棧式自編碼原理
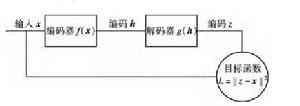 圖 1 自編碼器原理圖
圖 1 自編碼器原理圖棧式自編碼是通過連線多個自編碼器組成的深度神經網路. 訓練自編碼器是一種無監督的過程,它嘗試學習一個恆等函式. 首先,在訓練階段學習一個編碼器,然後通過解碼器對其進行解碼,通過編碼 器的輸入和解碼器輸出之間的誤差,反向調節編碼器參數. 自編碼器的工作原理如圖 1所示,其中 f,g 分別表示編碼器和解碼器。
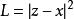 自編碼結構
自編碼結構假設輸入數據為x,x通過編碼器f後可得編碼h = f( x),再通過解碼器g可得到x的重建信號z,即z = g( h) = g(f(x) )。 訓練自編碼器過程中,目標函式用重建誤差 L 表示,本文使用均方誤差作為重建誤差, 。
通過最小化目標函式,算法實現了對自編碼器的訓練. 當訓練完成後,編碼 h 可作為分類特徵,該特徵比原始數據特徵具有更強的魯棒性。
改進的棧式自編碼結構
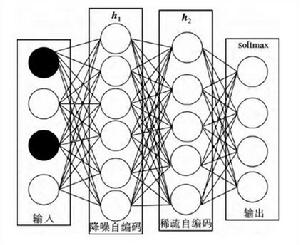 圖 2 改進的棧式自編碼結構
圖 2 改進的棧式自編碼結構一般的深度學習網路總是使用同一種自編碼器或者自編碼器的變體進行深度堆疊. 針對簡 單多層堆疊影響識別率的問題,本文提出一種結合降噪自編碼和稀疏自編碼的深度學習網路結構. 降噪自編碼最大的優勢是學習到的特徵維數不受輸入維數的限制,從而得到比輸入維數大很多的隱層特徵,這也更利於降噪自編碼學習得到數據本身的分布. 由於本文研究的語音情感識別並不是直接通過原始數據學習特徵,而是通過低維特徵進行學習,直接堆疊多層降噪自編碼會嚴重影響識別效果。為此,算法在降噪自編碼後加入稀疏自編碼,從而可以在不過多降低維數的情況下得到更稀疏但信息丟失更少的特徵。由此可見,該結構綜合了降噪自編碼和稀疏自編碼的優點 。
改進的棧式自編碼結構如圖2所示。輸入x∈d0通過降噪自編碼獲得一個比輸入維數更大的隱藏輸出h1∈Rd1( d1> d0) .隨後降噪自編碼的輸出h1進入稀疏自編碼進行稀疏學習,其輸出 h2∈Rd2直接進入分類器.這裡分類器是可選的,本文選擇softmax 分類器.整個訓練過程分為預訓練和微調2 部分. 預訓練採用逐層對深度網路參數進行初始化的方法,該方式比隨機初始化更合理有效,也極大地改善了參數對梯度傳播不敏感的問題。此外,通過反向傳播算法,系統可以進一步微調網路參數,獲得更加強健的模型。
