
歷史
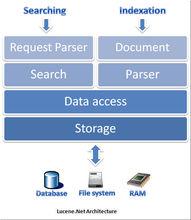 Lucene 圖片
Lucene 圖片Lucene最初是由Doug Cutting開發的,在SourceForge的網站上提供下 載。在2001年9月做為高質量的開源Java產品加入到Apache軟體基金會的 Jakarta家族中。隨著每個版本的發布,這個項目得到明顯的增強,也吸引了更多的用戶和開發人員。2004年7月,Lucene1.4版正式發布,10月的1.4.2版本做了一次bug修正。表1.1顯示了Lucene的發布歷史。
版本 發布日期 里程碑
0.01 2000年3月 第一個開源版本(SourceForge)
1.0 2000年10月
1.01b 2001年7月 最後的SourceForge版本
1.2 2002年6月 第一個Apache Jakarta版本
1.3 2003年12月 複合索引格式,查詢分析器增加,遠程搜尋,token定位,可擴展的API
1.4 2004年7月 Sorting, span queries, term vectors
1.4.1 2004年8月 排序性能的bug修正
1.4.2 2004年10月 IndexSearcher optimization and misc. fixes
1.4.3 2004年冬 Misc. fixes2.4.1 2009年3月8日發布新版本
2.3.0 2008年1月 更新為2.3.0
2.4.0 2008年10月 更新為2.4.0
2.4.1 2009年 5月 更新為 2.4.1
2.9.0 2009年9月25號 更新為2.9.0
2.9.1 2009年11月6號 更新為2.9.1
3.0.0 2009年11月25號 更新為3.0.0
3.0.1 2010年2月26號 更新為3.0.1
3.0.2 2010年6月18號 更新為3.0.2
3.0.3 2010年12月3號 更新為3.0.3
3.3.0 2011年7月初 更新為3.3.0
3.4.0 2011年9月14日 更新為3.4.0
3.5.0 2011年11月26日 更新為3.5.0
3.6.0 2012年4月12日更新為3.6.0
3.6.1 2012年7月23日更新為3.6.1
4.0 2012年10月12日更新為4.0
4.2 2013年3月11日更新為4.2
4.3.1 2013-06-18發布
4.4 2013年7月23日更新到4.4
4.5 2013年10月5日更新到4.5
5.0.0 2015年2月20日更新到5.0.0
創始人
Lucene['lusen]的原作者是Doug Cutting,他是一位資深全文索引/檢索專家,曾經是V-Twin搜尋引擎的主要開發者,後在Excite擔任高級系統架構設計師,當前從事於一些Internet底層架構的研究。早先發布在作者自己的部落格上,他貢獻出Lucene的目標是為各種中小型套用程式加入全文檢索功能。後來發布在SourceForge,2001年年底成為apache軟體基金會jakarta的一個子項目。
特點優勢
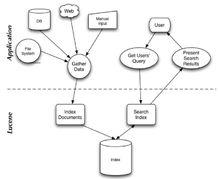 Lucene
Lucene作為一個開放原始碼項目,Lucene從問世之後,引發了開放原始碼社群的巨大反響,程式設計師們不僅使用它構建具體的全文檢索套用,而且將之集成到各種系統軟體中去,以及構建Web套用,甚至某些商業軟體也採用了Lucene作為其內部全文檢索子系統的核心。apache軟體基金會的網站使用了Lucene作為全文檢索的引擎,IBM的開源軟體eclipse[9]的2.1版本中也採用了Lucene作為幫助子系統的全文索引引擎,相應的IBM的商業軟體Web Sphere[10]中也採用了Lucene。Lucene以其開放原始碼的特性、優異的索引結構、良好的系統架構獲得了越來越多的套用。
Lucene是一個高性能、可伸縮的信息搜尋(IR)庫。它可以為你的應用程式添加索引和搜尋能力。Lucene是用java實現的、成熟的開源項目,是著名的Apache Jakarta大家庭的一員,並且基於Apache軟體許可 [ASF, License]。同樣,Lucene是當前非常流行的、免費的Java信息搜尋(IR)庫。
突出的優點
Lucene作為一個全文檢索引擎,其具有如下突出的優點:
(1)索引檔案格式獨立於套用平台。Lucene定義了一套以8位位元組為基礎的索引檔案格式,使得兼容系統或者不同平台的套用能夠共享建立的索引檔案。
(2)在傳統全文檢索引擎的倒排索引的基礎上,實現了分塊索引,能夠針對新的檔案建立小檔案索引,提升索引速度。然後通過與原有索引的合併,達到最佳化的目的。
(3)優秀的面向對象的系統架構,使得對於Lucene擴展的學習難度降低,方便擴充新功能。
(4)設計了獨立於語言和檔案格式的文本分析接口,索引器通過接受Token流完成索引檔案的創立,用戶擴展新的語言和檔案格式,只需要實現文本分析的接口。
(5)已經默認實現了一套強大的查詢引擎,用戶無需自己編寫代碼即可使系統可獲得強大的查詢能力,Lucene的查詢實現中默認實現了布爾操作、模糊查詢(Fuzzy Search[11])、分組查詢等等。
面對已經存在的商業全文檢索引擎,Lucene也具有相當的優勢。
首先,它的開發原始碼發行方式(遵守Apache Software License[12]),在此基礎上程式設計師不僅僅可以充分的利用Lucene所提供的強大功能,而且可以深入細緻的學習到全文檢索引擎製作技術和面向對象編程的實踐,進而在此基礎上根據套用的實際情況編寫出更好的更適合當前套用的全文檢索引擎。在這一點上,商業軟體的靈活性遠遠不及Lucene。
