
簡介
數據挖掘(data mining)又稱為資料庫中的知識發現,是指從存放在資料庫、數據倉庫或其他信息庫中的大量數據中挖掘出有趣知識的過程。近年來為了推動數據挖掘在實際中的套用,許多研究者對數據挖掘系統的體系結構做了大量的研究工作。
特點
一個結構合理的數據挖掘系統應該具有以下幾個特點:
(1)系統功能和輔助工具的完備性;
(2)系統的可擴展性;
(3)支持多種數據源;
(4) 對大數據量的處理能力;
(5) 良好的用戶界面和結果展示能力。
當前出現的數據挖掘系統主要包括集中式的和分散式的數據挖掘系統,而每種系統的具體結構及其各個組成部分卻有多種不同的實現技術和實現方式。
集中式的數據挖掘系統
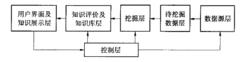 集中式數據挖掘系統的體系結構
集中式數據挖掘系統的體系結構單一資料庫/數據倉庫的數據挖掘系統是當前發展得較為成熟的數據挖掘套用系統,許多商業性的數據挖掘套用軟體都是基於這種結構。通過對當前主要的數據挖掘系統進行分析可以發現,這種集中式的結構如圖所示,但各個不同產品對各個不同功能模組的具體實現技術又不盡相同。
用戶界面及知識表示層
在該層通過提供友好的用戶界面及利用數據可視化技術展示挖掘結果,可以大大提高系統的易用性,數據挖掘的可視化是指利用可視化技術從大量的數據集中發現隱含的和有用的知識。數據挖掘的可視化主要包括數據的可視化、挖掘過程的可視化和挖掘模型的可視化,當前的可視化技術主要包括傳統的幾何學方法( 如曲線圖、直方圖、散點圖、餅圖等)、SOM 網可視化技術、平行坐標系技術、面向象素的可視化技術等。基於SOM網路和基於平行坐標系的可視化技術是目前套用較多的2項技術,它們的原理都是通過把高維數據映射為二維數據從而將數據顯示在二維平面上。如汪加才等設計的一個基於SOM 網的可視化挖掘系統VISMiner,劉勘等研究了平行坐標系技術在數據挖掘系統中的具體套用。
控制層
控制層用於控制系統的執行流程,協調各功能部件間的關係和執行順序,主要包括對數據挖掘任務進行解析,並根據任務解析的結果判斷挖掘任務涉及到的數據和應該採用的數據挖掘算法。
數據挖掘任務一般是通過數據挖掘語言定義和解釋的,當前許多研究者提出了自己的數據挖掘語言,這些語言從結構上看都是類SQL語言,如DMQL語言等, 但是並沒有實現挖掘語言的標準化。2000年3月,微軟推出了一個新的數據挖掘語言規範OLE DB for Data Mining,向著數據挖掘語言標準化又邁進了一大步,Amir Netz等詳細介紹了如何將OLE DB for DM規範套用到數據挖掘系統之中。
數據源層
為了提高數據的一致性和完整性,進行數據挖掘前首先應將分散存儲在多個數據源中的數據通過數據清理和數據集成等預處理操作集成到一個統一的資料庫/ 數據倉庫中。為了提高系統的可擴展性,禁止數據源採用的具體資料庫產品,資料庫接口應該採用ODBC、JDBC或OLE DB等技術,以便於更改數據源。趙志宏、錢衛寧等分別提出了基於數據倉庫和大規模資料庫的數據挖掘系統框架及其套用。
資料庫可以通過4種形式集成到數據挖掘系統中:無藕合的,松藕合的,半松藕合的和緊藕合的。最理想的是緊藕合方式,即通過把數據挖掘查詢最佳化成循環的數據挖掘和檢索過程從而將2者結合起來,這樣可以充分利用資料庫所具有的查詢、匯總等數據處理功能,減少數據挖掘系統開發負擔,提高系統的效率。Rosa Meo提出了一種使用數據挖掘語言Mine Rul e 實現與資料庫緊藕合的數據挖掘系統框架。
待挖掘數據層
該層為數據挖掘層提供符合數據挖掘算法要求的待挖掘數據集,待挖掘數據集是由數據源層中與挖掘任務相關的數據經過數據變換和數據規約等數據預處理操作形成的。
