![阿爾法狗[谷歌人機大戰機器人AlphaGo]](/img/8/108/nBnauM3X4EjM4EjN0EDO0EDN0UTMyITNykTO0EDMwAjMwUzLxgzLxEzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg "阿爾法狗[谷歌人機大戰機器人AlphaGo]")
舊版原理
深度學習
 李世石與阿爾法圍棋人機大戰
李世石與阿爾法圍棋人機大戰阿爾法圍棋(AlphaGo)是一款圍棋人工智慧程式。其主要工作原理是“深度學習”。“深度學習”是指多層的人工神經網路和訓練它的方法。一層神經網路會把大量矩陣數字作為輸入,通過非線性激活方法取權重,再產生另一個數據集合作為輸出。這就像生物神經大腦的工作機理一樣,通過合適的矩陣數量,多層組織連結一起,形成神經網路“大腦”進行精準複雜的處理,就像人們識別物體標註圖片一樣。
阿爾法圍棋用到了很多新技術,如神經網路、深度學習、蒙特卡洛樹搜尋法等,使其實力有了實質性飛躍。美國臉書公司“黑暗森林”圍棋軟體的開發者田淵棟在網上發表分析文章說,阿爾法圍棋系統主要由幾個部分組成:一、策略網路(Policy Network),給定當前局面,預測並採樣下一步的走棋;二、快速走子(Fast rollout),目標和策略網路一樣,但在適當犧牲走棋質量的條件下,速度要比策略網路快1000倍;三、價值網路(Value Network),給定當前局面,估計是白勝機率大還是黑勝機率大;四、蒙特卡洛樹搜尋(Monte Carlo Tree Search),把以上這三個部分連起來,形成一個完整的系統。
兩個大腦
 柯潔與阿爾法圍棋人機大戰
柯潔與阿爾法圍棋人機大戰阿爾法圍棋(AlphaGo)是通過兩個不同神經網路“大腦”合作來改進下棋。這些“大腦”是多層神經網路,跟那些Google圖片搜尋引擎識別圖片在結構上是相似的。它們從多層啟發式二維過濾器開始,去處理圍棋棋盤的定位,就像圖片分類器網路處理圖片一樣。經過過濾,13個完全連線的神經網路層產生對它們看到的局面判斷。這些層能夠做分類和邏輯推理。
第一大腦:落子選擇器 (Move Picker)
阿爾法圍棋(AlphaGo)的第一個神經網路大腦是“監督學習的策略網路(Policy Network)” ,觀察棋盤布局企圖找到最佳的下一步。事實上,它預測每一個合法下一步的最佳機率,那么最前面猜測的就是那個機率最高的。這可以理解成“落子選擇器”。
第二大腦:棋局評估器 (Position Evaluator)
阿爾法圍棋(AlphaGo)的第二個大腦相對於落子選擇器是回答另一個問題,它不是去猜測具體下一步,而是在給定棋子位置情況下,預測每一個棋手贏棋的機率。這“局面評估器”就是“價值網路(Value Network)”,通過整體局面判斷來輔助落子選擇器。這個判斷僅僅是大概的,但對於閱讀速度提高很有幫助。通過分析歸類潛在的未來局面的“好”與“壞”,阿爾法圍棋能夠決定是否通過特殊變種去深入閱讀。如果局面評估器說這個特殊變種不行,那么AI就跳過閱讀。
這些網路通過反覆訓練來檢查結果,再去校對調整參數,去讓下次執行更好。這個處理器有大量的隨機性元素,所以人們是不可能精確知道網路是如何“思考”的,但更多的訓練後能讓它進化到更好。
操作過程
阿爾法圍棋(AlphaGo)為了應對圍棋的複雜性,結合了監督學習和強化學習的優勢。它通過訓練形成一個策略網路(policy network),將棋盤上的局勢作為輸入信息,並對所有可行的落子位置生成一個機率分布。然後,訓練出一個價值網路(value network)對自我對弈進行預測,以 -1(對手的絕對勝利)到1(AlphaGo的絕對勝利)的標準,預測所有可行落子位置的結果。這兩個網路自身都十分強大,而阿爾法圍棋將這兩種網路整合進基於機率的蒙特卡羅樹搜尋(MCTS)中,實現了它真正的優勢。新版的阿爾法圍棋產生大量自我對弈棋局,為下一代版本提供了訓練數據,此過程循環往復。
在獲取棋局信息後,阿爾法圍棋會根據策略網路(policy network)探索哪個位置同時具備高潛在價值和高可能性,進而決定最佳落子位置。在分配的搜尋時間結束時,模擬過程中被系統最頻繁考察的位置將成為阿爾法圍棋的最終選擇。在經過先期的全盤探索和過程中對最佳落子的不斷揣摩後,阿爾法圍棋的搜尋算法就能在其計算能力之上加入近似人類的直覺判斷。
