
發展歷史
粗糙集理論作為智慧型計算的科學研究,無論是在理論方面還是在套用實踐方面都取得了很大的進展,展示了它光明的前景。粗集理論不僅為信息科學和認知科學提供了新的科學邏輯和研究方法,而且為智慧型信息處理提供了有效的處理技術。1982年,以波蘭數學家Pawlak為代表的研究者首次提出了粗糙集理論,並於1991年出版第一本關於粗糙集的專著,接著1992年Slowinski R 主編論文集的出版,推動了國際上對粗糙集理論與套用的深入研究。1992年在波蘭Kiekrz召開了第一屆國際粗糙集合研討會。這次會議著重討論了集合近似定義的基本思想及其套用和粗糙集合環境下的機器學習基礎研究,從此每年都會召開一次以粗糙集理論為主題的國際研討會,從而推動了粗糙集理論的拓展和套用。我國RS研究起步較晚,所能搜尋到的最早發表的論文時間是1990年,直到1998年由曾黃麟教授編著了國內最早的RS專著。粗糙集理論已成為國內外人工智慧領域中一個較新的學術熱點,引起了越來越多科研人員的關注。
理論及核心
理論簡介
面對日益增長的資料庫,人們將如何從這些浩瀚的數據中找出有用的知識?我們如何將所學到的知識去粗取精?什麼是對事物的粗線條描述什麼是細線條描述?
粗糙集合論回答了上面的這些問題。要想了解粗糙集合論的思想,我們先要了解一下什麼叫做知識?假設有8個積木構成了一個集合A,我們記:A={x1,x2,x3,x4,x5,x6,x7,x8},每個積木塊都有顏色屬性,按照顏色的不同,我們能夠把這堆積木分成R1={紅,黃,藍}三個大類,那么所有紅顏色的積木構成集合X1={x1,x2,x6},黃顏色的積木構成集合X2={x3,x4},藍顏色的積木是:X3={x5,x7,x8}。按照顏色這個屬性我們就把積木集合A進行了一個劃分(所謂A的劃分就是指對於A中的任意一個元素必然有且僅屬於一個分類),那么我們就說顏色屬性就是一種知識。在這個例子中我們不難看到,一種對集合A的劃分就對應著關於A中元素的一個知識,假如還有其他的屬性,比如還有形狀R2={三角,方塊,圓形},大小R3={大,中,小},這樣加上R1屬性對A構成的劃分分別為:
A/R1={X1,X2,X3}={{x1,x2,x6},{x3,x4},{x5,x7,x8}} (顏色分類)
A/R2={Y1,Y2,Y3}={{x1,x2},{x5,x8},{x3,x4,x6,x7}} (形狀分類)
A/R3={Z1,Z2,Z3}={{x1,x2,x5},{x6,x8},{x3,x4,x7}} (大小分類)
上面這些所有的分類合在一起就形成了一個基本的知識庫。那么這個基本知識庫能表示什麼概念呢?除了紅的{x1,x2,x6}、大的{x1,x2,x5}、三角形的{x1,x2}這樣的概念以外還可以表達例如大的且是三角形的{x1,x2,x5}∩{x1,x2}={x1,x2},大三角{x1,x2,x5}∩{x1,x2}={x1,x2},藍色的小的圓形({x5,x7,x8}∩{x3,x4,x7}∩{x3,x4,x6,x7}={x7},藍色的或者中的積木{x5,x7,x8}∪{x6,x8}={x5,x6,x7,x8}。而類似這樣的概念可以通過求交運算得到,比如X1與Y1的交就表示紅色的三角。所有的這些能夠用交、並表示的概念以及加上上面的三個基本知識(A/R1,A/R2.A/R3)一起就構成了一個知識系統記為R=R1∩R2∩R3,它所決定的所有知識是A/R={{x1},{x2},{x3},{x4},{x5},{x6},{x7},{x8}}以及A/R中集合的並。
