
定義
序貫結構是一種卷積神經網路,由多個卷積層堆疊而成,下一層以上一層的輸出作為輸入。序貫結構只有單個輸入和輸出。早期的網路由於梯度彌散的問題,序貫結構無法堆疊很深。隨著“ReLU”激活函式與更為科學的權重初始化策略的提出,序貫結構可以堆疊較深。但過深的網路仍然會出現訓練困難甚至是網路退化的問題。網路退化指的是隨著網路層數的加深,網路性能反而出現下降的現象。雖然如此,序貫結構因其形式簡單,易於訓練和調整,仍然作為一種經典結構被廣泛使用。
VGGNet
Simonyan 等逐次在 AlexNet 中增加卷積層, 比較 6種不同深度的網路,研究網路深度的影響。結果表明神經網路越深,效果越好,當增加到 16、19 層時,效果提升明顯,19 層的網路被稱為 VGG-19。VGGNet嚴格採用 3×3 的卷積核, 步長 (stride) 和填補 (padding)都為 1;採用 2×2 的 max-pooling,步長為 2。相比於ZF Net 7×7 的卷積核,VGGNet 卷積核大小只有 3×3,使得模型參數更少, 而且連續兩層的卷積層使其有 7×7卷積核的效果,之後人們通常也使用 3×3 的卷積核。VGGNet 模型用 Caffe 來實現,利用圖片抖動來增加訓練數據,在圖片分類和物體定位任務都有很好的效果。
卷積神經網路
卷積神經網路(Convolutional Neural Network, CNN)是一種前饋神經網路,它的人工神經元可以回響一部分覆蓋範圍內的周圍單元,對於大型圖像處理有出色表現。
卷積神經網路由一個或多個卷積層和頂端的全連通層(對應經典的神經網路)組成,同時也包括關聯權重和池化層(pooling layer)。這一結構使得卷積神經網路能夠利用輸入數據的二維結構。與其他深度學習結構相比,卷積神經網路在圖像和語音識別方面能夠給出更好的結果。這一模型也可以使用反向傳播算法進行訓練。相比較其他深度、前饋神經網路,卷積神經網路需要考量的參數更少,使之成為一種頗具吸引力的深度學習結構。卷積神經網路包含卷積層、線性整流層、池化層和損失函式層。
卷積層
卷積層(Convolutional layer),卷積神經網路中每層卷積層由若干卷積單元組成,每個卷積單元的參數都是通過反向傳播算法最佳化得到的。卷積運算的目的是提取輸入的不同特徵,第一層卷積層可能只能提取一些低級的特徵如邊緣、線條和角等層級,更多層的網路能從低級特徵中疊代提取更複雜的特徵。
線性整流層
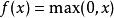 序貫結構
序貫結構線性整流層(Rectified Linear Units layer, ReLU layer)使用線性整流(Rectified Linear Units, ReLU) 作為這一層神經的激勵函式(Activation function)。它可以增強判定函式和整個神經網路的非線性特性,而本身並不會改變卷積層。
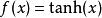 序貫結構
序貫結構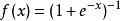 序貫結構
序貫結構事實上,其他的一些函式也可以用於增強網路的非線性特性,如雙曲正切函式 ,或者Sigmoid函式 。相比其它函式來說,ReLU函式更受歡迎,這是因為它可以將神經網路的訓練速度提升數倍,而並不會對模型的泛化準確度造成顯著影響。
池化層(Pooling Layer)
池化(Pooling)是卷積神經網路中另一個重要的概念,它實際上是一種形式的降採樣。有多種不同形式的非線性池化函式,而其中“最大池化(Max pooling)”是最為常見的。它是將輸入的圖像劃分為若干個矩形區域,對每個子區域輸出最大值。直覺上,這種機制能夠有效地原因在於,在發現一個特徵之後,它的精確位置遠不及它和其他特徵的相對位置的關係重要。池化層會不斷地減小數據的空間大小,因此參數的數量和計算量也會下降,這在一定程度上也控制了過擬合。通常來說,CNN的卷積層之間都會周期性地插入池化層。
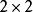 序貫結構
序貫結構池化層通常會分別作用於每個輸入的特徵並減小其大小。最常用形式的池化層是每隔2個元素從圖像劃分出 的區塊,然後對每個區塊中的4個數取最大值。這將會減少75%的數據量。除了最大池化之外,池化層也可以使用其他池化函式,例如“平均池化”甚至“L2-範數池化”等。過去,平均池化的使用曾經較為廣泛,但是最近由於最大池化在實踐中的表現更好,平均池化已經不太常用。
由於池化層過快地減少了數據的大小,文獻中的趨勢是使用較小的池化濾鏡,甚至不再使用池化層。
損失函式層
損失函式層(loss layer)用於決定訓練過程如何來“懲罰”網路的預測結果和真實結果之間的差異,它通常是網路的最後一層。各種不同的損失函式適用於不同類型的任務。例如,Softmax交叉熵損失函式常常被用於在K個類別中選出一個,而Sigmoid交叉熵損失函式常常用於多個獨立的二分類問題。歐幾里德損失函式常常用於結果取值範圍為任意實數的問題。
