
定義
邏輯結構是獨立於任何一種數據模型的,在實際套用中,一般所用的資料庫環境已經給定(如SQL Server或Oracle或MySql)。由於目前使用的資料庫基本上都是關係資料庫,因此首先需要將實體-關係圖轉換為關係模型,然後根據具體資料庫管理系統的特點和限制轉換為指定資料庫管理系統支持下數據模型,最後進行最佳化。
設計步驟
( 1 ) 將概念結構轉換為一般的關係、網狀、層次模型;
( 2 ) 將轉換來的關係、網狀、層次模型向指定資料庫管理系統支持的數據模型轉換;
( 3 ) 對數據模型進行最佳化。
實體-關係圖
基本組成
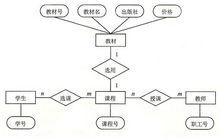 教務管理系統的E-R圖
教務管理系統的E-R圖實體-關係圖的組件有很多,但概括起來說,可分為以下四種:
線段:用於將實體、關係相連線
對於雙矩形、雙菱形、雙橢圓、雙線段等等一些組件,可以不用去管,通常用以上四種組件就可以表達清楚實體及實體間的關係。
從實體-關係圖向關係模式轉化 資料庫的邏輯設計主要是將概念模型轉換成一般的關係模式,也就是將實體-聯繫圖中的實體、實體的屬性和實體之間的聯繫轉化為關係模式。在轉化過程中會遇到如下問題:
(1)命名問題。命名問題可以採用原名,也可以另行命名,避免重名。
(2)非原子屬性問題。非原子屬性問題可將其進行縱向和橫行展開。
(3)聯繫轉換問題。聯繫可用關係表示。
建立實體-關係模型
 標識實體
標識實體1、標識實體:
通常有用戶、角色這兩個實體。
2、標識關係:
 標識關係
標識關係用戶與角色間為多對多的互相擁有關係。
3、標識實體、關係的屬性:
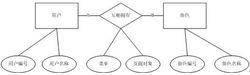 標識實體、關係的屬性
標識實體、關係的屬性不僅僅是實體有屬性,關係同樣也有屬性,這些屬性在實體間建立關係時才會存在。
有時屬性太多,無法在圖上一一列出,可以用表格,在後面的步驟中這個表格同樣會用到,如下:
| 實體 | 屬性 | 描述 | … |
| 用戶 | 性別 年齡 電話 … | 男/女 多大了 聯繫方式 … | … |
4、確定屬性域:
屬性域就是屬性的取值範圍。
這時,可以用表格將屬性的數據類型、數據長度、取值範圍及是否可為空、簡單/複合、單值/多值、是否為派生屬性等域信息定義出來。
這個過程,事實上包含了邏輯結構設計中的數據類型、NULL、CHECK、DEFAULT等信息。
| 實體 | 屬性 | 描述 | 數據類型及長度 | 是否可為空 |
| 用戶 | 性別 年齡 電話 … | 男/女 多大了 聯繫方式 … | 1位元組的短整形或布爾型 1位元組的短整形 20位元組的字元型或長整形 … | NO NO YES |
5、確定鍵:鍵就是可用於標識實體的屬性,有:主鍵、唯一鍵、外鍵。
| 實體 | 屬性 | 描述 | 鍵 |
| 用戶 | 用戶編號 性別 年齡 電話 … | 男/女 多大了 聯繫方式 … | 主鍵 |
6、實體的特化/泛化:
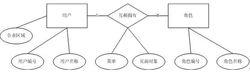 實體的特化/泛華
實體的特化/泛華也就是面向對象模型中父類和子類的概念,這是個可選的步驟。舉個例子,用戶中大部分人都是普通員工,但有一小部分是從事銷售的,銷售人員
有個負責區域的屬性,如果將這個屬性放在用戶實體中,如右圖:
這時我們會發現,除了銷售人員外,其他非銷售人員這個屬性全都不存在,這就是特化的過程。可以另建一個銷售人員的實體來泛化用戶實體,如右圖:
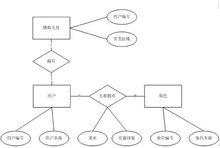 資料庫的邏輯結構設計
資料庫的邏輯結構設計這樣就完成了對用戶實體的泛化,泛化的過程也就是抽出實體間公共屬性的過程,但通常,除非特化的部分太多,才會考慮將一個實體抽象成兩個
1對1關係的實體,所有這個步驟是可選的。
7、檢查模型:
(1)檢查冗餘
首先檢查實體:1對1關係的實體中有沒有非外鍵的重複屬性,或者就是同一個實體;
其次檢查關係:有沒有通過其他關係也可以得到的重複屬性;
當然有時,需要考慮時間維度,因為有些屬性是有時效性的,也就是雖然是同一個屬性,但不同的時間表示的卻是不同的內容,這一點在後面的邏輯結構設計中會提到,這並不是真正的冗餘。
(2)檢查業務
檢查當前的實體-聯繫模型是否滿足當前業務的場景。可以從某個實體開始,沿著當前E-R模型的各個節點去模擬業務場景。尤其需要和《需求規格說明書》去做校驗。
到這裡,也就完成了實體-R模型建立的全過程,有時,對於比較複雜的實體-關係模型,一張圖可能顯得太過侷促,可以建立全局、局部實體-關係模型圖,以便於查看和分析。
圖向關係
模型的轉換
示例
實體-關係圖如何轉換為關係模型呢?我們先看一個例子。