下面考慮近似這個概念。假設給定了一個A上的子集合X={x2,x5,x7},那么用我們的知識庫中的知識應該怎樣描述它呢?紅色的三角?都不是,無論是單屬性知識還是由幾個知識進行交、並運算合成的知識,都不能得到這個新的集合X,於是 我們只好用我們已有的知識去近似它。也就是在所有的現有知識裡面找出跟他最像的兩個一個作為下近似,一個作為上近似。於是我們選擇了“藍色的大方塊或者藍色的小圓形”這個概念:{x5,x7}作為X的下近似。選擇“三角形或者藍色的”{x1,x2,x5,x7}作為它的上近似,值得注意的是,下近似集是在那些所有的包含於X的知識庫中的集合中求並得到的,而上近似則是將那些與X有交集的知識庫中的集合求並得到的。一般的,我們可以用下面的圖來表示上、下近似的概念。
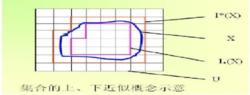 粗糙集理論
粗糙集理論此案例中上近似可理解為X集合內可區分對象的集合,即{x5,x7} (x2與x1不可區分故不算),下近似=上近似集合{x5,x7}∪X中對象不可區分的所有對象的集合{x2+x1}={x1,x2,x5,x7}
這其中曲線圍的區域是X的區域,藍色的內部方框是內部參考訊息,是下近似 ,綠的是邊界加上藍色的部分就是上近似集。其中各個小方塊可以被看成是論域上的知識系統所構成的所有劃分。
核心
整個粗集理論的核心就是上面說的有關知識、集合的劃分、近似集合等等概念。下面我們討論一下關於粗糙集在資料庫中數據挖掘的套用問題。考慮一個資料庫中的二維表如下:
元素 顏色 形狀 大小 穩定性
x1 紅 三角 大 穩定
x2 紅 三角 大 穩定
x3 黃 圓 小 不穩定
x4 黃 圓 小 不穩定
x5 藍 方塊 大 穩定
x6 紅 圓 中 不穩定
x7 藍 圓 小 不穩定
x8 藍 方塊 中 不穩定
可以看出,這個表就是上面的那個例子的二維表格體現,而最後一列是我們的決策屬性,也就是說評價什麼樣的積木穩定。這個表中的每一行表示了類似這樣的信息:紅色的大三角積木穩定,****的小圓形不穩定等等。我們可以把所有的記錄看成是論域A={x1,x2,x3,x4,x5,x6,x7,x8},任意一個列表示一個屬性構成了對論域的元素上的一個劃分,在劃分的每一個類中都具有相同的屬性。而屬性可以分成兩大類,一類叫做條件屬性:顏色、形狀、大小都是,另一類叫做決策屬性:最後一列的是否穩定?下面我們考慮,對於決策屬性來說是否所有的條件屬性都是有用的呢?考慮所有決策屬性是“穩定”的集合{x1,x2,x5},它在知識系統A/R中的上下近似都是{x1,x2,x5}本身,“不穩定”的集合{x3,x4,x6,x7,x8},在知識系統A/R中的上下近似也都是{x3,x4,x6,x7,x8}它本身。說明該知識庫能夠對這個概念進行很好的描述。下面考慮是否所有的基本知識:顏色、形狀、大小都是必要的?如果我們把這個集合在知識系統中去掉顏色這個基本知識,那么知識系統變成A/(R-R1)={{x1,x2},{x3,x4,x7},,,}以及這些子集的並集。如果用這個新的知識系統表達“穩定”概念得到上下近似仍舊都是:{x1,x2,x5},“不穩定”概念的上下近似也還是{x3,x4,x6,x7,x8},由此看出去掉顏色屬性我們表達穩定性的知識不會有變化,所以說顏色屬性是多餘的可以刪除。如果再考慮是否能去掉大小屬性呢?這個時候知識系統就變為:
