
概述
點評估模型無法對評估對象得出準確的暴露評估,這就需要更準確的膳食暴露評估。這些精確包括得到更多關於食品被消費的詳細資訊或採用更複雜的膳食暴露評估模型從而切合實際地模擬消費者行為。
對那些需要在篩選方法或點暴露評估方法外還需進一步精確的數據,可使用機率分析法對暴露變異性加以分析。從概念上講,人群暴露情況一般被人為是一個值域,而非一個點值,因為人群的每個人在經歷著不同的暴露水平。造成人群暴露差異的變異性因素包括年齡、性別、種族、國籍和地區、個人愛好等,膳食暴露中的變異性經常被用“機率分布”進行表述,有時,頻率分布近似於連續機率分布。
變異性分布以其代表性的人群數量為為特點,比如個人中值暴露位於分布曲線的中間,其95%個人位點的暴露值,是指其超過人群每100人中95人的暴露水平。“平均”或是“中值’暴露不一定代表任何特殊的個人情況。相反,平均暴露是通過加和所有個人的暴露量然後除以整體人群數量而得到的。
機率模型
機率評估模型應對不同情況有4 種主要方法: 簡單分布評估、隨機抽樣評估、分層抽樣評估和拉丁超立方抽樣評估。其中簡單分布估計主要是由食品消費調查得到的食品消費量的經驗分布和相應食品中化學物質濃度的點評估相乘即可得到暴露量分布; 分層抽樣是指將食品消費分布和化學物質濃度分為若干層。四種方法是根據不同情況來使用。
機率評估模型是:
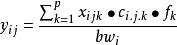 機率分布評估模型
機率分布評估模型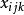 機率分布評估模型
機率分布評估模型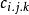 機率分布評估模型
機率分布評估模型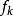 機率分布評估模型
機率分布評估模型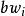 機率分布評估模型
機率分布評估模型式中表示第i個個體在j天攝入第k種食品的量,一般來源於全國膳食調查,而表示一般來源於市場上各種食品的殘留檢測,表示食品的加工因子,表示觀察個體i的體重。
從機率評估的角度,是分別將從食品攝入量和化學物的濃度作為總體A和B,在獲得A 和B兩總體獨立的分布特徵和相應的總體參數後,進行抽樣獲得y的機率分布,從而得到平均值,P,P,P,P 作為目標人群的攝入量評估值。根據上述得到的機率分布,利用統計模擬方法產生一系列描述結果參數的統計分布,評價污染物的急性攝入風險。它的優點在於可以對不確定性進行全面分析,可以作為一種模型產生的假設結果,它是一種更精確的膳食暴露評估,暴露評價結果較真實且不確定性較小; 缺點是費用較高,較難大範圍實施。
簡單分布評估
膳食暴露評估可基於食品消費量的分布。這一分布可通過經驗由食品消費調查和一個能代表相關食品商品化學物濃度的簡單點評估確定。食品消費分布曲線上的每一個點值可乘以相關食品商品中的化學濃度值。反過來說,食品消費也可能有一個點評估,即這一食品中化合物濃度也有一個經驗分布。因此,最終就有可能有足夠的數據同時確定食品消費數量和食品化學物水平的分布概況。
隨機抽樣評估
由食品消費量和化合物濃度分布的隨機抽樣評估的方法需數據集能夠表征每一相關食品中化合物濃度分布情況,同時還要能表征所關注人群對同一食品的消費分布情況。這一方法明確考慮了輸入數據的變異性,對簡單的確定性評估方法而言其提供了更貼合實際的結果,因為在簡單的確定性評估中,當選擇一個單一值以表征整個分布情況時,方法通常受限於其保守的默認假設。
蒙特卡羅疊代涉及涉及使用隨機數來選擇輸入分布的值。這一技術已被套用於各種不同的模擬方案中,在恰當使用時,其結果將會模擬實際情況,因為這一技術所使用的值均在每一數據分布範圍內。
由於是隨機抽樣,因此,蒙特卡羅模擬可能在其分布極端(高端、低端)時將會不準確,當在使用參數分布而不是非參數(經驗)分布數據時尤其如此。在這種情況下,當對污染數據使用非參數方法時,那么對其分布尾端的臨界值,及所選食品的”現實“最大觀測值,可引入非參數方法從而避免將現實生活中永遠不會發生的”不現實“污染事件納入模型中。
分層抽樣評估
分層抽樣方法為每一分布選擇等距值。例如,確定每一分布的平均數或其四分位點中值。單個分層計算的主要缺點是沒有極值評估。通過使用多層方法(如估計每一十分位平均值而不是每一四分位值)可改善此問題,但不能完全克服。通過使用多層方法可得到詳盡、準確及重現性好的輸出分布。分層抽樣的難點是需要疊代的次數可能會變得非常大,並且可能需要額外的計算機軟體技術。
拉丁超立方抽樣
拉丁超立方抽樣是統計學方法,實質上是一種分層和隨機的混合抽樣方法。首先將分布分層,之後由每層隨機抽樣,從而確保在每一濃度和食品消費量數據分布範圍內的疊代平衡,另外,這種方法還允許一些樣品得出的極端分布值。
