
定義
資訊時代到來的今天,計算機網路以資源共享、數據通信特性,已日益滲透到了人們生活的許多領域,所以保持網路的良好可靠性和較高的效率是至關重要的,這就出現了網路管理。網路管理是對組成網路的資源和設備的規劃、設計、控制,使網路具有最高的效率和生產力,從而為用戶提供高效的服務。
所謂編譯器生成器即對於一段給定的單詞正則表達式,自動構造一個能進行詞法分析的詞法分析器;對於一段給定的文法,自動構造一個能進行語法分析的語法分析器:能自動加上必要的語義分析,並能給出面向用戶的語義程式接口的程式。
現在的編譯器生成器多是單個分開的,即它是單個的詞法分析器生成器,或者單個的語法分析器生成器,語義分析器生成器還只能完成抽象語義分析。集編譯器各個階段為一體的編譯器生成器還要需要進一步的研究。
重要性
編譯器的自動生成器能夠針對一種新型的處理器體系結構,產生相應的最佳化編譯器。編譯器的自動生成器於是構成了可重構軟體中的重要一環。對於一種新型的硬體結構,它的彙編指令系統和機器資源是特定的,應該提供給設計人員一個配置接口,使他們能夠方便的定義這些特定資源來描述和指定一種特定的硬體結構,利用自動生成器生成面向於這種機器的編譯器,實現可重定目標。
發展歷史
編譯,代表從面向人的源語言表示的算法到面向硬體的目標語言表示的算法的一個等價變換。通常情況下,人們將能夠完成一種語言到另一種語言變換的軟體稱為“翻譯器”,而編譯器就是其中的一類。
編譯器是程式設計師將命令翻譯成可以在計算機上執行的代碼的軟體開發工具。編譯器的工作可以分成若干階段,每個階段把源程式從一種表達形式變換成另一種表達形式。編譯程式的典型工作流程為:詞法分析、語法分析、語義分析、轉換、規範化、程式碼選擇、控制流分析、數據流分析、暫存器分配、代碼生成、彙編和聯結器。在前端編譯技術中,詞法分析、語法分析、語義分析被作為討論的重點,而在所有的前端技術中,最具研究價值的就是語法分析。
1975年Lesk第一次提出基於正則表達式的詞法分析器概念。1986年Ahoet al,提出了更有效計算若閉包和壓縮DFA狀態矩陣豹方法。1988年Gray建立了行詞法分析方法。993年Bumbulis和Cowan提出了單遍遍歷DFA狀態就能夠完成詞法分析的算法。而詞法分析器生成器的工作要晚得多,1995年,Paxson開發出第一個詞法分析器生成器Flex。
1963年Conway描述了基於FIRST集合的語法分析器。1968年Lewis和Steams第一次提出了LL(k)文法理論。1965年Knuth提出LR(k)理論,SLR和LALR理論則是由DeRemer在1971年提出。
1975年,第一個語法分析器生成器YACC問世。1987年,Burke和Fisher提出了錯誤回溯問題。1996年,JavaCup問世,它是第一個基於Java的編譯器生成器。
在國內,研究編譯器實現的比較少。在1998年進行“九五”國家重點科技攻關項目中,由中國科學院進行了有關Java編譯器的研究。而編譯器生成器方面,則剛剛開始進一步的研究。
相關技術
編譯器生成器的工作就是在前端,需要將用戶對新語言的詞法、語法、語義信息的直觀描述(形式文法)轉換成分析程式的內部處理形式;在後端,需要將用戶對新機器物理特性到邏輯特性映射的直觀描述轉換成生成程式使用的數據和算法。
編譯器前端包括詞法分析和語法分析語義分析,生成中間代碼,它主要依賴於源語言,和目標機體系結構無關。所以該部分可以作為構件完全重用。編譯器後端包括代碼最佳化部分、代碼選擇,代碼生成、暫存器分配等。後端是編譯器中與目標機相關的部分。一般來說,這些部分獨立於源語言,而僅僅依賴於中間表示和目標機器。
分層
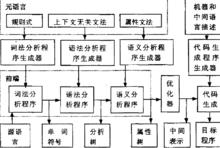 自動生成器的分層圖示
自動生成器的分層圖示自動生成器的分層如下圖所示。
結構
