介紹
在貝葉斯統計推斷中,不確定數量的先驗機率分布是在考慮一些因素之前表達對這一數量的置信程度的機率分布。例如,先驗機率分布可能代表在將來的選舉中投票給特定政治家的選民相對比例的機率分布。未知的數量可以是模型的參數或者是潛在變數。
貝葉斯定理計算先驗和似然函式的重新歸一化的逐次積,產生了後驗機率分布,它是給定數據的不確定量的條件分布。
類似地,隨機事件或不確定命題的先驗機率是在考慮任何相關證據之前分配的無條件機率。
可以使用多種方法創建優先權。可根據先前的實驗確定過去的信息。先前的經驗可以從經驗豐富的專家的純粹主觀評估中引出。當沒有信息可用時,可以創建一個不了解的先驗,以反映結果之間的平衡。還可以根據某些原理來選擇優先權,例如對稱性或最大化給定約束的熵;例子是傑弗里斯之前或貝爾納先前的參考例子。當存在共軛先驗族時,從該族中選擇先前的方法簡化後驗分布的計算。
先前分布的參數是一種超參數。例如,如果使用beta分布來模擬伯努利分布參數p的分布,則:
p是底層系統的參數(伯努利分布),α和β是先前分布(β分布)的參數。
超參數本身可能具有表達對其值的信念的超級派生分布。具有多個先前級別的貝葉斯模型稱為分層貝葉斯模型。
信息先驗
信息先驗表達了關於變數的具體的明確信息。舉一個例子:明天中午以前的溫度分布。合理的方法是將之前的常態分配預期值等於今天的中午溫度,其方差等於大氣溫度的日常變化,或者是一年中的那一天的溫度分布。
這個例子有許多先驗的共同特徵,即從一個問題(今天的溫度)的後面,成為另一個問題(明天的溫度)的先例;已經被考慮的先前存在的證據是以前的一部分,並且隨著越來越多的證據積累,後者主要由證據而不是任何原始假設確定,前提是原始假設承認證據是什麼的可能性提示。術語“先前”和“後”通常是相對於特定的基準或觀察。
不知情的先驗
不知情的先驗表示關於變數的模糊或一般信息。術語“不知情的先驗”有些被稱為誤稱。這樣的先驗也可能被稱為不是非常有前途的先驗,即不是主觀地引出的目標。
不知情的先驗可以表達“客觀”信息,例如“變數為正”或“變數小於某個限制”。確定不知情的先驗的最簡單和最古老的規則是“冷漠”的原則,它將所有可能性賦予相等的機率。在參數估計問題中,使用不知情的先驗通常產生與傳統統計分析不太大的結果,因為似然函式通常產生比不知情的先驗的更多信息。
發現先驗機率已經有一些嘗試,即在某種意義上,由不確定性狀態的性質邏輯需要的機率分布;這些是哲學爭論的課題,貝葉斯大概分為兩個:“客觀的貝葉斯”,他們認為這樣的先修存在於許多有用的情境,“主觀的貝葉斯”誰相信在實踐中,先驗者通常代表主觀的判斷判斷不能被嚴格證明(Williamson 2010)。也許對於客觀的貝葉斯主義最有力的論據是Edwin T. Jaynes給出的,主要是基於對稱性的後果和最大熵原理。
作為先驗的一個例子,考慮一個人知道一個球隱藏在三個杯子A,B或C之一的情況下,但是沒有關於其位置的其他信息。在這種情況下,p(A)= p(B)= p(C)= 1/3的均勻先驗似乎是唯一合理的選擇。我們可以看到,如果我們交換杯子的標籤(“A”,“B”和“C”),問題依然如此。因此,選擇一個先驗的選擇是奇怪的,其中標籤的排列將導致我們對於哪個杯子將被發現的預測的改變;先驗是唯一保留這種不變性的統一。如果一個人接受這個不變性原則,那么可以看出,統一之前是邏輯上正確的。應該指出的是,這個以前是“客觀的”,是代表一種特定的知識狀態的正確選擇,但是不是客觀的,而是作為一個觀察者獨立的世界特徵:實際上球存在於一個特定的杯子下,如果有觀察者對系統知識有限,那么在這種情況下說出機率也是有意義的。
