
定義
語言信息處理 (LIP,Language Information Processing)有時也稱作自然語言處理(NLP, Natural Language Processing)或自然語言理解(NLU, Natural Language Understanding), 自然語言處理是上位概念,包括理解和生成,而語言信息處理可以分別理解為語言信息|處 理”和“語言|信息處理”。 前者指的是對各 種語言信息進行處理, 後者指對語言本身進行信息化的處理。 這幾個概念的具體闡述請看下文“幾個常見術語的辨析”。
語言信息處理源自20 世紀 50 年代 和 60 年代的機器翻譯,其基本原理是結合其他邊緣學科的知識, 解決機器在語言理解和生成中語法和語義消岐問題。 自然語言處理系統首先把指令“Delete file x”在音位學平面轉化成音位系列“/ dilit fail eks/”,然後在形態學平面把這個音位系列轉化為語素系列“delete” “file”“x”,接著在辭彙學平面把這個語素系列轉化為單詞系列並標註相應的詞性:(“delete”VERB)(“file”NOUN)(“x”ID),在句法學平面進行句法分析, 得到這個單詞系列的句法結構,用樹形圖表示,在語義學平面得到這個句法結構的語義解釋:delete-file (“x”),在語用學平面得到這個指令的語用解釋“rm-i x”,最後讓計算機執行這個指令。
語言信息處理技術發展到今天,其內涵和外延已經發生了巨大的變化,美國計算機科學家 Bill Manaris 在 1999 年將自然語言處理可以定義為研究在人與人交際中以及在人與計算機交際中的語言問題的一門學科。 自然語言處理要研製表示語言能力(linguistic competence)和語言套用(linguistic performance)的模型,建立計算框架來實現這樣的語言模型, 提出相應的方法來不斷地完善這樣的語言模型, 根據這樣的語言模型設計各種實用系統, 並探討這些實用系統的評測技術。
發展
馮志偉先生將語言信息處理的發展分為三個階段:1)萌芽期(20世紀40年代末至20世紀60年代中期)。其理論來源是形式語言學派,語言處理的機率算法被用於機器翻譯,這一時期的基礎性研究為自然語言處理的理論和技術奠定了堅實的基礎。2)發展期(20世紀60年代中期到80年代末期)。其標誌是機器翻譯金字塔”(MT Pramid),語義分析在機器翻譯中越來越受到重視。3)繁榮期(20世紀90年代至今)。其重要標誌是在基於規則的技術中引入了語料庫方法,其中包括統計方法、基於實例的方法、通過語料加工手段使語料庫轉化為語言知 識庫的方法,同時網路技術的發展對於自然語言處理產生了的巨大推動力。但是,語言信息處理也遇到了非常大的挑戰。首先,對自然語言的處理還一 直無法突破單句的界限,從而阻礙了複句和語篇的理解和生成技術的研究。其次,基於句法—語義規則的理性主義方法受到質疑,動態語義分析模型是亟待解決的關鍵性難題。 再次,語料庫的建設和基於語料庫語言學的自然語言處理技術還無法滿足大規模真實文本的處理的戰略目標。最後,現有的語言信息處理無法有效承擔挖掘大數據商業價值的任務,企業越來越依賴於數據分析師,語言處理技術越來越讓位於信息處理技術, 語義網還沒有成型的時候, 語用網的時代就已經到來了。
研究對象
觀察計算機系統所處理的語言信息,大致上可分為兩類:一類是模式信息 ,如聲音和圖象,它們是語音識別和文字識別的前期處理對象;另一類是符號信息,如書面語的文本或者作為漢語語音識別結果的音節符號,它們是代碼化了的,或者更確切地說,計算機只將每個字元的編碼看作處理對象。利用鍵盤進行人機會話,對存儲於計算機系統內的文本進行檢索、校對、翻譯、做摘要,乃至讓計算機“理解”人類的語言, 所有這些工作,計算機所處理的對象都是符號信息。所以說通常文獻中所說的“語言信息處理”是指其處理對象為符號信息。
基本模型
機器翻譯系統是典型的 、其套用價值也是最明顯的自然語言處理系統。當代機器翻譯系統的模型可用圖 1 表示:
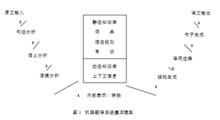 語言信息處理
