
特點
輕
包括完整詞庫的Orea敏感詞處理系統僅147KB,在保證高命中率的前提下,實現了體積的最小化。
快
得益於對詞庫建設和代碼最佳化的高度重視,Orea敏感詞處理系統可以高速完成對敏感詞的識別、替換工作。在處理1k字時,在虛擬主機當中的平均處理耗時達到10^(-4)級,比Double-ArrayTree(DAR)算法更快(快20%)。
準
Orea敏感詞處理系統內置的OYW處理引擎可以高效判斷敏感詞是否存在(防誤報),能夠輕鬆應對敏感詞被空格、標點或者混淆詞隔開的情況(防漏報)。
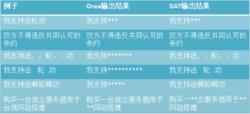 Orea敏感詞處理系統與DAT比較
Orea敏感詞處理系統與DAT比較Orea敏感詞處理系統與DAT比較
上表中的一二兩例反應了Orea對真敏感辭彙的鑑別能力,例三、四、五反應了Orea對敏感詞被惡意隔開時,仍能準確識別。最後一例中,DAT對敏感詞也進行了判別,但是在替換的時候,它採取了兩個一起替換的方法,所以導致誤報。Orea通過重寫替換函式,可以實現高效定點替換。
狠
Orea會判斷敏感詞在文本中所占的比重,當所占比重超過一定限度時,Orea會直接讓這一文本作廢,返回系統提示文本。當文本中含多處敏感詞時,Orea亦能一網打盡。
Orea開源計畫
Orea目前已開源,如果您只是研究、學習用途,您可以到github下載原始碼。
