簡介
詞法分析(英語: lexical analysis)是計算機科學中將字元序列轉換為單詞(Token)序列的過程。進行詞法分析的程式或者函式叫作 詞法分析器(Lexical analyzer,簡稱Lexer),也叫 掃描器(Scanner)。詞法分析器一般以函式的形式存在,供語法分析器調用。
詞法分析階段是編譯過程的第一個階段,是編譯的基礎。這個階段的任務是從左到右一個字元一個字元地讀入源程式,即對構成源程式的字元流進行掃描然後根據構詞規則識別單詞(也稱單詞符號或符號)。詞法分析程式實現這個任務。詞法分析程式可以使用Lex等工具自動生成。
詞法分析是編譯程式的第一個階段且是必要階段;詞法分析的核心任務是掃描、識別單詞且對識別出的單詞給出定性、定長的處理;實現詞法分析程式的常用途徑:自動生成,手工生成.
編譯
編譯(compilation , compile) 1、利用編譯程式從源語言編寫的源程式產生目標程式的過程。 2、用編譯程式產生目標程式的動作。 編譯就是把高級語言變成計算機可以識別的2進制語言,計算機只認識1和0,編譯程式把人們熟悉的語言換成2進制的。 編譯程式把一個源程式翻譯成目標程式的工作過程分為五個階段:詞法分析;語法分析;語義檢查和中間代碼生成;代碼最佳化;目標代碼生成。主要是進行詞法分析和語法分析,又稱為源程式分析,分析過程中發現有語法錯誤,給出提示信息。
詞法分析程式
組織輸入、掃描、分析、輸出;
接收字元串形式的源程式,按照源程式輸入的次序依次掃描源程式,在掃描的同時根據語言的詞法規則識別出具有獨立意義的單詞,並產生與源程式等價的屬性字(Token)流 .
(1) 只要不修改接口,則詞法分析器所作的修改不會影響整個編譯器,且詞法分析器易於維護;
(2) 整個編譯器結構簡捷、清晰;
 詞法分析
詞法分析(3) 可以採用有效的方法和工具進行處理。
詞法分析程式的功能
完成詞法分析任務的程式稱為詞法分析程式或詞法分析器或掃描器。
從左至右地對源程式進行掃描,按照語言的詞法規則識別各類單詞,並產生相應單詞的屬性字。
單詞
這裡的 單詞是一個字元串,是構成原始碼的最小單位。從輸入字元流中生成單詞的過程叫作 單詞化(Tokenization),在這個過程中,詞法分析器還會對單詞進行分類。
詞法分析器通常不會關心單詞之間的關係(屬於語法分析的範疇),舉例來說:詞法分析器能夠將括弧識別為單詞,但並不保證括弧是否匹配。
針對如下C語言表達式:
sum=3+2;將其單詞化後可以得到下表內容:
| 語素 | 單詞類型 |
| sum | 標識符 |
| = | 賦值操作符 |
| 3 | 數字 |
| + | 加法操作符 |
| 2 | 數字 |
| ; | 語句結束 |
單詞經常使用正則表達式進行定義,像lex一類的詞法分析器生成器就支持使用正則表達式。語法分析器讀取輸入字元流、從中識別出語素、最後生成不同類型的單詞。其間一旦發現無效單詞,便會報錯。
掃描器
詞法分析的第一階段即 掃描器,通常基於有限狀態自動機。掃描器能夠識別其所能處理的單詞中可能包含的所有字元序列(單個這樣的字元序列即前面所說的“語素”)。例如“整數”單詞可以包含所有數字字元序列。很多情況下,根據第一個非空白字元便可以推導出該單詞的類型,於是便可逐個處理之後的字元,直到出現不屬於該類型單詞字元集中的字元(即最長一致原則)。
詞法分析器的設計與實現
源詞法分析器的設計與實現程式的輸入與預處理:
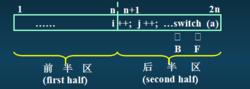
輸入緩衝區
成對且對半互補的輸入緩衝區模式。
n: 取2的整次冪;每個半區的末尾設定標誌“ eof ” 表示讀入該半區的源程式的結束;
B:單詞w開始指針; F:掃描w的指針;
兩個緩衝區的輸入模式
預處理程式: (作用)
1) 減少記憶體空間占用;
2) 減輕掃描器實質性處理的負擔;
預處理程式主要任務: 1) 濾掉源程式中的非單詞成分(如無用空格;換行符等);2) 其他的預處理工作:濾掉注釋;宏替換;檔案包含的嵌入;條件編譯的嵌入.
 詞法分析
詞法分析單詞生成器
單詞生成器
單詞化(Tokenization)即將輸入字元串分割為單詞、進而將單詞進行分類的過程。生成的單詞隨後便被用來進行語法分析。
例如對於如下字元串: The quick brown fox jumps over the lazy dog
計算機並不知道這是以空格分隔的九個英語單詞,只知道這是普通的43個字元構成的字元串。可以通過一定的方法(這裡即使用空格作為分隔設定)將語素(這裡即英語單詞)從輸入字元串中分割出來。分割後的結果用XML可以表示如下:
<sentence > <word >The </word >
<word >quick </word >
<word >brown </word >
<word >fox </word >
<word >jumps </word >
<word >over </word >
<word >the </word >
<word >lazy </word >
<word >dog </word > </sentence >
然而,語素只是一類字元構成的字元串(字元序列),要構建單詞,語法分析器需要第二階段的 評估器(Evaluator)。評估器根據語素中的字元序列生成一個“值”,這個“值”和語素的類型便構成了可以送入語法分析器的單詞。一些諸如括弧的語素並沒有“值”,評估器函式便可以什麼都不返回。整數、標識符、字元串的評估器則要複雜的多。評估器有時會抑制語素,被抑制的語素(例如空白語素和注釋語素)隨後不會被送入語法分析器。
例如對於某程式設計語言的源程式片段:
net_worth_future = (assets - liabilities);
在進行語法分析後可能生成以下單詞流(空格被抑制):
NAME "net_worth_future"EQUALS
OPEN_PARENTHESIS
NAME "assets"
MINUS
NAME "liabilities"
CLOSE_PARENTHESIS
SEMICOLON
儘管在某些情況下需要手工編寫詞法分析器,一般情況下詞法分析器都用自動化工具生成。
