然語言檢索
通過對行人的語言描述來找到指定行人。 如圖,尋找藍色襯衫的女性。
 行人重識別
行人重識別2. 利用生成數據 輔助訓練
使用生成對抗網路(GAN)生成更多數據,輔助數據驅動的深度學習。
 行人重識別
行人重識別3.遷移學習
由於數據集與現實數據之間的差異,導致在數據集A上訓練好的模型在現實數據B上性能表現不佳。 目前學界主要採用遷移學習的方法,在有標籤的數據集A(比如Market-1501)和無標籤數據集B(比如DukeMTMC-reID訓練集抹掉訓練標籤)上訓練,最後在數據集B的測試集上測試。
