語言基礎件
語言基礎件指的是自然語言理解的技術開發的基礎工具集,基礎件API可以無縫地融合到客戶的各類複雜套用系統之中,可兼容Windows,Linux,FreeBSD等不同作業系統,可以供Java,C,C#等各類開發語言使用。靈玖的語言基礎件包括:
漢語分詞基礎件漢語分詞基礎件能對漢語語言進行拆分處理,是中文信息處理必備的核心部件。
採用條件隨機場(Conditional Random Field,簡稱CRF)模型,分詞準確率接近99%,具備準確率高、速度快、可適應性強等優勢;特色功能包括:切分粒度可調整,融合20餘部行業專有詞典,支持用戶自定義詞典等。
詞性標註基礎件能對漢語語言進行詞性的自動標註,它能夠真正理解中文,自動根據語言環境將詞語諸如“建設”標註為“名詞”或“動詞”。詞性標註準確率接近99%,具備準確率高、速度快、可適應性強等優勢。
人名地名機構名識別人名地名機構名識別基礎件能夠自動挖掘出隱含在漢語中的人名、地名、機構名,所提煉出的詞語不需要在詞典庫中事先存在,是對語言規律的深入理解和預測。識別準確率達到97%,速度達到10M/s,可在此基礎上搭建各種多樣化的統計和套用。
文檔關鍵字提取基礎件文章關鍵字提取中間件能夠在全面把握文章的中心思想的基礎上,提取出若干個代表文章語義內容的辭彙或短語,相關結果可用於精化閱讀、語義查詢和快速匹配等。
採用基於語義的統計語言模型,所處理的文檔不受行業領域限制,且能夠識別出最新出現的新詞語,所輸出的詞語可以配以權重。
文章關鍵字提取組件:
1、速度快:可以處理海量規模的網路文本數據,平均每小時處理至少50萬篇文檔;
2、處理精準:Top N的分析結果往往能反映出該篇文章的主幹特徵;
3、精準排序:關鍵字按照影響權重排序,可以輸出權重值;
4、開放式接口:文章關鍵字提取組件作為LJParser的一部分,採用靈活的開發接口,可以方便地融入到用戶的業務系統中,可以支持各種作業系統,各類調用語言。
特徵詞發現技術能夠識別出詞典中沒有出現過的辭彙、短語、命名實體、流行用語,是語言文獻分析方面的一把利器。特徵詞發現脫胎於語言自動分詞技術,又是對分詞技術的有效提升和補充。
採用基於語義的統計語言模型,所處理的文檔不受行業領域限制,能夠有效地挖掘出新出現的特徵辭彙,所輸出的辭彙可以配以權重。
特徵詞發現組件的主要特色在於:
1、速度快:可以處理海量規模的網路文本數據,平均每小時處理至少60萬篇文檔;
2、處理精準:Top N的分析結果往往能反映出當時的時事流行語和熱點實體,適合於輿情熱點計算;與國際上著名廠商的技術相比,的各項指標遠遠領先,或許是更懂中文吧;\
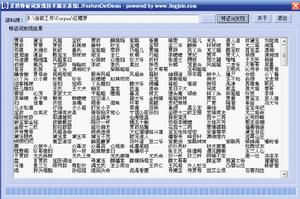 特徵術語自動提取
特徵術語自動提取4、開放式接口:特徵詞發現組件作為LJParser的一部分,採用靈活的開發接口,可以方便地融入到用戶的業務系統中,可以支持各種作業系統,各類調用語言。
特徵詞發現組件可以套用於文本挖掘、知識管理、詞典編輯、輿情監測等多種套用中。英語詞法分析基礎件
英語詞法分析基礎件能對英語語言進行詞性標註、人名地名機構名識別、分句處理,是英文信息處理必備的核心部件。
綜合了本體和機率相結合的機器學習模型,具備準確率高、速度快、可適應性強等優勢。
文本中間件
文本中間件指的是對文本(集合)進行分析挖掘的子系統或模組,中間件提供API或數據接口,可以無縫地融合到客戶的各類複雜套用系統之中,可兼容Windows,Linux,FreeBSD等不同作業系統。的文本中間件包括:
文本摘要基礎件自動文本摘要中間件能夠實現文本內容的精簡提煉,從長篇文章中自動提取關鍵句和關鍵段落,構成摘要內容,方便用戶快速瀏覽文本內容,提高工作效率。
摘要中間件不僅可以針對一篇文檔生成連貫流程的摘要,還能夠將具有相同主題的多篇文檔去除冗餘、並生成一篇簡明扼要的摘要;用戶可以自由設定摘要的長度、百分比等參數;支持處理中、英文語言的文檔;處理速度達到每秒鐘20篇。
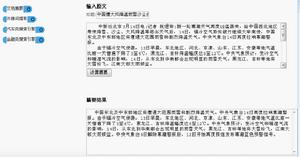 文本摘要
文本摘要文本分類中間件能夠根據文獻內容進行類別的劃分,可以用於新聞分類、簡歷分類、郵件分類、辦公文檔分類、區域分類等諸多套用。