除了直接基於資料庫/ 數據倉庫中的數據進行挖掘外,數據挖掘還可以基於在線上分析處理(OLAP)進行,稱作在線上分析挖掘(OLAM)。由於OLAM將2 者結合了起來,充分發揮2 者的優點,所以可以使數據挖掘具有較高的效率和良好的互動性。Jia-wei Han 教授等提出了一種OLAP和DM集成的OLAM系統的結構框架,並且開發出了基於這種結構的一個數據挖掘系統BD Miner。Sanjay Goil等研究了一種基於並行處理技術的可擴展的OLAP和數據挖掘集成的系統體系結構。
挖掘層
該層是數據挖掘系統的核心,該層的具體實現直接關係到整個系統的功能性和可擴展性。數據挖掘主要包括概念/ 類描述、關聯規則分析、分類及預測、聚類分析、孤立點分析和演變分析等幾種類型的模式的挖掘,針對各種類型的模式人們又都提出了多種不同的實現算法,對於一個特定的數據挖掘系統應該包括哪些類型的模式挖掘算法則要由該系統的開發目的及其面向的具體套用領域來決定。
為了提高系統的可擴展性,許多系統採用了組件技術來實現數據挖掘算法及其管理。當前比較成熟的組件技術主要有COM / DCOM、EJB / Java RMI和CORBA / IIOP,組件是指套用系統中可以明確辨識的、具有一定功能的構成模組,一個組件的典型結構包括組件接口和組件實現2 部分,組件接口和組件實現是相互分離的,只要在應用程式中保持統一的接口標準,就可以方便地在系統中加人或替換組件。如劉君強等設計的smart Miner數據挖掘系統中的算法模組採用了組件對象模型COM技術進行構造,並通過算法描述庫為組件提供註冊機制,任何符合COM標準的算法模組可方便地加入到系統中。在史忠植等人研究開發的MSMiner系統中各種數據挖掘核心算法以動態程式庫DLL的形式加以實現,並可以在系統運行過程中動態載入,該系統中還提供了專門的算法管理模組,通過挖掘算法庫管理各種挖掘算法, 並通過元數據的形式提供算法的註冊機制。
知識評價及知識表示層
在將挖掘結果呈現給用戶之前通過知識評價可以有效地去除冗餘的、無用的挖掘結果, 對提高系統的可用性有著重要的意義.知識評價的度量標準主要包括有效性、新穎性、潛在有用性和最終可理解性. 聶艷霞等詳細介紹了知識評價與數據挖掘過程結合的4 種方式。
數據挖掘系統挖掘的知識模式經過知識評價後可以存儲在知識庫中以便重用,為了便於不同數據挖掘系統間知識模式的共享,DMG組織(the data mining)提出了預言模型標記語言PMML(prediction model markup language),PMML是一種基於XML的語言,為數據挖掘產生的預言模型提供了一種統一的定義和描述標準,使得遵循該標準的不同廠商的數據挖掘系統之間可以方便地共享預言模型,提高了模型的可重用性和系統的可擴展性。Wettschereck等介紹了PMML在模型交換中的套用。
上面對集中式數據挖掘系統的各個組成部分的實現技術做了詳細介紹,目前已出現了許多基於集中式結構的商業數據挖掘軟體並開始得到廣泛的套用。比較有影響的商業軟體主要有SAS公司的Enterprise Miner,IBM公司的Intelligent Miner和SPS公司的Clementine等。Enterprise Miner實現了與SAS數據倉庫和OLAP的集成,可以實現從提出數據、抓住數據到得到解答的端到端的知識發現。Intelligent Miner for Data支持對多種數據源的挖掘,如傳統檔案、資料庫、數據倉庫和數據中心等。Clementine採用了數據挖掘過程模型CRISP-DM,能讓用戶輕鬆、容易且有效地執行與管理整個數據挖掘的工作。同時這3 種軟體目前都提供了對PMML 2.1的支持,實現了挖掘模型的共享。
分散式的數據挖掘系統