圖2.1是學生和班級的實體-關係圖,學生與班級構成多對一的聯繫。根據實際套用,我們可以做出這個簡單例子的關係模式:
學生(學號,姓名,班級)
班級(編號,名稱)
“學生.班級”為外鍵,參照“班級.編號”取值。
這個例子我們是憑經驗轉換的,那么裡面有什麼規律呢?在2.2節,我們將這些經驗總結成一些規則,以供轉換使用。
轉換規則
(1) 一個實體型轉換為一個關係模式
一般實體-關係圖中的一個實體轉換為一個關係模式,實體的屬性就是關係的屬性,實體的碼就是關係的碼。
(2) 一個1:1 聯繫可以轉換為一個獨立的關係模式,也可以與任意一端對應的關係模式合併。
圖2.2是一個一對一聯繫的例子。根據規則(2),有三種轉換方式。
(i) 聯繫單獨作為一個關係模式
此時聯繫本身的屬性,以及與該聯繫相連的實體的碼均作為關係的屬性,可以選擇與該聯繫相連的任一實體的碼屬性作為該關係的碼。結果如下:
職工(工號,姓名)
產品(產品號,產品名)
負責(工號,產品號)
其中“負責”這個關係的碼可以是工號,也可以是產品號。
(ii) 與職工端合併
職工(工號,姓名,產品號)
產品(產品號,產品名)
其中“職工.產品號”為外碼。
(iii) 與產品端合併
職工(工號,姓名)
產品(產品號,產品名,負責人工號)
其中“產品.負責人工號”為外碼。
(3) 一個1:n 聯繫可以轉換為一個獨立的關係模式,也可以與n 端對應的關係模式合併。
(i) 若單獨作為一個關係模式
此時該單獨的關係模式的屬性包括其自身的屬性,以及與該聯繫相連的實體的碼。該關係的碼為n端實體的主屬性。
顧客(顧客號,姓名)
訂單(訂單號,……)
訂貨(顧客號,訂單號)
(ii) 與n端合併
顧客(顧客號,姓名)
訂單(訂單號,……,顧客號)
(4) 一個m:n 聯繫可以轉換為一個獨立的關係模式。
該關係的屬性包括聯繫自身的屬性,以及與聯繫相連的實體的屬性。各實體的碼組成關係碼或關係碼的一部分。
教師(教師號,姓名)
學生(學號,姓名)
教授(教師號,學號)
(5) 一個多元聯繫可以轉換為一個獨立的關係模式。
與該多元聯繫相連的各實體的碼,以及聯繫本身的屬性均轉換為關係的屬性,各實體的碼組成關係的碼或關係碼的一部分。
(6) 具有相同碼的關係模式可以合併。
(7) 有些1 :n 的聯繫,將屬性合併到n 端後,該屬性也作為主碼的一部分
這類問題多出現在聚集類的聯繫中,且部分實體的碼只能在某一個整體中作為碼,而在全部整體中不能作為碼的情況下才出現(其它情況本人還沒碰到,呵呵,歡迎指教)。
比如上篇文章介紹的管理信息系統中訂單與訂單細節的聯繫。
關於什麼是聚集,2.3節介紹。
數據抽象的分類
這部分本應在概念設計中介紹的,用到了才想起來,這裡補充一下。
關於現實世界的抽象,一般分為三類:
(1) 分類:即對象值與型之間的聯繫,可以用“is member of”判定。如張英、王平都是學生,他們與“學生”之間構成分類關係。
(2) 聚集:定義某一類型的組成成分,是“is part of”的聯繫。如學生與學號、姓名等屬性的聯繫。
(3) 概括:定義類型間的一種子集聯繫,是“is subset of”的聯繫。如研究生和本科生都是學生,而且都是集合,因此它們之間是概括的聯繫。
例:貓和動物之間是概括的聯繫,《Tom and Jerry》中那隻名叫Tom的貓與貓之間是分類的聯繫,Tom的毛色和Tom之間是聚集的聯繫。
訂單細節和訂單之間,訂單細節肯定不是一個訂單,因此不是概括或分類。訂單細節是訂單的一部分,因此是聚集。
數據模型的最佳化
有了關係模型,可以進一步最佳化,方法為:
(1) 確定數據依賴。
(2) 對數據依賴進行極小化處理,消除冗餘聯繫(參看範式理論)。
(3) 確定範式級別,根據套用環境,對某些模式進行合併或分解。
以上工作理論性比較強,主要目的是設計一個數據冗餘儘量少的關係模式。下面這步則是考慮效率問題了:
(4) 對關係模式進行必要的分解。
如果一個關係模式的屬性特別多,就應該考慮是否可以對這個關係進行垂直分解。如果有些屬性是經常訪問的,而有些屬性是很少訪問的,則應該把它們分解為兩個關係模式。
如果一個關係的數據量特別大,就應該考 慮是否可以進行水平分解。如一個論壇中,如果設計時把會員發的主貼和跟貼設計為一個關係,則在帖子量非常大的情況下,這一步就應該考慮把它們分開了。因為 顯示的主貼是經常查詢的,而跟貼則是在打開某個主貼的情況下才查詢。又如手機號管理軟體,可以考慮按省份或其它方式進行水平分解。
設計用戶子模式
這部分主要是考慮使用方便性和效率問題,主要藉助視圖手段實現,包括:
(1) 建立視圖,使用更符合用戶習慣的別名。
(2)對不同級別的用戶定義不同的視圖,以保證系統的安全性。
(3)對複雜的查詢操作,可以定義視圖,簡化用戶對系統的使用。
物理設計主要工作是選擇存取方法(索引),以及確定資料庫的存儲結構,這裡就不說明了。