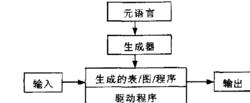 編譯程式生成器的一般結構
編譯程式生成器的一般結構編譯程式生成器的一般結構是如下圖。
實際上,這種程式自動生成結構是將問題求解的表示與操作分離。生成器將元語言表示的信息轉換成驅動程式直接訪問的數據結構,多數情況下這些數據結構以程式形式存放,然後經編譯與驅動程式連結,儘管這樣會比直接生成表低效,但允許用戶修改所生成的內容,以調整驅動程式的輸入。
詞法分析程式自動生成
詞法分析程式生成器的結構如下圖所示。生成詞法分析程式的過程類似於編譯過程本身,它使用的是如下方法:將一個文法的正則表達式轉化為一個NFA,再轉化為一個DFA,最後用DFA化簡的方法將該DFA簡化。
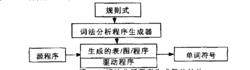 詞法分析程式生成器的結構
詞法分析程式生成器的結構語法分析程式的自動生成
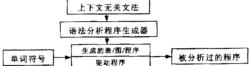 語法分析程式生成器的結構
語法分析程式生成器的結構語法分析程式生成器的結構如下圖所示。上下文無關文法用BNF或EBNF表示,生成的表既可以是LL語法分析表,也可以是LR語法分析表。
語義分析程式生成器
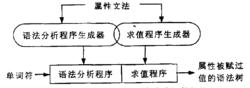 語義分析程式生成器的結構
語義分析程式生成器的結構語義分析程式生成器的結構如下圖所示。
屬性文法起源於語法制導翻譯技術,1968年Knuth對屬性文法做了規範化說明。一個
屬性文法是在BNF上附加屬性(如數據結構、值、機器碼等)和語義函式(定義如何給屬性賦值)。LL語法分析適於L—屬性文法(用繼承屬性),LR語法分析適於S—屬性文法(用合成屬性)。
元語言包括屬性文法的翻譯工具出現於七十年代末到八十年代初,如GAG(Kastens等,1982)、HLP(Rai等,1978)、VATS(Berg等,1984)和MUG-2(Ganapathi等,1982)都是基於屬性文法的描述。
後端技術
後端接受中間表示,生成等價的目標代碼。一般過程為:
1)中間代碼最佳化
最佳化的最終目的是:使用戶充分利用一個語言的特色來描述他/她的算法,而不必關心實現的效率,即不能要求編程者寫出精巧、高效的代碼。他們應關心程式的可讀性和可維性。
最佳化應針對那些最常被執行的代碼段,以及那些最常被書寫的代碼段來進行。最佳化既企圖縮短代碼執行的時間,又企圖減少生成的代碼量,通常是在兩者之間折衷。最根本的原則是:對中間代碼是等語義的變換。如果程式不被運行多次,或其生成代碼的時/空效率不是很重要,則不必最佳化。有很多最佳化策略,多數系統只是因具體要求選擇若干種最佳化算法。
使用流圖描述所有可能的執行路徑。控制流分析使數據流分析簡單。控制流分析分兩步:首先劃分基本塊,然後建立流圖。數據流分析提供數據項的定義和使用方面的信息,既有助於最佳化,又有助於調試,作用主要有:提供一個數據項被定義之前被使用的路徑:檢測冗餘或無用代碼。數據流分析也檢測循環不變式和己被計算出的表達式等信息。
2)代碼生成
代碼生成包括兩部分:暫存器分配、代碼選擇。最簡單的代碼生成可以僅是代碼選擇,即:將中間表示轉換為彙編代碼。現代編譯系統追求代碼生成程式的自動生成。暫存器分配和代碼選擇是“雞生蛋—蛋生雞”問題。好的暫存器分配算法可以極大地提高生成代碼的執行速度,因此可以被劃為最佳化處理。
3)目標代碼最佳化
對生成代碼的最佳化策略有:前面介紹的各種對中間表示的最佳化、暫存器最佳化和窺孔最佳化。窺孔最佳化(peephole optimization):檢查一小段生成代碼,用更快更短的序列代替它。被檢查的指令短序列被稱為窺孔。它的一般步驟為:①消除不必要的取數,②消除不可達代碼,③消除間接跳轉,④算術處理,⑤識別特殊指令或模式。
