
詳細解釋
資料庫知識發現(knowledgediscoveryindatabase,KDD)的研究非常活躍。在上面的定義中,涉及幾個需要進一步解釋的概念:“數據集”、“模式”、“過程”、“有效性”、“新穎性”、“潛在有用性”和“最終可理解性”。數據集是一組事實F(如關係資料庫中的記錄)。模式是一個用語言L來表示的一個表達式E,它可用來描述數據集F的某個子集凡上作為一個模式要求它比對數據子集FE的枚舉要簡單(所用的描述信息量要少)。過程在KDD中通常指多階段的處理,涉及數據準備、模式搜尋、知識評價以及反覆的修改求精;該過程要求是非平凡的,意思是要有一定程度的智慧型性、自動性(僅僅給出所有數據的總和不能算作是一個發現過程)。有效性是指發現的模式對於新的數據仍保持有一定的可信度。新穎性要求發現的模式應該是新的。潛在有用性是指發現的知識將來有實際效用,如用於決策支持系統里可提高經濟效益。最終可理解性要求發現的模式能被用戶理解,它主要是體現在簡潔性上。有效性、新穎性、潛在有用性和最終可理解性綜合在一起稱為興趣性。
由於知識發現是一門受到來自各種不同領域的研究者關注的交叉性學科,因此導致了很多不同的術語名稱。除了KDD外,主要還有如下若干種稱法:“數據挖掘”(datamining),“知識抽取”(informationextraction)、“信息發現”(informationdiscovery)、“智慧型數據分析”(intelligentdataanalysis)、“探索式數據分析”(exploratorydataanalysis)、“信息收穫”(Informationharvesting)和“數據考古”(dataarchaeology)等等。其中,最常用的術語是“知識發現”和“數據挖掘”。相對來講,數據挖掘主要流行於統計界(最早出現於統計文獻中)、數據分析、資料庫和管理信息系統界;而知識發現則主要流行於人工智慧和機器學習界。
隨著參與人員的不斷增多,KDD於1995年由國際研討會發展成為國際會議年會。
基本過程
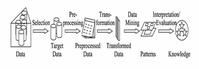 KDD基本過程
KDD基本過程作為一個KDD的工程而言,KDD通常包含一系列複雜的挖掘步驟.Fayyad,Piatetsky-Shapiro和Smyth在1996年合作發布的論文<FromDataMiningtoknowledgediscovery>中總結出了KDD包含的5個最基本步驟(如圖).
1:selection:在第一個步驟中我們往往要先知道什麼樣的數據可以套用於我們的KDD工程中.
2:pre-processing:當採集到數據後,下一步必須要做的事情是對數據進行預處理,儘量消除數據中存在
的錯誤以及缺失信息.
3:transformation:轉換數據為數據挖掘工具所需的格式.這一步可以使得結果更加理想化.
4:datamining:套用數據挖掘工具.
5:interpretation/evaluation:了解以及評估數據挖掘結果.
過程模型
常用KDD過程模型(KDDprocessmodel)
隨著Fayyad,Piatetsky-Shapiro和Smyth在1996年總結出的KDD5個基本步驟,各種不同的KDD過程模型
在此基礎上發展以及完善起來.整體來說,KDD過程模型包含"學術模型"(academicresearchmodel)以及"
工業模型"(industrialmodel)兩大類.常見的KDD過程模型有:
1996年Fayyad等人提出的"9步驟模型"(nine-stepsmodel).
1999年europeancommission機構起草的CRISP-DM模型.(cross-industrystandardprocessfordatamining)
核心工作
知識發現的核心工作為數據挖掘,所謂數據挖掘,就是從資料庫中抽取隱含的、以前未知的、具有潛在套用價值的信息的過程。數據挖掘是KDD最核心的部分。數據挖掘與傳統分析工具不同的是數據挖掘使用的是基於發現的方法,運用模式匹配和其它算法決定數據之間的重要聯繫。
數據挖掘算法的好壞將直接影響到所發現知識的好壞。大多數的研究都集中在數據挖掘算法和套用上。需要說明的是,有的學者認為,數據開採和知識發現含義相同,表示成KDD/DM。它是一個反覆的過程,通常包含多個相互聯繫的步驟:預處理、提出假設、選取算法、提取規則、評價和解釋結果、將模式構成知識,最後是套用。在實際,人們往往不嚴格區分數據挖掘和資料庫中的知識發現,把兩者混淆使用。一般在科研領域中稱為KDD,而在工程領域則稱為數據挖掘。
