簡介
對數線性模型描述的是機率與協變數之間的關係;對數線性模型也用來描述期望頻數與協變數之間的關係。
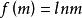 對數線性模型
對數線性模型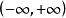 對數線性模型
對數線性模型考慮期望頻數m的取值範圍在0到無窮之間,故需要進行對數變換為 ,使它的取值在 之間。
對數線性模型具有以下形式:
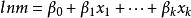 對數線性模型
對數線性模型不過,與logit不同的是,對數模型中沒有解釋變數,是用行列因子的效應參數來表示。
對數線性模型基本思想
對數線性模型分析是把列聯表資料的格線頻數的對數表示為各變數及其互動效應的線性模型,然後運用類似方差分析的基本思想,以及邏輯變換來檢驗各變數及其互動效應的作用大小。
列聯表
(1)作用:分析定類變數和定類變數之間有無關係;
(2)優缺點:不需要確定因變數和自變數。但是,卡方檢驗對三維和三維以上列聯表資料的分析有一定困難,即對混雜變數的控制較難。約束條件少、清晰、可以快速準確進行判斷。失去了對多變數之間的互動聯繫的分析,進行兩變數間關聯分析時缺乏統計控制,不能準確定量描述一個變數對另一個變數的作用幅度。
(3)列聯表的四種類型:
雙向無序列聯表;
單向有序列聯表;
雙向有序且屬性不同的列聯表;
雙向有序且屬性相同的列聯表。
邏輯回歸
(1)作用:分析尺度變數(也可引入類別變數)與二分類別變數之間的因果關係;
(2)優缺點:解決了對混雜變數的控制的問題,而且,它能將因變數與自變數的關係用模型表示出來,清晰易理解。但是,當模型中自變數較多,特別是名義變數較多,或名義變數的類別較多時,分析自變數之間的互動效應就很繁雜,可能需要建立很多啞變數。
對數線性模型
(1)作用:綜合運用方差分析和邏輯回歸中的建模方法,套用於純粹定類變數之間,系統評價各變數間關係和互動作用大小的多元統計方法;
(2)優缺點:可以直接分析各種類型的分類變數,對於名義變數,也不需要事先建立啞變數,可以直接分析變數的主效應和互動效應。對數線性模型不僅可以解決卡方分析中常遇到的高維列聯表的“壓縮”問題,又可以解決logistic回歸分析中多個自變數的互動效應問題。
二維對數線性模型
公式
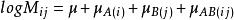 對數線性模型
對數線性模型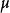 對數線性模型
對數線性模型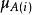 對數線性模型
對數線性模型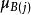 對數線性模型
對數線性模型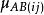 對數線性模型
對數線性模型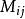 對數線性模型
對數線性模型其中, 為總均值, 主效應A,主效應B,互動效應AB。為第i行第j列格線頻數的理論值或期望頻數值(expected ferquency)。
限制條件:
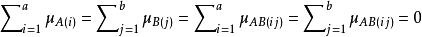 對數線性模型
對數線性模型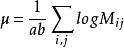 對數線性模型
對數線性模型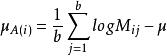 對數線性模型
對數線性模型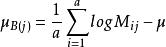 對數線性模型
對數線性模型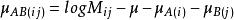 對數線性模型
對數線性模型二維對數線性模型的分類
1、一階互動效應模型
對數線性模型2、完全獨立模型
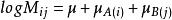 對數線性模型
對數線性模型三維對數線性模型
公式
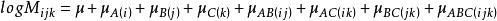 對數線性模型 對數線性模型 對數線性模型 對數線性模型
對數線性模型 對數線性模型 對數線性模型 對數線性模型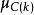 對數線性模型 對數線性模型 對數線性模型
對數線性模型 對數線性模型 對數線性模型其中,為總均值,主效應A,主效應B,,主效應C,等為互動效應。為第i行第j列格線頻數的理論值或期望頻數值(expected ferquency)。
三維對數線性模型的分類
1、二階互動效應模型
2、無二階互動效應模型
3、條件獨立模型
4、聯合獨立模型
5、完全獨立模型
對數線性模型的基本原理
與方差分析相關的
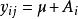 對數線性模型
對數線性模型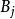 對數線性模型
對數線性模型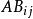 對數線性模型