A/(R-R1-R3)=A/R2={{x1,x2},{x5,x8},{x3,x4,x6,x7}}。同樣考慮“穩定”在知識系統A/R2中的上下近似分別為:{x1,x2,x5,x8}和{x1,x2},已經和原來知識系統中的上下近似不一樣了,同樣考慮“不穩定”的近似表示也變化了,所以刪除屬性“大小”是對知識表示有影響的故而不能去掉。同樣的討論對於“形狀”屬性,“形狀”屬性是不能去掉的。A/(R-R2)={{x1,x2},x6,{x3,x4},x5,x7,x8},通過求並可以得知“穩定”的下近似和上近似都是{x1,x2,x5},“不穩定”的上下近似都是{x3,x4,x6,x7,x8}。最後我們得到化簡後的知識庫R2,R3,從而能得到下面的決策規則:大三角->穩定,大方塊->穩定,小圓->不穩定,中圓->不穩定,中方塊->不穩定,利用粗集的理論還可以對這些規則進一步化簡得到:大->穩定,圓->不穩定,中方塊->不穩定。這就是上面這個數據表所包含的真正有用的知識,而這些知識都是從資料庫有粗糙集方法自動學習得到的。因此,粗糙集是資料庫中數據挖掘的有效方法。
從上面這個例子中我們不難看出,實際上我們只要把這個資料庫輸入進粗糙集運算系統,而不用提供任何先驗的知識,粗糙集算法就能自動學習出知識來,這正是它能夠廣泛套用的根源所在。而在模糊集、可拓集等集合論中我們還要事先給定隸屬函式。
進入網路資訊時代,隨著計算機技術和網路技術的飛速發展,使得各個行業領域的信息急劇增加,如何從大量的、雜亂無章的數據中發現潛在的、有價值的、簡潔的知識呢?數據挖掘(Data Mining)和知識發現(KDD)技術應運而生。
主要優勢
粗糙集理論作為一種處理不精確(imprecise)、不一致(inconsistent)、不完整(incomplete)等各種不完備的信息有效的工具,一方面得益於他的數學基礎成熟、不需要先驗知識;另一方面在於它的易用性。由於粗糙集理論創建的目的和研究的出發點就是直接對數據進行分析和推理,從中發現隱含的知識,揭示潛在的規律,因此是一種天然的數據挖掘或者知識發現方法,它與基於機率論的數據挖掘方法、基於模糊理論的數據挖掘方法和基於證據理論的數據挖掘方法等其他處理不確定性問題理論的方法相比較,最顯著的區別是它不需要提供問題所需處理的數據集合之外的任何先驗知識,而且與處理其他不確定性問題的理論有很強的互補性(特別是模糊理論)。
研究方向
理論
①利用抽象代數來研究粗糙集代數空間這種特殊的代數結構。②利用拓撲學描述粗糙空間。③還有就是研究粗糙集理論和其他軟計算方法或者人工智慧的方法相接合,例如和模糊理論、神經網路、支持向量機、遺傳算法等。④針對經典粗糙集理論框架的局限性,拓寬粗糙集理論的框架,將建立在等價關係的經典粗糙集理論拓展到相似關係甚至一般關係上的粗糙集理論。
套用領域
粗糙集理論在許多領域得到了套用,①臨床醫療診斷;②電力系統和其他工業過程故障診斷;③預測與控制;④模式識別與分類;⑤機器學習和數據挖掘; ⑥圖像處理;⑦其他。
算法
一方面研究了粗糙集理論屬性約簡算法和規則提取啟發式算法,例如基於屬性重要性、基於信息度量的啟發式算法,另一方面研究和其他智慧型算法的結合,比如:和神經網路的結合,利用粗糙集理論進行數據預處理,以提高神經網路收斂速度;和支持向量機SVM結合;和遺傳算法結合;特別是和模糊理論結合,取得許多豐碩的成果,粗糙理論和模糊理論雖然兩者都是描述集合的不確定性的理論,但是模糊理論側重的是描述集合內部元素的不確定性,而粗糙集理論側重描述的是集合之間的不確定性,兩者互不矛盾,互補性很強,是當前國內外研究的一個熱點之一。