其次,Lucene秉承了開放原始碼一貫的架構優良的優勢,設計了一個合理而極具擴充能力的面向對象架構,程式設計師可以在Lucene的基礎上擴充各種功能,比如擴充中文處理能力,從文本擴充到HTML、PDF[13]等等文本格式的處理,編寫這些擴展的功能不僅僅不複雜,而且由於Lucene恰當合理的對系統設備做了程式上的抽象,擴展的功能也能輕易的達到跨平台的能力。
最後,轉移到apache軟體基金會後,藉助於apache軟體基金會的網路平台,程式設計師可以方便的和開發者、其它程式設計師交流,促成資源的共享,甚至直接獲得已經編寫完備的擴充功能。最後,雖然Lucene使用Java語言寫成,但是開放原始碼社區的程式設計師正在不懈的將之使用各種傳統語言實現(例如.net framework[14]),在遵守Lucene索引檔案格式的基礎上,使得Lucene能夠運行在各種各樣的平台上,系統管理員可以根據當前的平台適合的語言來合理的選擇。
前提
lucene有7個包需要導入:analysis,document,index,queryParser,search,store,util
搜尋
IndexSearcher searcher= new IndexSearcher("E:/index");
Query query = new TermQuery(new Term("title", "lucene"));//單個位元組查詢
//Query query = new FuzzyQuery(new Term("title", "lucene"));//模糊查詢
//Query query = new WildcardQuery(new Term("title", "lu*"));//通配符查詢 ?代表一個字元,*代表0到多個字元
//BooleanQuery query = new BooleanQuery();//條件查詢
//BooleanQuery qson1 = new BooleanQuery();
//Query q1 = new TermQuery(new Term("title", "lucene"));
//qson1.add(q1, Occur.MUST);//MUST是必須滿足的
//BooleanQuery qson2 = new BooleanQuery();
//Query q2= new TermQuery(new Term("sex", "woman"));
//qson2 .add(q2, Occur.MUST_NOT);//MUST_NOT是必須不滿足
//query.add(qson1, Occur.SHOULD);
//query.add(qson2, Occur.SHOULD);//SHOULD代表滿足qson1或者滿足qson2都可以
//PhraseQuery query = new PhraseQuery();//近距離查詢
//query.setSlop(5);//距離設定為5
//query.add(new Term("title", "lucene"));
//query.add(new Term("title", "introduction"));//查詢出title中lucene和introduction距離不超過5個字元的結果
//Query query = new PrefixQuery(new Term("title", "lu"));//WildcardQuery的lu*一樣
//RangeQuery query = new RangeQuery(new Term("time", "50"),new Term("time", "60"), true);
//true代表[50,60],false代表(50,60)
Hits hits = searcher.search(query);
for (int i = 0; i < hits.length(); i++) {
Document d = hits.doc(i);
String title= d.get("title");
System.out.print(title+ " ");
}
這樣,基本上就可以使用了
註:以上代碼為lucene早些版本的寫法。lucene3.02的寫法有所改變。
建立索引
IndexWriter writer = new IndexWriter("E:/index", new StandardAnalyze(),true,MaxFieldLength.UNLIMITED); //true代表覆蓋原先數據,maxFieldLength用來限制Field的大小
Document doc = new Document();
doc.add(new Field("title", "lucene introduction", Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
doc.add(new Field("time", "60", Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.addDocument(doc);
writer.optimize(); //最佳化
writer.close();
