定義
語音分析(SpeechAnalytics)技術,是指通過語音識別等核心技術將非結構化的語音信息轉換為結構化的索引,實現對海量錄音檔案、音頻檔案的的知識挖掘和快速檢索。
呼叫中心保存著大量的客服錄音數據,這些語音中包含著客戶需求、投訴、滿意度、建議、競爭性情報等大量的有價值的信息,但是由於數量巨大,檢索不便,目前普遍只能用於質檢。
科大訊飛VoiceInsight語音分析系統,通過領先的語音分析核心技術,針對客服中心的實際業務需要,可有效的對錄音數據進行自動分析,提取出有效的信息,讓用戶駕馭海量客服錄音數據,輔助客服質檢,進而針對性的改善客服質量,提高客戶滿意度;同時也可以通過系統挖掘到用戶行為數據,進而及時進行準確的市場決策。
語音分析常用的特有參數有:共振峰幅度與頻率,它是語音短時功率譜中能量集中的幾個區域,區域中心頻率稱為共振峰頻率,一般語音有三至五個共振峰。這些共振峰頻率成分的幅度稱為共振峰幅度。有時把共振峰幅度從中心到下降3dB處的頻寬稱為共振峰頻寬。共振峰的參數完全確定了發音中元音的屬性。
用時域方法,採用線性預測計算方法獲得的語音參數,稱為線性預測參數。線性預測參數是語音的時域分析參數,它能準確地獲得聲道的傳輸特性,由時域與頻域參數之間的確定關係,由線性預測參數可轉換求得共振峰參數。利用線性預測參數可以求得另一組參數稱為反射係數,反射係數比線性預測參數具有更好的數值穩定性。由線性預測參數還可以求得另外一套係數,稱為線譜對參數,它們既保留時域計算的特點,又具有反映共振峰頻率特性的內涵。
利用同態信號分析方法,對語音信號進行分析可以得到一組倒譜參數。倒譜參數被認為是更適用於語音識別的一組參數。
語音分析技術常被用於語音編碼壓縮,形成各種中速、低速編碼的新方案。例如子帶編碼、交換編碼、自適應預測編碼、多脈衝激勵線性預測編碼、碼激勵線性預測編碼等。語音識別也是基於語音分析的結果,進行參數的分類與識別,運用不同的參數,可以導致不同的識別結果。利用語音分析技術還可以設計製造用於發音的各種矯正儀器,可供發音器官疾病的治療或聾啞人發音訓練等使用。
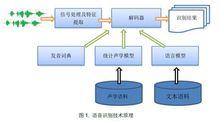 圖1 語音識別技術原理圖
圖1 語音識別技術原理圖語音分析的常用儀器有語圖儀,用於語音動態頻譜的分析及記錄。實時數字語圖儀是一種新的語圖儀。語音分析更常用的方法是利用通用微機加入語音處理設定,通過專用軟體計算獲得。
語音理解
語音理解(speech understanding) 利用知識表達和組織等人工智慧技術進行語句自動識別和語意理解。同語音識別的主要不同點是對語法和語義知識的充分利用程度。
語音理解起源於美國,1971年,美國遠景研究計畫局(ARPA)資助了一個龐大的研究項目,該項目要達到的目標叫做語音理解系統。由於人對語音有廣泛的知識,可以對要說的話有一定的預見性,所以人對語音具有感知和分析能力。依靠人對語言和談論的內容所具有的廣泛知識,利用知識提高計算機理解語言的能力,就是語音理解研究的核心。
利用理解能力,可以使系統提高性能:①能排除噪聲和嘈雜聲;②能理解上下文的意思並能用它來糾正錯誤,澄清不確定的語義;③能夠處理不合語法或不完整的語句。因此,研究語音理解的目的,可以說是與其研究系統仔細地去識別每一個單詞,倒不如去研究系統能抓住說話的要旨更為有效。
一個語音理解系統除了包括原語音識別所要求的 部分之外,還須添入知識處理部分。知識處理包括知識的自動收集、知識庫的形成,知識的推理與檢驗等。當然還希望能有自動地作知識修正的能力。因此語音理解可以認為是信號處理與知識處理結合的產物。語音知識包括音位知識、音變知識、韻律知識、詞法知識、句法知識,語義知識以及語用知識。這些知識涉及實驗語音學、漢語語法、自然語言理解、以及知識搜尋等許多交叉學科。
