
簡介
為了進行檢索,通常需要對資料進行索引。傳統文獻資料需要提取題名、作者、出版年、主題詞等作為索引,而在網路時代,計算機可以對全文進行索引,即文中每一個詞都能成為檢索點。在計算機科學中,檢索集群簡單來說利用集群技術來進行檢索。常見的套用領域如資料庫索引、搜尋引擎。例如在SQL Server使用兩種索引:集群索引、非集群索引。
集群索引和電話簿類似。所以數據以字母順序存儲,在電話簿中是通過名和姓,在資料庫則取決於索引所對應的列。因為集群索引指示數據的物理存儲位置,所以一張表僅有一個集群索引。
非集群索引和書的索引類似,數據存儲在一個位置,而索引存儲在另一個位置,用指針指向數據。索引及其內容以索引鍵值的數據存放。表中的數據可以以不同的順序存儲。比如,可以以集群索引的順序存儲數據,但是如果沒有集群索引,則以任何方式數據存儲。一張表可以有多個非集群索引。
檢索集群在在檢索表設計和檢索過程中都很好的利用了數據的局部性。
集群
集群(cluster)技術是一種較新的技術,通過集群技術,可以在付出較低成本的情況下獲得在性能、可靠性、靈活性方面的相對較高的收益,其任務調度則是集群系統中的核心技術。
計算機集群簡稱集群是一種計算機系統,它通過一組鬆散集成的計算機軟體和/或硬體連線起來高度緊密地協作完成計算工作。在某種意義上,他們可以被看作是一台計算機。集群系統中的單個計算機通常稱為節點,通常通過區域網路連線,但也有其它的可能連線方式。集群計算機通常用來改進單個計算機的計算速度和/或可靠性。一般情況下集群計算機比單個計算機,比如工作站或超級計算機性能價格比要高得多。
集群分為同構與異構兩種,它們的區別在於:組成集群系統的計算機之間的體系結構是否相同。集群計算機按功能和結構可以分成以下幾類:
高可用性集群High-availability (HA) clusters
負載均衡集群Load balancing clusters
高性能計算集群High-performance(HPC)clusters
格線計算Grid computing
高可用性集群
一般是指當集群中有某個節點失效的情況下,其上的任務會自動轉移到其他正常的節點上。還指可以將集群中的某節點進行離線維護再上線,該過程並不影響整個集群的運行。
負載均衡集群
負載均衡集群運行時,一般通過一個或者多個前端負載均衡器,將工作負載分發到後端的一組伺服器上,從而達到整個系統的高性能和高可用性。這樣的計算機集群有時也被稱為伺服器群(Server Farm)。一般高可用性集群和負載均衡集群會使用類似的技術,或同時具有高可用性與負載均衡的特點。
Linux虛擬伺服器(LVS)項目在Linux作業系統上提供了最常用的負載均衡軟體。
高性能計算集群
高性能計算集群採用將計算任務分配到集群的不同計算節點而提高計算能力,因而主要套用在科學計算領域。比較流行的HPC採用Linux作業系統和其它一些免費軟體來完成並行運算。這一集群配置通常被稱為Beowulf集群。這類集群通常運行特定的程式以發揮HPC cluster的並行能力。這類程式一般套用特定的運行庫,比如專為科學計算設計的MPI庫。
格線計算
格線計算或格線集群是一種與集群計算非常相關的技術。格線與傳統集群的主要差別是格線是連線一組相關並不信任的計算機,它的運作更像一個計算公共設施而不是一個獨立的計算機。
集群技術特點
通過多台計算機完成同一個工作。達到更高的效率。
兩機或多機內容、工作過程等完全一樣。如果一台當機,另一台可以起作用。
基於伺服器集群的雲檢索系統模式
Google 於 2006年秋提出了“ 雲計算( cloud computing) ”概念。 從表象上看, 雲計算的特點有 3 個: 一是後台對用戶透明, 雲計算系統為用戶提供的是服務, 服務的實現機制對戶
透明, 用戶無需了解雲計算的具體實現機制, 就可以獲得需要的服務; 第二是接口簡單, 用戶可以通過簡單的接口體驗雲計算服務, 雲計算提供的統一簡單接口可使程式開發變得更加容易; 第三是客戶端只需安裝瀏覽器即可, 客戶端可以通過在瀏覽器中直接編輯存儲在“ 雲”的另一端的文檔, 隨時與朋友分享信息。 因此, 從表象上看, 任何一種基於網際網路的服務都可以稱之為雲。
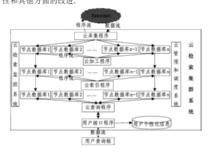 檢索集群
檢索集群在深入研究對雲計算、移動搜尋引擎的基礎上, 提出了基於伺服器集群的雲檢索系統架構模型。該模型由雲信息層、雲檢索集群系統和用戶查詢框 3 部分組成。雲檢索集群系統由雲採集層、雲加工層、雲索引層、雲查詢層、雲接口層、數據存儲雲層、雲檢索監控系統、雲管理和調度系統組成。 基於伺服器集群的雲檢索系統專注于海量數據的分散式存儲和軟體執行模式技術的突破。基於伺服器集群的雲檢索系統根據需要存儲信息的類型採用了分散式檔案系統及分散式資料庫存儲技術, 將分散式套用部署到大型廉價集群上, 從而實現海量信息的存儲。 為了便於管理及實現, 分散式檔案系統及分散式資料庫均採用主/ 從架構。 它實現了動態擴容、高效率的並行執行及數據的高可靠性, 為用戶的準確查找提供了強大的後台支持。為了提高檢索效率, 各層之間實行分散式執行, 每個層內部的功能模組實行並行執行, 這個工作調度由雲管理和調度系統來完成。 雲管理和調度系統就像管家程式, 協調處理雲檢索的各項工作。 雲監控軟體監控整個雲檢索系統, 保證系統中的不同工作能夠“ 和睦相處”, 如監視是否有來源於單個IP 地址過分密集的訪問等工作。 只有在這樣一個雲檢索的框架下, 才能實現對海量信息搜尋的規模、速度、準確性、全面性和其他方面的改進。雲檢索系統架構基於伺服器集群的雲檢索系統採取了以程式流為核心的基本理念。雲採集層把 Internet 中的海量數據經過網路機器人轉化成數據流存儲到多個節點數據檔案中; 接著雲加工和雲索引程式轉化為程式流, 流入到各個節點資料庫中, 並行處理多個節點檔案中的數據, 生成資料庫檔案存儲在相應的節點上; 用戶輸入查詢信息, 經過用戶接口程式及雲查詢程式的處理, 找到相關信息後轉化成數據流反饋給用戶。由於在集群系統中採用程式流思想降低了由海量數據流動對檢索系統執行效率產生的負面影響, 使得操作處理速度大大提升; 減少了數據在處理時的流動, 從而增加了數據的安全性與完整性。
