![deepweb[網際網路術語]](/img/1/957/nBnauM3XzITNyYTOwMDO5kDMzQTM4ITM0IDMxADMwAzMwIzLzgzLxMzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg "deepweb[網際網路術語]")
基本解釋
 deepweb
deepweb整個Web看似雜亂無章,但如果按其所蘊涵信息的“深度”可以劃分為SurfaceWeb和DeepWeb兩大部分.Surfaceweb是指通過超連結可以被傳統搜尋引擎索引到的頁面的集合.DeepWeb是指Web中不能被傳統的搜尋引擎索引到的那部分內容.廣義上來說,DeepW eb的內容主要包含4個方面:
(1)通過填寫表單形成對後台線上資料庫的查詢而得到的動態頁面;
(2)由於缺乏被指向的超連結而沒有被搜尋引擎索引到的頁面,大約占整個比例的21.3%;
(3)需要註冊或其它限制才能訪問的內容;
(4)Web上可訪問的非網頁檔案,比如圖片檔案、PDF和Word文檔等.
而在實際中套用中,人們則更關注於DeepWeb中的第一部分內容.其原因不難理解.這部分內容對結構化數據的集成更有意義,可以採用的技術也更豐富.DeepWeb數據集成也主要是指對結構化信息的集成.我們同時把Web中可訪問的線上資料庫稱為Web資料庫或WDB.這些內容只有在被查詢時才會由W eb伺服器動態生成頁面,把結果返回給訪問者,因此沒有超連結指向這些頁面,這是和那些可以被直接訪問的靜態頁面的根本區別.隨著Web相關技術的日益成熟和DeepWeb所蘊含信息量的快速增長,通過對web資料庫的訪問逐漸成為獲取信息的主要手段,而對DeepWeb的研究也越來越受到人們的關注.
深網資源
動態內容
未被連結內容
私有網站
ContextualWeb
被限制訪問內容
腳本化內容
非HTML/文本內容
抓取方式
研究人員探尋了如何自動抓取深網內容。
2001年,SriramRaghavan和HectorGarcia-Molina發明了一個從用戶請求界面表格收集關鍵字的深網抓取模型並且抓取深網資源。加利福尼亞大學洛杉磯分校的AlexandrosNtoulas、PetrosZerfos和JunghooCho創建了一個自動生成有意義的查詢詞的程式。
商業搜尋引擎已經開始使用以上兩種方法之一抓取深網。Sitemap協定(始創於Google)和modoai是允許搜尋引擎和其他網路服務探索深網解決方法。以上兩種解決方法允許網路服務主動公布網址,這對於他們來說是容易的,因而允許自動探尋資源而不直接通過網路表面的連結。Google的深網探尋系統預先計算每個HTML表單並且添加結果HTML頁面到Google搜尋引擎索引。在這個系統里,使用三種方法計算提交詞:為輸入搜尋選擇關鍵字允許的輸入值、確定是否只接受特定的值(例如時間)和 選擇少量的組合生成適合納入網站的搜尋索引網址。
特徵發展
 deepweb
deepweb400~500倍.(2)對DeepWeb數據的訪問量比SurfaceWeb要高出15%.(3)DeepWeb蘊含的信息量比SurfaceWeb的質量更高.
(4)DeepWeb的增長速度要遠大於SurfaceWeb.
(5)超過50%的DeepWeb的內容是特定於某個域的,即面向某個領域.
(6)整個DeepWeb覆蓋了現實世界中的各個領域,比如商業、教育、政府等等.
(7)DeepWeb上95%的信息是可以公開訪問的,即免費獲取.
整
 deepweb
deepwebUIUC大學在2004年4月對整個DeepWeb做了一次較為準確的估算,推測整個Web上有307000個提供Web資料庫的網站、450000個Web資料庫,比Brightplanet在2000年估計的50000個資料庫網站的數目增長了6倍多.
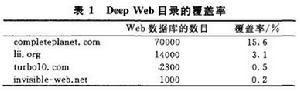
DeepWeb中的Web資料庫不但數量眾多,而且覆蓋了現實世界的各個領域.一些專門的機構,像CompletePlanet和InvisibleWeb等,構建了DeepWeb目錄,按現實世界的領域對DeepWeb的內容做了分類,主要包括商業與經濟、計算機與網際網路、新聞媒體、娛樂等一共十幾個分類.這只是巨觀的分類,每個分類下面還有小的分類,比如科學可以繼續分為社會科學與自然科學,而自然科學又可分為若干學科.在表1中可以看出,儘管這些網站對Web資料庫進行了細緻的分類,但所列出的Web資料庫僅僅只是整個web資料庫的很小的一個比例(即使最大的CompletePlanet也只有15.6%.因此從巨觀上對Web資料庫按現實世界的領域分類做一個定量的分析是十分迫切而且必要的工作.
每個查詢接口支持在若干個屬性上進行查詢,比如要查詢某一本圖書,可以根據書名、作者、價格等.這些屬性就構成了查詢接口的模式(Schema)信息.查詢接口模式的大小是指屬性的數目.查詢接口顧名思義是外部訪問Web資料庫的門戶,是從Web資料庫中獲取數據的主要途徑,因此在web資料庫研究領域,對查詢接口的模式信息的研究占有極其重要的地位.
對DeepWeb信息的訪問是通過在查詢接口上提交查詢,這和對搜尋引擎的訪問在某種程度上來說是相似的,但DeepWeb數據和搜尋引擎二者之間是有著很大區別的:
(1)搜尋引擎搜尋結果是網頁,而Deepweb中的搜尋結果主要是結構化的數據。
(2)Web資料庫通常有複雜的接口,而搜尋引擎的接口較為簡單,一般是關鍵字搜尋.
(3)搜尋引擎對結果的排序是根據搜尋結果與所提交查詢的相似性,Web資料庫則是根據結果中對DeepWeb中信息的獲取主要的途徑是通過某個屬性的值。
