集成學習
集成學習(ensemble learning)通過構建並結合多個學習器來完成學習任務,有時也被稱為多分類器系統(multi-classifier system)、基於委員會的學習(committee-based learning)。
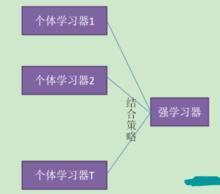 圖1 集成學習示意圖
圖1 集成學習示意圖圖1顯示出集成學習的一般結構:先產生一組“個體學習器”,再用某種策略將它們結合起來。個體學習器通常由一個現有的學習算法從訓練數據中產生,例如C4.5決策算法、BP神經網路算法等,此時集成中只包含同種類型的個體學習器,例如“決策樹集成”中全是決策樹,“神經網路集成”中全是神經網路,這樣的集成是“同質”的。同質集成中的個體學習器亦稱為“基學習器”。相應的學習算法稱為“基學習算法”。集成也可包含不同類型的個體學習器,例如,同時包含決策樹和神經網路,這樣的集成稱為“異質”的。異質集成中的個體學習器由不同的學習算法生成,這時就不再有基學習算法,常稱為“組件學習器”或直接稱為個體學習器。
集成學習通過將多個學習器進行結合,常可獲得比單一學習器更加顯著的泛化性能。這對“弱學習器”尤為明顯。因此集成學習的理論研究都是針對弱學習器進行的,而基學習器有時也被直接稱為弱學習器。但需注意的是,雖然從理論上說使用弱學習器集成足以獲得很好的性能,但在實踐中出於種種考慮,例如希望使用較少的個體學習器,或是重用一些常見學習器的一些經驗等,人們往往會使用比較強的學習器。
在一般經驗中,如果把好壞不等的東西摻到一起,那么通常結果會是比最壞的要好些,比最好的要壞一些。集成學習把多個學習器結合起來,如何能得到比最好的單一學習器更好的性能呢?
分類器集成示例
考慮一個簡單的例子:在二分類任務中,假定三個分類器在三個測試樣本的表現如圖2,其中,√ 表示分類正確,× 表示分類錯誤,集成學習的結果通過投票法產生,即“少數服從多數”。在圖2(a)中,每個分類器只有66.6%的精度,但集成學習卻達到了100%;在圖2(b)中,三個分類器沒有差別,集成之後性能沒有提高;在圖2(c)中,每個分類器只有33.3%的精度,集成學習變得更糟。這個例子顯示出,要想獲得好的集成,個體學習器應“好而不同”,即個體學習器要有一定的“準確性”,即學習器不能太壞,並且要有“多樣性”,即學習器間具有差異。
 圖2 集成個體應“好而不同”(hi表示第i個分類器)
圖2 集成個體應“好而不同”(hi表示第i個分類器)分析:
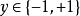 分類器集成
分類器集成 分類器集成
分類器集成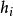 分類器集成
分類器集成考慮二分類問題 和真實函式 f ,假定基分類器的錯誤率為 ,即對每個基分類器 有:
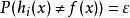 分類器集成
分類器集成假設集成通過簡單投票法結合T個基分類器,若有超過半數的基分類器正確,則集成分類就正確:
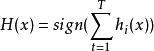 分類器集成
分類器集成假設分類器的錯誤率相互獨立,則由Hoeffding 不等式可知,集成的錯誤率為:
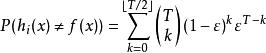 分類器集成
分類器集成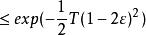 分類器集成
分類器集成上式顯示出,隨著集成中個體分類器數目的增大,集成的錯誤率將指數級下降,最終趨向於零。
然而我們必須注意到,上面的分析中有一個關鍵性的假設:基學習器的誤差相互獨立。在現實任務中,個體學習器是為解決同一個問題訓練出來的,它們顯然不可能獨立。事實上,個體學習器的“準確性”和“多樣性”本身就存在著衝突。一般的,準確性很高之後,要增加多樣性就必須犧牲準確性。
事實上,如何產生並結合“好而不同”的個體學習器,恰恰是 集成學習研究的核心。
結合策略
平均法
對於數值類的回歸預測問題,通常使用的結合策略是平均法,也就是說,對於若干和弱學習器的輸出進行平均得到最終的預測輸出。
最簡單的平均是算術平均,也就是說最終預測是
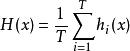 分類器集成
分類器集成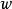 分類器集成
分類器集成如果每個個體學習器有一個權重 ,則最終預測是
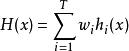 分類器集成
分類器集成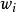 分類器集成 分類器集成
分類器集成 分類器集成其中,其中 是個體學習器 的權重,通常有
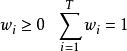 分類器集成
分類器集成投票法
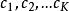 分類器集成
分類器集成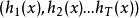 分類器集成
分類器集成對於分類問題的預測,我們通常使用的是投票法。假設我們的預測類別是,對於任意一個預測樣本x,我們的T個弱學習器的預測結果分別是。
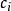 分類器集成
分類器集成最簡單的投票法是相對多數投票法,也就是我們常說的少數服從多數,也就是T個弱學習器的對樣本x的預測結果中,數量最多的類別為最終的分類類別。如果不止一個類別獲得最高票,則隨機選擇一個做最終類別。
稍微複雜的投票法是絕對多數投票法,也就是我們常說的要票過半數。在相對多數投票法的基礎上,不光要求獲得最高票,還要求票過半數。否則會拒絕預測。
更加複雜的是加權投票法,和加權平均法一樣,每個弱學習器的分類票數要乘以一個權重,最終將各個類別的加權票數求和,最大的值對應的類別為最終類別。
學習法
對弱學習器的結果做平均或者投票,相對比較簡單,但是可能學習誤差較大,於是就有了學習法這種方法。對於學習法,代表方法是stacking,當使用stacking的結合策略時, 我們不是對弱學習器的結果做簡單的邏輯處理,而是再加上一層學習器,也就是說,我們將訓練集弱學習器的學習結果作為輸入,將訓練集的輸出作為輸出,重新訓練一個學習器來得到最終結果。
在這種情況下,我們將弱學習器稱為初級學習器,將用於結合的學習器稱為次級學習器。對於測試集,我們首先用初級學習器預測一次,得到次級學習器的輸入樣本,再用次級學習器預測一次,得到最終的預測結果。
典型集成學習方法
根據個體學習器的不同,目前集成學習方法大致可分為兩大類:即個體學習器間存在強依賴關係,必須串列生成的序列化方法以及個體學習器間不存在強依賴關係、可同時生成的並行化方法;前者代表是Boosting,後者代表是Bagging和“隨機森林”。
