 查詢點和它的最近鄰-KNN
查詢點和它的最近鄰-KNN簡介
是K最鄰近結點算法(k-Nearest Neighbor algorithm)的縮寫形式,是電子信息分類器算法的一種。KNN方法對包容型數據的特徵變數篩選尤其有效。
算法描述
該算法的基本思路是:在給定新文本後,考慮在訓練文本集中與該新文本距離最近(最相似)的 K 篇文本,根據這 K 篇文本所屬的類別判定新文本所屬的類別,具體的算法步驟如下:
一、:根據特徵項集合重新描述訓練文本向量
二、:在新文本到達後,根據特徵詞分詞新文本,確定新文本的向量表示
三、:在訓練文本集中選出與新文本最相似的 K 個文本,計算公式為:
【圖】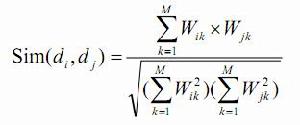 公式(1)-KNN
公式(1)-KNN
其中,K 值的確定目前沒有很好的方法,一般採用先定一個初始值,然後根據實驗測試的結果調整 K 值,一般初始值定為幾百到幾千之間。
四、:在新文本的 K 個鄰居中,依次計算每類的權重,計算公式如下:
【圖】】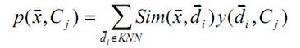 公式(2)-KNN
公式(2)-KNN
其中, x為新文本的特徵向量, Sim(x,di)為相似度計算公式,與上一步驟的計算公式相同,而y(di,Cj)為類別屬性函式,即如果di 屬於類Cj ,那么函式值為 1,否則為 0。
五、:比較類的權重,將文本分到權重最大的那個類別中。
除此以外,支持向量機和神經網路算法在文本分類系統中套用得也較為廣泛,支持向量機的基本思想是使用簡單的線形分類器劃分樣本空間。對於在當前特徵空間中線形不可分的模式,則使用一個核函式把樣本映射到一個高維空間中,使得樣本能夠線形可分。
而神經網路算法採用感知算法進行分類。在這種模型中,分類知識被隱式地存儲在連線的權值上,使用疊代算法來確定權值向量。當網路輸出判別正確時,權值向量保持不變,否則進行增加或降低的調整,因此也稱為獎懲法。
不足
該算法在分類時有個主要的不足是,當樣本不平衡時,如一個類的樣本容量很大,而其他類樣本容量很小時,有可能導致當輸入一個新樣本時,該樣本的K個鄰居中大容量類的樣本占多數。因此可以採用權值的方法(和該樣本距離小的鄰居權值大)來改進。該方法的另一個不足之處是計算量較大,因為對每一個待分類的文本都要計算它到全體已知樣本的距離,才能求得它的K個最近鄰點。目前常用的解決方法是事先對已知樣本點進行剪輯,事先去除對分類作用不大的樣本。該算法比較適用於樣本容量比較大的類域的自動分類,而那些樣本容量較小的類域採用這種算法比較容易產生誤分。
圖示
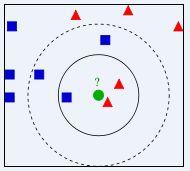 圖示-KNN
圖示-KNN右圖中,綠色圓要被決定賦予哪個類,是紅色三角形還是藍色四方形?如果K=3,由於紅色三角形所占比例為2/3,綠色圓將被賦予紅色三角形那個類,如果K=5,由於藍色四方形比例為3/5,因此綠色圓被賦予藍色四方形類。
主要套用領域
·文本分類
·聚類分析
·數據挖掘
·機器學習
·預測分析
·減少維度
·模式識別
·圖像處理