基於內容的文本自動分類和基於規則的文本分類兩種方式,並支持兩種方式的混合分類。能夠進行多級分類,分類速度每秒100篇以上,平均準確率90%以上,能夠進行中英文分類和中英文的混合分類。
文本聚類是基於相似性算法的自動聚類技術,自動對大量無類別的文檔進行歸類,把內容相近的文檔歸為一類,並自動為該類生成標題和主題詞。適用於自動生成熱點輿論專題、重大新聞事件追蹤、情報的可視化分析等諸多套用。
基於核心特徵發現技術,不僅聚類速度快,而且準確率高,並能自動得到類別間的演化趨勢。
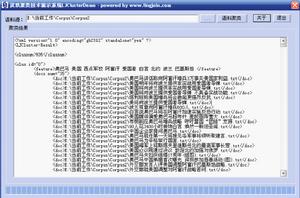 文本聚類
文本聚類文本過濾/文本去重中間件能夠從大量文本中快速識別和過濾出符合特殊要求的信息,可套用於品牌報導監測、垃圾信息禁止、敏感信息審查等領域。
結合內容過濾和規則過濾兩種方式,能夠精確匹配出符合特定要求的內容;用戶可以靈活、方便的更換模板,來實現對不同的主題的過濾。
文本檢索中間件可支持文本、數字、日期、字元串等各種數據類型的高效索引和檢索,適用於信息分析與監控、檔案系統搜尋、資料庫搜尋、桌面搜尋、產品搜尋、新聞搜尋、生活搜尋、BBS社區搜尋、Blog搜尋等多個領域。
檢索中間件核心經過精心設計,具有高擴展性和高通用性,支持32位和64位的主流作業系統;純文本索引速度可以達到8兆位元組/秒,檢索速度達到毫秒級;多級二次開發接口,滿足不同用戶的需求;支持集群並行檢索。
文本褒貶分析中間件能夠自動分析出文章及文章實體所隱含的感情色彩傾向,可用於商品聲譽的網上追蹤,顧客對產品參數的評價對比,公司聲望的網上追蹤,重大事件的民意自動調查,各類事務的基於時間線的情感曲線等。
基於統計和機器學習的技術,支持不限領域的全自動分析,也支持帶有行業詞典的偏重性分析;不僅提供褒貶的權重,還能夠提供體現典型觀點的樣句。
引擎套用件
引擎套用件指的是能夠滿足一定業務操作的綜合性(子)系統,經過簡單的安裝和配置,就可有效地為業務提供功能和數據方面的支撐,可支持Windows,Linux,FreeBSD等不同作業系統。的引擎套用件包括:
通用搜尋引擎通用搜尋引擎實現網際網路海量信息的採集、分析、索引和檢索。基於雲計算平台,爬取分析、建立索引和查詢分布運行在大量分散式節點之上。通過少量的種子連結,就可快速而全面的獲取網際網路上的廣泛信息,並提供高並發的查詢服務,返回客觀而公正的搜尋結果。
垂直搜尋引擎垂直搜尋引擎是專門針對行業細分搜尋和專業資料庫搜尋的需求而打造的套用件。它能夠依據行業用戶的細分特點,方便快捷地獲取專業信息並構建精、準、快的搜尋服務。可以無縫地與現有資料庫系統融合,實現全文搜尋與相關的資料庫管理套用系統的銜接。
套用件可以按照任意指定欄位排序,支持指定欄位的搜尋,也可以搜尋多個欄位,以及複雜表達式的綜合搜尋;支持精確匹配以及模糊匹配等複雜的搜尋條件。
元搜尋引擎是基於現有搜尋引擎之後或之上的搜尋引擎,可以同時查詢多個搜尋引擎的站點,查一個元搜尋引擎就相當於查多個獨立搜尋引擎,可以收到事半功倍的效果。
元搜尋引擎套用件通過簡單的輸入關鍵字(組合),就可以把符合用戶需求的所有信息自動地獲取到本地的資料庫,自動存儲並提供可視化的界面讓用戶進行二次編輯與分析。目前支持網頁、資訊、圖片、視頻、 軟體、音樂、論壇、部落格、Wiki等多個維度的信息。
網路輿情引擎是軟體專門針對網路輿情監測的工作要求和特點而打造的,不僅採用了專業化的搜尋引擎技術,還融入了更加智慧型的數據挖掘技術,可以按照文章、人物、地點、機構、話題以及事件等六維空間對網路信息進行整合挖掘。
引擎能夠實時收錄反映口碑民情的新聞評論、論壇帖子和部落格文章,建立一個以日為周期的網路輿情監測平台,同時配上以周或者以月為基礎的輿情分析報告,從而提供了一個便捷、科學、可操作性的輿情工作平台。
地址搜尋匹配引擎可以快速便捷地進行地址標準化,自動計算郵編,並能夠進行地址的一致性判定和信用評估。
地址搜尋匹配引擎具有智慧型、高效、自學習三大特點。智慧型主要體現在系統可以智慧型識別用戶輸入的真實意圖,智慧型模糊匹配後台知識庫,進行邏輯推理,並給出邏輯推理的知識依據;高效體現在本系統可以單機每秒處理5000條記錄;自學習是指整個系統無需人工干預,直接導入正確標註的郵編數據,即可完成整個系統的學習,自適應地調整處理結果。該引擎可套用於郵政、銀行、保險以及廣泛的公眾服務。
