音頻壓縮技術的出現及早期套用
音頻壓縮技術指的是對原始數字音頻信號流(PCM編碼)運用適當的數位訊號處理技術,在不損失有用信息量,或所引入損失可忽略的條件下,降低(壓縮)其碼率,也稱為壓縮編碼。它必須具有相應的逆變換,稱為解壓縮或解碼。音頻信號在通過一個編解碼系統後可能引入大量的噪聲和一定的失真。 數位訊號的優勢是顯而易見的,而它也有自身相應的缺點,即存儲容量需求的增加及傳輸時信道容量要求的增加。以CD為例,其採樣率為44.1KHz,量化精度為16比特,則1分鐘的立體聲音頻信號需占約10M位元組的存儲容量,也就是說,一張CD唱盤的容量只有1小時左右。當然,在頻寬高得多的數字視頻領域這一問題就顯得更加突出。是不是所有這些比特都是必需的呢?研究發現,直接採用PCM碼流進行存儲和傳輸存在非常大的冗餘度。事實上,在無損的條件下對聲音至少可進行4:1壓縮,即只用25%的數字量保留所有的信息,而在視頻領域壓縮比甚至可以達到幾百倍。因而,為利用有限的資源,壓縮技術從一出現便受到廣泛的重視。 對音頻壓縮技術的研究和套用由來已久,如A律、u律編碼就是簡單的準瞬時壓擴技術,並在ISDN話音傳輸中得到套用。對語音信號的研究發展較早,也較為成熟,並已得到廣泛套用,如自適應差分PCM(ADPCM)、線性預測編碼(LPC)等技術。在廣播領域,NICAM(Near Instantaneous Companded Audio Multiplex - 準瞬時壓擴音頻復用)等系統中都使用了音頻壓縮技術。
音頻信號的冗餘信息
數字音頻壓縮編碼在保證信號在聽覺方面不產生失真的前提下,對音頻數據信號進行儘可能大的壓縮。數字音頻壓縮編碼採取去除聲音信號中冗餘成分的方法來實現。所謂冗餘成分指的是音頻中不能被人耳感知到的信號,它們對確定聲音的音色,音調等信息沒有任何的幫助。冗餘信號包含人耳聽覺範圍外的音頻信號以及被掩蔽掉的音頻信號等。例如,人耳所能察覺的聲音信號的頻率範圍為20Hz~20KHz,除此之外的其它頻率人耳無法察覺,都可視為冗餘信號。此外,根據人耳聽覺的生理和心理聲學現象,當一個強音信號與一個弱音信號同時存在時,弱音信號將被強音信號所掩蔽而聽不見,這樣弱音信號就可以視為冗餘信號而不用傳送。這就是人耳聽覺的掩蔽效應,主要表現在頻譜掩蔽效應和時域掩蔽效應,現分別介紹如下:
頻譜掩蔽效應。
一個頻率的聲音能量小於某個閾值之後,人耳就會聽不到,這個閾值稱為最小可聞閾。當有另外能量較大的聲音出現的時候,該聲音頻率附近的閾值會提高很多,即所謂的掩蔽效應。
 音頻壓縮 合併圖冊
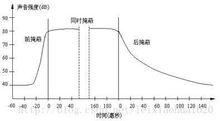
音頻壓縮 合併圖冊時域掩蔽效應。
當強音信號和弱音信號同時出現時,還存在時域掩蔽效應。即兩者發生時間很接近的時候,也會發生掩蔽效應。時域掩蔽分為前掩蔽、同時掩蔽和後掩蔽三部分。前掩蔽是指人耳在聽到強信號之前的短暫時間內,已經存在的弱信號會被掩蔽而聽不到。同時掩蔽是指當強信號與弱信號同時存在時,弱信號會被強信號所掩蔽而聽不到。後掩蔽是指當強信號消失後,需經過較長的一段時間才能重新聽見弱信號,稱為後掩蔽。這些被掩蔽的弱信號即可視為冗餘信號。
 音頻壓縮
音頻壓縮壓縮編碼方法
音頻信號編碼按照壓縮原理不同,分為波形編碼、參數編碼以及多種技術相互融合的編碼形式
(1)波形編碼直接對音頻信號的時域或頻域波形按一定速率採樣,然後將幅度樣本分層量化,變換為數字代碼,由波形數據產生一種重構信號編碼系統源於信號原始樣值,波形與原始聲音波形儘可能地一致,保留了信號的細節變化和各種過渡特徵。
(2)參數編碼首先根據不同的信號源,如語言信號、自然聲音等形式建立特徵模型,通過提取特徵參數和編碼處理,力圖使重建的聲音信號儘可能高的保持原聲音的語意,但重建信號的波形同原聲音信號的波形可能會有相當大的差別。常用的特徵參數有共振峰、線性預測係數、頻帶劃分濾波器等參數編碼技術可實現低速率的聲音信號編碼,比特率可壓縮到2Kbit/s - 4.8Kbit/s ,但聲音的質量只能達到中等,特別是自然度較低,僅適合語言語言的傳遞與表達。