一個更有爭議的例子,傑恩斯發表了一個基於謊言組的論證(Jaynes 1968),這表明事先表示對機率的完全不確定性應該是霍爾丹之前的p (1-p) 。 傑恩斯給出的例子是在實驗室中找到一種化學物質,並詢問在反覆實驗中是否會溶解在水中。霍爾丹之前給出了p = 0和p = 1的最大重量,表明樣品將溶解或不溶解,相等可能性。然而,如果已經觀察到化學品的樣品溶解在一個實驗中,而不是溶解在另一個實驗中,則先前將其更新為間隔[0,1]上的均勻分布。這是通過將貝葉斯定理套用於使用上述以前的一種溶解觀察和不溶解觀察的數據集而獲得的。霍爾丹之前是一個不正確的事先分配(意味著它不整合到1),如果有限數量的觀察結果給出相同的結果,那么將100%的機率內容放在p = 0或p = 1。哈羅德·傑夫雷斯(Harold Jeffreys)設計了一種系統的設計方法,用於為伯努利隨機變數提供例如Jeffreys之前的p (1-p) 設計不了解的適當先驗[需要澄清不需要每個人都同意這一說法。
如果參數空間X具有保留我們的貝葉斯知識狀態的自然組織結構(Jaynes,1968),則可以構建與哈爾度量成正比的先驗。這可以被看作是在上面的例子中用於證明前三杯之前的均勻性的不變性原理的概括。例如,在物理學中,我們可能期望實驗將給出相同的結果,而不管我們選擇坐標系的原點。這導致X上的翻譯組的組結構,其將先驗機率確定為恆定不正確的先驗。類似地,一些測量對於任意尺度的選擇(例如,是否使用厘米或英寸,物理結果應該相等)自然不變。
不正確的先驗
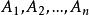 先驗機率
先驗機率讓事件相互排斥的。 如果貝葉斯定理寫為
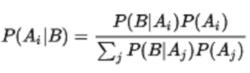 先驗機率
先驗機率那么很明顯,如果所有先驗機率P(Ai)和P(Aj)乘以給定常數,則將獲得相同的結果;連續隨機變數也是如此。 如果分母中的總和收斂,則即使先前的值不存在,後驗機率仍然將(或積分)為1,因此,先驗者可能只需要以正確的比例來指定。 進一步考慮這個想法,在許多情況下,以前的值的總和或積分可能甚至不需要是有限的,以獲得後驗機率的合理答案。 在這種情況下,先前被稱為不正確的。 然而,如果先驗不正確,則後驗分布不需要是適當的分布。 從事件B獨立於所有Aj的情況就清楚了。
統計學家有時使用不正當的先驗作為不知情的先驗。 例如,如果他們需要一個隨機變數的平均值和方差的先驗分布,則可以假設p(m,v)〜1 / v(對於v> 0),這表明平均值的任何值都是“ 可能“,並且正方差的值變為與其值成反比的”較不可能“。 許多作者(Lindley,1973; De Groot,1937; Kass和Wasserman,1996)說明,由於它們不是機率密度,它們會冒出過度解釋這些先驗的危險。 只要它們對所有觀察結果有明確的定義,才能在相應的後驗中找到唯一的相關性。
其他相關知識
先驗機率的分類
利用過去歷史資料計算得到的先驗機率,稱為客觀先驗機率;
當歷史資料無從取得或資料不完全時,憑人們的主觀經驗來判斷而得到的先驗機率,稱為主觀先驗機率。
先驗機率的條件
先驗機率是通過古典機率模型加以定義的,故又稱為古典機率。古典機率模型要求滿足兩個條件:(1)試驗的所有可能結果是有限的;(2)每一種可能結果出現的可能性(機率)相等。若所有可能結果的總數為N,隨機事件A包括n個可能結果,那么隨機事件A出現的機率為n/N。
區別
先驗機率不是根據有關自然狀態的全部資料測定的,而只是利用現有的材料(主要是歷史資料)計算的;後驗機率使用了有關自然狀態更加全面的資料,既有先驗機率資料,也有補充資料;
先驗機率的計算比較簡單,沒有使用貝葉斯公式;而後驗機率的計算,要使用貝葉斯公式,而且在利用樣本資料計算邏輯機率時,還要使用理論機率分布,需要更多的數理統計知識。