2017年1月,谷歌DeepMind公司CEO哈薩比斯在德國慕尼黑DLD(數字、生活、設計)創新大會上宣布推出真正2.0版本的阿爾法圍棋。其特點是擯棄了人類棋譜,只靠深度學習的方式成長起來挑戰圍棋的極限。
新版原理
自學成才
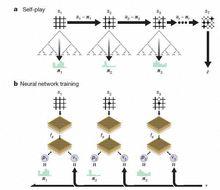 AlphaGo Zero強化學習下的自我對弈
AlphaGo Zero強化學習下的自我對弈阿爾法圍棋(AlphaGo)此前的版本,結合了數百萬人類圍棋專家的棋譜,以及強化學習的監督學習進行了自我訓練。
AlphaGoZero的能力則在這個基礎上有了質的提升。最大的區別是,它不再需要人類數據。也就是說,它一開始就沒有接觸過人類棋譜。研發團隊只是讓它自由隨意地在棋盤上下棋,然後進行自我博弈。
據阿爾法圍棋團隊負責人大衛·席爾瓦(Dave Sliver)介紹,AlphaGoZero使用新的強化學習方法,讓自己變成了老師。系統一開始甚至並不知道什麼是圍棋,只是從單一神經網路開始,通過神經網路強大的搜尋算法,進行了自我對弈。隨著自我博弈的增加,神經網路逐漸調整,提升預測下一步的能力,最終贏得比賽。更為厲害的是,隨著訓練的深入,阿爾法圍棋團隊發現,AlphaGoZero還獨立發現了遊戲規則,並走出了新策略,為圍棋這項古老遊戲帶來了新的見解。
一個大腦
AlphaGoZero僅用了單一的神經網路。在此前的版本中,AlphaGo用到了“策略網路”來選擇下一步棋的走法,以及使用“價值網路”來預測每一步棋後的贏家。而在新的版本中,這兩個神經網路合二為一,從而讓它能得到更高效的訓練和評估。
神經網路
AlphaGoZero並不使用快速、隨機的走子方法。在此前的版本中,AlphaGo用的是快速走子方法,來預測哪個玩家會從當前的局面中贏得比賽。相反,新版本依靠地是其高質量的神經網路來評估下棋的局勢。
舊版戰績
對戰機器
研究者讓“阿爾法圍棋”和其他的圍棋人工智慧機器人進行了較量,在總計495局中只輸了一局,勝率是99.8%。它甚至嘗試了讓4子對陣CrazyStone、Zen和Pachi三個先進的人工智慧機器人,勝率分別是77%、86%和99%。
2017年5月26日,中國烏鎮圍棋峰會舉行人機配對賽。對戰雙方為古力/阿爾法圍棋組合和連笑/阿爾法圍棋組合。最終連笑/阿爾法圍棋組合逆轉獲得勝利。
對戰人類
 李世石阿爾法圍棋人機大戰現場
李世石阿爾法圍棋人機大戰現場2016年1月27日,國際頂尖期刊《自然》封面文章報導,谷歌研究者開發的名為“阿爾法圍棋”(AlphaGo)的人工智慧機器人,在沒有任何讓子的情況下,以5:0完勝歐洲圍棋冠軍、職業二段選手樊麾。在圍棋人工智慧領域,實現了一次史無前例的突破。電腦程式能在不讓子的情況下,在完整的圍棋競技中擊敗專業選手,這是第一次。
2016年3月9日到15日,阿爾法圍棋程式挑戰世界圍棋冠軍李世石的圍棋人機大戰五番棋在韓國首爾舉行。比賽採用中國圍棋規則,最終阿爾法圍棋以4比1的總比分取得了勝利。
 阿爾法圍棋戰勝圍棋世界冠軍團隊
阿爾法圍棋戰勝圍棋世界冠軍團隊2016年12月29日晚起到2017年1月4日晚,阿爾法圍棋在弈城圍棋網和野狐圍棋網以“Master”為註冊名,依次對戰數十位人類頂尖圍棋高手,取得60勝0負的輝煌戰績。
2017年5月23日到27日,在中國烏鎮圍棋峰會上,阿爾法圍棋以3比0的總比分戰勝排名世界第一的世界圍棋冠軍柯潔。在這次圍棋峰會期間的2017年5月26日,阿爾法圍棋還戰勝了由陳耀燁、唐韋星、周睿羊、時越、羋昱廷五位世界冠軍組成的圍棋團隊。
新版戰績
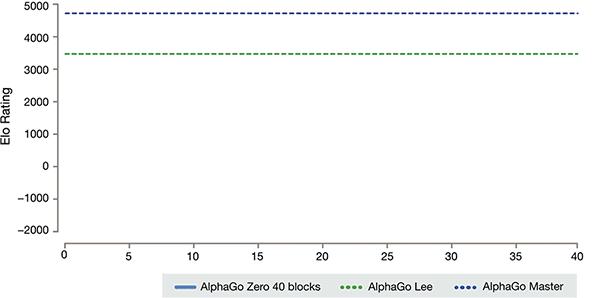 AlphaGo-Zero的訓練時間軸
AlphaGo-Zero的訓練時間軸經過短短3天的自我訓練,AlphaGo Zero就強勢打敗了此前戰勝李世石的舊版AlphaGo,戰績是100:0的。經過40天的自我訓練,AlphaGo Zero又打敗了AlphaGo Master版本。“Master”曾擊敗過世界頂尖的圍棋選手,甚至包括世界排名第一的柯潔。
版本介紹