隨著網路技術和分散式資料庫技術的發展和成熟, 分散式資料庫已經得到越來越廣泛的套用, 原來數據的集中式存儲和管理也逐漸轉變為分散式存儲和管理. 數據存儲方式的變化也必然會促進數據挖掘技術及其系統結構的變化. 由於實際套用中數據的安全性、私有性、保密性以及網路的頻寬限制, 使得首先將分散存儲的數據集中到一個資料庫中再進行挖掘的方法是不可行的, 因此分散式數據挖掘成為在分散式資料庫中進行數據挖掘的最為可行的解決辦法。
步驟
分散式數據挖掘包括以下幾個步驟:
(1)剖分待挖掘數據成P個子集,P為可用的處理器個數,並把每個數據子集傳送到各個處理器;
(2)每個處理器運行數據挖掘算法於其局部數據子集,處理器可以運行不同的數據挖掘算法;
(3)組合各個數據挖掘算法發現的局部知識成全局、一致的發現知識。
研究內容
在分散式數據挖掘中有4 種關鍵技術:數據集中、並行數據挖掘、知識吸收和分散式軟體引擎。
分散式數據挖掘的研究主要包括分散式數據挖掘算法和分散式數據挖掘體系結構的研究2 個方面.當前已經出現不少分散式和並行的數據挖掘算法, 如並行挖掘關聯規則的算法CD (count distribution)、DD (Data distribution),以及PDM 等。在分散式數據挖掘系統結構方面,也已出現了許多基於不同技術的體系結構。如張學明等研究了一種基於CORBA技術並採用多執行緒並行數據挖掘機制的分散式並行體系結構。陳剛對基於移動Agent技術的分散式數據挖掘體系結構進行了研究。侯敬軍等則提出了一種基於Web Services的分散式體系結構,可實現分散式異構環境下的大容量數據的數據挖掘研究了一種用於電子商務套用的基於異構和分散式環境的聯邦式數據挖掘系統。Omer Rana等提出了一種基於組件技術的具有良好可擴展性的分散式數據挖掘系統框架,該框架可以方便地集成第3 方外掛程式和用戶自定義組件。
與集中式數據挖掘系統不同,當前分散式數據挖掘系統還主要處在研究階段,還沒有出現成熟的商業產品。分散式數據挖掘當前的研究熱點主要集中在對超大規模數據集的處理以及提高分散式挖掘系統的整體性能,Grossman等人提出了一種稱為PDS的集成框架,在該框架中首次集成了支持遠程數據分析和分散式數據挖掘的數據服務,設計用於在高性能網路上進行高效數據傳輸的網路協定以及設計用於光纖網路的鏈路服務,該框架可用於進行Gigabyte大數據量的分散式數據挖掘。
發展趨勢
當前已出現的商業化數據挖掘軟體進一步推動了數據挖掘技術的普及和發展,但在實際套用中仍存在不少問題和需要繼續研究改進之處,當前主要的研究方向和發展趨勢包括以下幾個方面:
(1)增強可視化和互動性。一個具有良好的可視化和互動功能的數據挖掘系統可以使用戶直觀地看和理解數據挖掘任務的定義和執行過程,減少用戶挖掘知識的盲目性和挖掘過程中大量無關模式的產生,提高系統的挖掘效率及用戶對挖掘結果的滿意度和可信度。
(2)提高可可擴展性。由於用戶的套用環境是不斷變化的,因此可擴展性對於數據挖掘系統來說非常重要,系統應該支持多種數據源的挖掘以及挖掘算法的可擴展性,允許用戶根據需要加入新的算法。
(3)與特定行業套用相結合。隨著套用環境的發展,通用的數據挖掘系統已越來越不能滿足用戶的需要,用戶如果不了解挖掘算法的特性就很難得出好的模型,因此數據挖掘系統應該和特定的套用緊密結合起來, 為該套用領域提供一個完整的解決方案。
4) 遵循統一標準。儘管目前數據挖掘還沒有形成一套完整的業界標準, 但已出現了一些標準, 如數據挖掘過程標準CRISP DM、預言模型交換標準PMML和Microsoft的OLE DB for DM。遵循統一標準的數據挖掘系統間可以方便地實現挖掘算法和模型的共享。
5) 支持移動環境。目前將數據挖掘和移動計算相結合是一個新的研究領域,因此能夠挖掘移動系統、嵌入式系統和普遍存在的計算設備所產生數據的數據挖掘系統是未來的一個新的發展趨勢。
