簡介
產生背景
隨著後基因組時代的到來,人們開始對於基因組及其成套產物的功能進行研究。在生命體內幾乎所有的基因組產物都是通過與其它各種分子發生相互作用而行使其功能的。
為了更好地保存和處理如此海量的生物序列數據,我們毫無疑問的將這些數據存儲到大型計算機的資料庫中。目前,國際上的公共資料庫有近百種,其中最著名的核酸和蛋白質序列資料庫有幾十種。據統計,這些資料庫中的數據量正在以指數速率增長,平均每年翻一番。
有了這些資料庫,人類將更方便地共享這些生物序列,更方便對這些數據進行分析處理。因為,到20世紀90年代,Internet技術已經相當成熟,人們可以方便的通過網路共享資源。因此,這些大型的資料庫每天都進行更新,並通過網路進行數據同步。這樣全世界的生物信息學研究人員獲取實驗數據就變得很方便了。另外,這些大型資料庫伺服器大多提供序列分析和基因檢索等序列分析服務。研究人員可以通過這些資料庫提供的先進的技術和工具對生物序列進行分析。
分類
根據資料庫中數據內容的不同,現有的生物序列資料庫有如下幾類:
基因序列資料庫,包括最著名的GenBank、EMBL、DDBJl等。這些資料庫每天更新,相互交換數據。目前,它們可以提供5萬多個物種的數百億鹼基對的基因序列。此外,它們還提供序列分析服務,支持線上和離線的序列分析。
蛋白質資料庫,其中最著名的是國際蛋白質資料庫PSD和瑞士的資料庫SWISS—PROT。它們僅僅提供蛋白質序列數據和一些蛋白質序列搜尋服務,如基於文本的互動式檢索,標準序列相似性搜尋,結合序列相似性、注釋信息和蛋白質家族信息的高級搜尋等。
功能資料庫,如KEGG,它是系統分析基因功能,聯繫基因組信息和功能信息的知識庫。它存儲了基因組序列和更高級的功能信息,包括圖解的細胞生化過程以及關於化學物質、酶分子、酶反應等信息。KEGG還提供了Java的圖形工具來訪問基因組圖譜,比較基因組圖譜和表達圖譜,以及其他序列、圖形比較等。
其它生物資料庫,包括RNA資料庫、線粒體資料庫、基因表達資料庫、密碼子資料庫、蛋白質三維結構資料庫和霉一代謝資料庫等等。
當前問題
序列資料庫的繁瑣冗長增加了科學家們要使用這些資源時的困難 某個生物學家要獲取一個關於果蠅的核酸序列,從EMBL核酸資料庫中得到36個不同的核酸序列記錄。他們中沒有一個考慮當今的知識,例如,刊登遺傳因子捆綁位置。一些是突變株的等位基因,一些是不同的野生型等位基因,但是對於它們之間的差異投有完整的注釋。可憐的生物學家只想得到這個基因的決定性序列。當然,這不是真正的目的,然而卻非常實用。對第二代序列資料庫有明顯的需求,生物學的內容以較有條理的方式連線到序列上,而冗長的序列被合併(附有特別的注釋)。這些都應是以最初的序列資料庫為基礎,被具有必要的專門技術的機構來處理。一 些遺傳資料庫正著手此類工程。
序列資料庫
國際核酸序列數據文庫(通常稱為基因庫),是一個聯合產物,包括日本的DNA資料庫”,歐洲生物信息協會(EBI )及NCBI。它是一個從群體中接受核酸序列數據並且使其成為隨意使用的數據倉庫 儘管他的名字“資料庫”還含有從核酸序列的“概念翻譯”獲得的蛋白質序列。為了達到記載每個公開的核酸序列的目的,
這個資料庫作為試驗性數據與為最終完成而競爭的儲藏庫。這些數據是龐雜的,它們隨著對材料來源的重視程度(如與cDNA相對應的基因組)、預期的質量(如已經完成的相對單一的序列)、序列注釋的範圍與關係到生物學目標的序列預期完成情況(如相對於部分的基因或基因組是完整的)的變化而變化。
雖然有資料庫工作人員來檢驗數據的完整性及明顯的錯誤,數據的質量還是與呈送者有直接關係。作為一種結論,資料庫中有許多錯誤,許多序列記錄或者被錯誤地標記、污損,或者被不完全地或錯誤地注釋,或者包含排列的錯誤。另外,資料庫是非常冗長的,在這種情景下,來之同種生物體的相同序列可能有多次重複,簡單地歸咎於最初科技報告的繁瑣。一個重要的“附加值”服務是優劣分類等級制的負擔。
一系列序列資料庫通過合併序列解決冗長的問題,這些合併序列與一個完全可以從相同基因推斷出來的序列充分相似。目前,這些資料庫僅對人類序列有用,在其它方面的使用則剛剛起步對於擁有完整的或巨大的序列的生物體基因組,除了被儲存於主要的核酸序列資料庫外,還常常被儲存於特定的生物資料庫中。對此,一個可用的信息來源是完整的基因組排列計畫目錄,由各個大學保存的, 這項資源已被連線到公共資料庫上。
所有大型排序中心都保存他們自己的資料庫,這些資料庫經由它們的本頁可以進入訪問。有五個特別有用的資料庫—由於被研究的生物體不同一他們是基因組研究協會(TIGR) ,華盛頓大學基因組序列中心 ,Sanger 中心、 Oklahoma大學基因組技術中心及Stanford基因組資源處。
幾類特別的序列資料庫也是可以利用的。它們中有一些是特殊的序列等級,如關於ribosonud基因的Ribosomal資料庫計畫,HIV與親緣病毒的HIV序列資料庫 , 關於免疫遺傳分子的[ IMGT]資料庫 ;還有獨具特色的TRANSFAC、EPI)、REBASE等等。
蛋白質資料庫IPID
IPID的系統架構分為三層:
(1)數據倉庫層:用於存儲來自25個資料庫的各種與蛋白質相關的經以三個基本相互作用元件標準化後的相互作用數據、7個不同的序列庫(包括以CFGP格式存儲的10個基因組數據)、4個Dommn資料庫和3個Chemical資料庫;
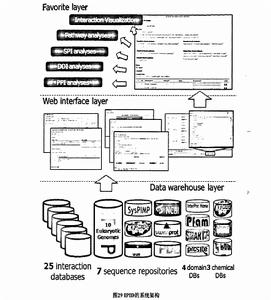 IPID的系統架構
IPID的系統架構(2)網路界面層;用於方便地瀏覽存放於數據倉庫層中的各種與蛋白質相關的相互作用及基本相互作用元件數據,並提供了InterXlTandem,用於鑑定用戶所輸入的質譜中的蛋白質並顯示IPID中所含的與該蛋白質相關的各種相互作用數據。
(3)Favorite層:是一個用於存放和分析用戶從數據倉庫層採集的各種所感興趣的與蛋白質相關的相互作用或相互作用元件數據的個性化虛擬空間,共提供27個分析工具。