 AlphaGo幾個版本的排名情況
AlphaGo幾個版本的排名情況據公布的題為《在沒有人類知識條件下掌握圍棋遊戲》的論文介紹,開發公司將“阿爾法圍棋”的發展分為四個階段,也就是四個版本,第一個版本即戰勝樊麾時的人工智慧,第二個版本是2016年戰勝李世石的阿爾法圍棋,第三個是在圍棋對弈平台名為“Master”(大師)的版本,其在與人類頂尖棋手的較量中取得60勝0負的驕人戰績,而最新版的人工智慧開始學習圍棋3天后便以100:0橫掃了第二版本的阿爾法圍棋,學習40天后又戰勝了在人類高手看來不可企及的第三個版本“大師”。
設計團隊
戴密斯·哈薩比斯(Demis Hassabis),人工智慧企業家,DeepMind Technologies公司創始人,人稱“阿爾法圍棋之父”。4歲開始下西洋棋,8歲自學編程,13歲獲得西洋棋大師稱號。17歲進入劍橋大學攻讀計算機科學專業。在大學裡,他開始學習圍棋。2005年進入倫敦大學學院攻讀神經科學博士,選擇大腦中的海馬體作為研究對象。兩年後,他證明了5位因為海馬體受傷而患上健忘症的病人,在暢想未來時也會面臨障礙,並憑這項研究入選《科學》雜誌的“年度突破獎”。2011年創辦DeepMind Technologies公司,以“解決智慧型”為公司的終極目標。
 阿爾法圍棋設計團隊部分成員
阿爾法圍棋設計團隊部分成員大衛·席爾瓦(David Silver),劍橋大學計算機科學學士、碩士,加拿大阿爾伯塔大學計算機科學博士,倫敦大學學院講師,Google DeepMind研究員,阿爾法圍棋主要設計者之一。
除上述人員之外,阿爾法圍棋設計團隊核心人員還有黃士傑(Aja Huang)、施恩·萊格(Shane Legg)和穆斯塔法·蘇萊曼(Mustafa Suleyman)等。
發展方向
“阿爾法圍棋”(AlphaGo)能否代表智慧型計算發展方向還有爭議,但比較一致的觀點是,它象徵著計算機技術已進入人工智慧的新信息技術時代(新IT時代),其特徵就是大數據、大計算、大決策,三位一體。它的智慧正在接近人類。
谷歌Deep mind執行長(CEO)戴密斯·哈薩比斯宣布“要將阿爾法圍棋(AlphaGo)和醫療、機器人等進行結合”。因為它是人工智慧,會自己學習,只要給它資料就可以移植。
據韓國《朝鮮日報》報導,為實現該計畫,哈薩比斯2016年初在英國的初創公司“巴比倫”投資了2500萬美元。巴比倫正在開發醫生或患者說出症狀後,在網際網路上搜尋醫療信息、尋找診斷和處方的人工智慧APP(應用程式)。如果阿爾法圍棋(AlphaGo)和“巴比倫”結合,診斷的準確度將得到劃時代性提高。
在柯潔與阿爾法圍棋的圍棋人機大戰三番棋結束後,阿爾法圍棋團隊宣布阿爾法圍棋將不再參加圍棋比賽。阿爾法圍棋將進一步探索醫療領域,利用人工智慧技術攻克現實現代醫學中存在的種種難題。在醫療資源的現狀下,人工智慧的深度學習已經展現出了潛力,可以為醫生提供輔助工具。實際上,對付人類棋手從來不是“阿爾法圍棋”的目的,開發公司只是通過圍棋來試探它的功力,而研發這一人工智慧的最終目的是為了推動社會變革、改變人類命運。據悉,他們正積極與英國醫療機構和電力能源部門合作,以此提高看病效率和能源效率。
社會評論
中國圍棋職業九段棋手聶衛平:“Master(即阿爾法圍棋升級版)技術全面,從來不犯錯,這一點是其最大的優勢,人類要打敗它的話,必須在前半盤領先,然後中盤和官子階段也不容出錯,這樣固然很難,但客觀上也促進了人類棋手在圍棋技術上的提高。”
世界排名第一的圍棋世界冠軍柯潔:“在我看來它(指阿爾法圍棋)就是圍棋上帝,能夠打敗一切。”“對於AlphaGo的自我進步來講,人類太多餘了。”
復旦大學計算機科學技術學院教授、博士生導師危輝:“人機大戰對於人工智慧的發展意義很有限。解決了圍棋問題,並不代表類似技術可以解決其他問題,自然語言理解、圖像理解、推理、決策等問題依然存在,人工智慧的進步被誇大了。”
中國圍棋世界冠軍唐韋星:“看了之後不知道說什麼,它(AlphaGo)確實不需要我們的知識,之前版本用了好幾年,被這個才學了40天的打敗似乎就是我們拖後腿了。”
五子棋棋手吳侃:“有時候感覺對AlphaGo的評價過於高了,人類也不需要把其奉為神明,但不可否認,AlphaGo的出現給圍棋界帶來了巨大的震動。”