對數線性模型在多元方差分析中,以二元方差為例:每一個觀測值 的效果+ 的效果+ 互動作用+Ɛ
比數比
比數比是對數線性模型的基礎,而比數比又是由比數計算而來。那么什麼叫做比數呢?比數是一個事件發生的機率與其不發生機率之比,測量了一個事件發生的可能性。這個數值越高說明結果2相對於結果1發生的可能性就越高。
與邏輯變換有關的
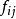 對數線性模型
對數線性模型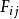 對數線性模型
對數線性模型令R表示行,C表示列, 表示第i行第j列的觀測頻次。那么期望頻次 被設定為一個乘積的函式
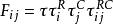 對數線性模型
對數線性模型 對數線性模型
對數線性模型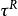 對數線性模型
對數線性模型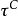 對數線性模型
對數線性模型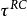 對數線性模型
對數線性模型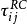 對數線性模型
對數線性模型代表機率裡面的總機率值1, 和 分別代表R和C的邊緣效應, 代表R與C的二維互動效應,而互動效應實質上測量的就是R與C之間的比數比,當 =1的時候就是我們熟悉的獨立模型。 ò相乘形式的不好計算,我們將其取對數。
對數線性模型的假設檢驗
假設檢驗的作用
統計推論中包括參數估計與假設檢驗兩部分,上面我們已經介紹了參數估計,那估計的可信度有多少,還要經過假設檢驗。不經過統計檢驗,研究者便不能肯定得到的參數估計是不是僅僅源於抽樣誤差,因而不能肯定在總體中是否存在相同情況。所有結論只能限於這個樣本之內,不能肯定再抽一個樣本能否得到類似結果。
統計量
似然卡方比,根據相關計算,看原假設是否成立。
貝葉斯信息標準,不同模型而言越小的BIC越好。
對數線性模型的統計檢驗
四種主要檢驗:
1、對於假設模型的整體檢驗;
2、分層效應的檢驗;
3、單項效應的檢驗;
4、單個參數估計的檢驗。
對於假設模型的整體檢驗
採用似然比卡方檢驗(likelihood-ratio chi-square test,標為L )
在樣本量較大時, L2與皮爾遜卡方統計量的值十分接近。 L 優越性:
1、期望頻數採用似然估計方法,因而更加穩健;
2、可以被分解成若干部分,即各項效應都有對應的似然卡方值,並且它們的似然卡方值之和等於整個模型的似然卡方比值。
公式:
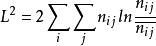 對數線性模型
對數線性模型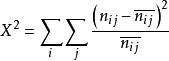 對數線性模型
對數線性模型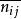 對數線性模型
對數線性模型其中 為估計互動頻數。
整體檢驗的不足之處:
整體檢驗顯著只能說明撤銷的效應項中起碼有一項是有顯著作用的,但不能確定是哪一項顯著。所以,整體檢驗在實際對數線性模型分析中,主要服務於整個檢驗模型的檢驗情況,而確定各項效應時則是通過單項效應的檢驗。且對於一個多階多項效應的複雜模型,採用整體檢驗方式就意味著逐項效應的剔除測試,這樣分析過程效率太低。
分層效應檢驗
當研究中涉及的因素較多時,不僅主效應項會增加,互動效應項增加得更快。例如,四個因素的模型,主效應4個,二階互動效應6項,三階互動效應4項,四階互動效應1項。如此,逐項檢驗篩選重要目標就太繁瑣了。 且在一般情況下,高階互動效應不太容易顯著。因此採用按階次集體檢驗互動效應項的方法十分間接有效。
分層效應檢驗有兩種:
一、某一階及更高階所有互動效應項的集體檢驗,它的檢驗是否顯著表明這一階及以上各階中是否至少有一項是重要的;
二、某一階所有互動效應的集體檢驗,它的檢驗是否顯著表明這一階所有互動效應中是否至少有一項是重要的。 ò前者檢驗比後者綜合性更強。
分層效應檢驗的不足:
整體檢驗或分層檢驗的結果只能說明所有效應中或某一組效應中至少有一項效應具有顯著重要影響。但並不能明確知道究竟是哪一項顯著。
為了了解到底是哪些具體項目顯著,還需要採用單項效應的單獨檢驗。
單項效應的檢驗
SPSS的單項效應檢驗只是在分層模型中對飽和模型分析時提供。它反映的是如果從模型中撤銷一個效應以後對L 變化的檢驗,稱為偏關聯檢驗(tests of PARTIAL associations)。
單項效應檢驗的不足:
在制定對數線性模型時,一個因素中可能不只兩個類別。單項效應檢驗只是肯定這項效應中起碼有一類與其他類存在明顯差別,但並不能提供究竟是哪一類。
因此,需要利用單個參數估計的檢驗來解決這個問題。
單個參數估計的檢驗
均為二類的情況下,參數估計的絕對值相同、各參數估計標準誤相同,因此它們的Z檢驗值的絕對值相同,因此他們的顯著性水平也相同。 如果是三類或者三類以上,經過單項偏關聯檢驗顯著或經篩選保留的互動項中,不一定所有參數都是顯著的。