初步研製成功的語音理解系統稱為HEARSAY系統。它是利用一種公用“黑板"作為知識庫,環繞此黑板的是一系列專家系統,分別提取及搜尋有關音位、音變……等各種知識。以後能進一步達到預計目標的系統是HARPY系統,該系統用語言的有限狀態模型,通過唯一的一個統一的網路把彼此分離的各種知識源集中起來,這個統一的網路,稱為知識編譯器。不同理解系統在利用知識的策略或組織方面各有不同的特點。
完善的語音理解系統是人們夢寐以求的研究理想,但這並非短期內能夠完全解決的研究課題。然而面向確定任務的語音理解系統,例如只涉及有限的辭彙量,有一般比較通用的說話句型的語音理解系統,以及可供一定範圍的工作人員使用的語音理解系統,是可以實現的。因此,它對某些自動化套用領域已有實用價值,例如飛機票預售系統、銀行業務、旅館業務的登記及詢問系統等。
語音識別
語音識別(speech recognition) 利用計算機自動對語音信號的音素、音節或詞進行識別的技術總稱。語音識別是實現語音自動控制的基礎。
語音識別起源於20世紀50年代的“口授打字機”夢想,科學家在掌握了元音的共振峰變遷問題和輔音的聲學特性之後,相信從語音到文字的過程是可以用機器實現的,即可以把普通的讀音轉換成書寫的文字。語音識別的理論研究已經有40多年,但是轉入實際套用卻是在數位技術、積體電路技術發展之後,現在已經取得了許多實用的成果。
語音識別一般要經過以下幾個步驟:①語音預處理,,包括對語音的幅度標稱化、頻響校正、分幀、加窗和始末端點檢測等內容。②語音聲學參數分析,包括對語音共振峰頻率、幅度等參數,以及對語音的線性預測參數、倒譜參數等的分析。③參數標稱化,主要是時間軸上的標稱化,常用的方法有動態時間規整(DTW),或動態規劃方法(DP)。④模式匹配,可以採用距離準則或機率規則,也可以採用句法分類等。⑤識別判決,通過最後的判別函式給出識別的結果。
語音識別可按不同的識別內容進行分類:有音素識別、音節識別、詞或詞組識別;也可以按辭彙量分類:有小辭彙量(50個詞以下)、中詞量(50~500個詞)、大詞量(500個詞以上)及超大詞量(幾十至幾萬個詞)。按照發音特點分類:可以分為孤立音、連線音及連續音的識別。按照對發音人的要求分類:有認人識別,即只對特定的發話人識別,和不認人識別,即不分發話人是誰都能識別。顯然,最困難的語音識別是大詞量、連續音和不識人同時滿足的語音識別。
核心功能
語音分析系統核心功能:
1 、語義解析
訊飛語義解析技術能夠對用戶的自然語言進行自動化挖掘、分析、歸類和展現,為運營分析與決策提供支撐。
2 、場景分割
場景分割技術可自動將一個通話錄音中的用戶語音和坐席語音分離出來,從而方便進行不同側重、更有針對性的檢察、分析,是實現高效語音分析套用的重要支撐技術。訊飛場景分割技術在業界具有最高的準確度,便於用戶針對不同的角色進行統計和分析設計。
3 、情緒偵測
訊飛語音分析系統可對通話中用戶或坐席的情緒進行自動偵測與判斷,一旦發現異常,可及時記錄或預警。訊飛情緒偵測技術結合訊飛在語音及語言技術上的優勢成果,可提供更高的準確率和及時性。
4 、語速檢測
系統可自動對分離後的坐席或坐席語音進行語速檢測,如語速過快則可能用戶很難聽清楚,影響服務質量,而語速過慢則可能坐席技能是不夠熟練、或者工作狀態不佳。
5 、搶插話檢測
系統可自動檢測通話中是否存在搶插話等問題,進行判斷和統計。
6 、靜音檢測
系統可自動檢測錄音檔案中長時靜音(冷場、用戶與坐席均沒有說話)的狀態,靜音時長可在系統中靈活設定與修改。
套用價值
訊飛收集眾多重點行業的語音分析套用需求,並根據此專門設計了語音分析套用系統,可幫助用戶加速套用投產進程,更快獲得收益。此外,訊飛擁有一支經驗豐富的項目組,針對客戶的個性化需求進行定製開發,完善套用系統的功能、報表等,使系統持續適應客戶業務發展的需要。