(3)混合編碼將波形編碼和參數編碼組合起來的編碼形式克服了原有波形編碼和參數編碼的弱點,力圖保持波形編碼的高質量和參數編碼的低速率,在4 - 16Kbit/s速率上能夠得到高質量的合成聲音信號。混合編碼的基礎是線性預測編碼(LPC ),常用脈衝激勵線性預測編碼(MPLPC )、規劃脈衝激勵線性預測編碼(KPELPC)碼本激勵線性預測編碼(CELPC)等編碼方式。
 音頻壓縮 音頻壓縮
音頻壓縮 音頻壓縮壓縮方法其它劃分
在音頻壓縮領域,有兩種壓縮方式,分別是有損壓縮和無損壓縮!我們常見到的MP3、WMA、OGG被稱為有損壓縮,有損壓縮顧名思義就是降低音頻採樣頻率與比特率,輸出的音頻檔案會比原檔案小。另一種音頻壓縮被稱為無損壓縮,也就是我們所要說的主題內容。無損壓縮能夠在100%保存原檔案的所有數據的前提下,將音頻檔案的體積壓縮的更小,而將壓縮後的音頻檔案還原後,能夠實現與源檔案相同的大小、相同的碼率。無損壓縮格式有APE、FLAC、WavPack、LPAC、WMALossless、AppleLossless、La、OptimFROG、Shorten,而常見的、主流的無損壓縮格式只有APE、FLAC。
音頻壓縮算法的主要分類及典型代表
一般來講,可以將音頻壓縮技術分為無損(lossless)壓縮及有損(lossy)壓縮兩大類,而按照壓縮方案的不同,又可將其劃分為時域壓縮、變換壓縮、子帶壓縮,以及多種技術相互融合的混合壓縮等等。各種不同的壓縮技術,其算法的複雜程度(包括時間複雜度和空間複雜度)、音頻質量、算法效率(即壓縮比例),以及編解碼延時等都有很大的不同。各種壓縮技術的套用場合也因之而各不相同。
時域壓縮(或稱為波形編碼)技術
直接針對音頻PCM碼流的樣值進行處理,通過靜音檢測、非線性量化、差分等手段對碼流進行壓縮。此類壓縮技術的共同特點是算法複雜度低,聲音質量一般,壓縮比小(CD音質> 400kbps),編解碼延時最短(相對其它技術)。此類壓縮技術一般多用於語音壓縮,低碼率套用(源信號頻寬小)的場合。時域壓縮技術主要包括 G.711、ADPCM、LPC、CELP,以及在這些技術上發展起來的塊壓擴技術如NICAM、子帶ADPCM(SB-ADPCM)技術。
子帶壓縮技術
子帶編碼理論最早是由Crochiere等於1976年提出的。其基本思想是將信號分解為若干子頻帶內的分量之和,然後對各子帶分量根據其不同的分布特性採取不同的壓縮策略以降低碼率。通常的子帶壓縮技術和下面介紹的變換壓縮技術都是根據人對聲音信號的感知模型(心理聲學模型),通過對信號頻譜的分析來決定子帶樣值或頻域樣值的量化階數和其它參數選擇的,因此又可稱為感知型(Perceptual)壓縮編碼。這兩種壓縮方式相對時域壓縮技術而言要複雜得多,同時編碼效率、聲音質量也大幅提高,編碼延時相應增加。一般來講,子帶編碼的複雜度要略低於變換編碼,編碼延時也相對較短。
音頻壓縮技術的標準化和MPEG-1
由於數字音頻壓縮技術具有廣闊的套用範圍和良好的市場前景,因而一些研究機構和公司都不遺餘力地開發自己的專利技術和產品。這些音頻壓縮技術的標準化工作就顯得十分重要。 在音頻壓縮標準化方面取得巨大成功的是MPEG-1音頻(ISO/IEC11172-3)。在MPEG-1中,對音頻壓縮規定了三種模式,即層Ⅰ、層Ⅱ(即MUSICAM,又稱MP2),層Ⅲ(又稱MP3)。由於在制訂標準時對許多壓縮技術進行了認真的考察,並充分考慮了實際套用條件和算法的可實現性(複雜度),因而三種模式都得到了廣泛的套用。VCD中使用的音頻壓縮方案就是MPEG-1層Ⅰ;而MUSICAM由於其適當的複雜程度和優秀的聲音質量,在數字演播室、DAB、DVB等數位元組目的製作、交換、存儲、傳送中得到廣泛套用;MP3是在綜合MUSICAM和ASPEC的優點的基礎上提出的混合壓縮技術,在當時的技術條件下,MP3的複雜度顯得相對較高,編碼不利於實時,但由於MP3在低碼率條件下高水準的聲音質量,使得它成為軟解壓及網路廣播的寵兒。可以說,MPEG-1音頻標準的制訂方式決定了它的成功,這一思路甚至也影響到後面將要談到的MPEG-2和MPEG-4音頻標準的制訂。