語言信息處理圖 1反映的是基於規則方法的機器翻譯系統的基本模型。90年代 ,機器翻譯研究還發展了基於統計與 基於實例的各種模型。不過,當前世界上實際運行的機器翻譯系統基本上仍以基於規則的模型為基礎。從這個基本模型可以了解到,機器翻譯系統的基本原理乃是要素合成原理。首先將原文的句子分解成基本構成要素(詞 ,慣用語等),這樣才可以查詞典,才好運用語法規則找出句子的結構,這就是句法分析(包括詞法分析),並通過語義分析及語境分析排除不適當的歧義,從而形成原文的機器內部表示。於是可在結構的層次上進行轉換,得到譯文句子的結構,並選擇適當的譯詞,以後再進行詞序調整、虛詞增刪及形態變化,最終得到譯文的表層句子。
基礎
作為一種現代學術思潮,計算語言學(Computational Linguistics)被界定為“語言學的一個分支學科,研究人類語言行為的計算機模擬,特別是像機器翻譯和言語綜合這 樣的套用”。 可以說,計算語言學是一門產生於計算機科學和語言學接合部的邊緣性交叉學科,同時涉及文科、理科和工科三大知識領域,它最能賦予語言學以現代化特色。這門學科的建立和發展,使得屬於人文科學傳統學科的語言學在現代科學體系中的地位有了明顯的變化,它不僅是各門科學的基礎部分,而且成為一門帶頭或先導科學(a pilot science),獲得了與哲學和數學同等 的學術地位,其重要意義已為國際學術界達成共識。
面向計算機的語言學理論研究在方法論上的取向應當是十分明確的,因為“現代科學知識中方法論的地位愈來愈高,作用愈來愈大。如果沒有新的科學方法和新的研究手段,那就很難創造新的科學理論”。
計算語言學的學科交叉性決定了語言理論研究方法的選擇,它必然是代表實證主義語言觀的描寫取向,並且必須以套用價值為先導。唯此方可把所觀察到的語言現象形式化、算法化,並使之在計算機上加以實現。目前,計算機的研製已發展到第五代,其特點是帶有人類的智慧型,關鍵在於要求機器更好地識別和處理自然語言。有專家認為,開發第五代計算機的難點不在技術,而在語言分析。因此,加強語言學基礎理論及其套用技術的研究具有十分重要的現實意義。
辨析
在語言信息處理領域,不同的時期和不同的使用場合,有幾個內涵類似的術語被用於指稱大致相同的內容。在各種文獻和媒體中,我們經常可以看到“自然語言處理(Natural Language Processing) ”、“自然語言理解(Natural Language Understanding)”、“計算語言學 (ComputationalLinguistics) ”、 “語言信息處理(LanguageInformationProcessing)”這幾個術語,它們常常被混用。事實上這幾個概念雖然內涵大致相近,使用上卻各有側重。
自然語言處理是力圖使計算機理解和運用自然語言,從而實現用自然語言直接進行人 機通信的技術。計算機直接處理自然語言,無需人去適應機器,這將是一個更自然且消除 了異化的人機環境,計算機將能幫助人類完成更多的工作 。簡而言之,它是研究如何利用計算來理解和生成自然語言的。
自然語言處理也稱為計算語言學,二者常被當成同義詞,它們所指的是同一個研究領域,只是在使用時稍有不同。通常的使用習慣是,在偏重於說明理論時,使用計算語言學這一術語;而偏重於說明方法時,常使用自然語言處理 。
有的學者認為自然語言處理和自然語言理解也是同義詞 。我們認為自然語言處理的外延要更廣一些,是後者的上位概念,因為它不但包括自然語言理解,還應包括自然語言生成。
語言信息處理有廣義和狹義的不同理解。廣義的語言信息處理,是指對人類語言聽、說、讀、寫、貯存、複製、教學、傳播等套用方面所運用的技術、手段和方法。從這個意義上說,語言信息處理技術的發展經歷了四個階段:以雕刻作為記錄技術的“甲骨石木” 階段、以書寫作為記錄技術的“筆墨紙硯”階段、以打字機和印刷技術為標誌的機械與機器階段以及以計算機技術為基礎的信息化階段。狹義的語言信息處理是指用計算機對自然語言的音、形、義等信息進行處理,即對字、詞、句、篇章的輸入、輸出、識別、分析、 理解、生成等的操作與加工 。從字面上看,“語言信息處理”這個短語可以有兩種結構切分方式: “語言信息|處理”和“語言|信息處理”。前者指的是對各種語言信息進行處理, 對應廣義的理解;後者指對語言本身進行信息化的處理,對應狹義的理解。在實際運用中,語言信息處理涉及到多個套用領域,比如語言教學、語言傳播與交際等,所以這個術語偏重於指套用。
因此,“計算語言學”、“自然語言處理”、“語言信息處理”這組內涵相近的術語,分別側重於指同一學科對象的理論、方法和套用三個方面。
套用
語言信息處理是屬於信息處理的範疇,即運用現代信息科學技術對自然語言的各個方面進行信息化處理。這些方面包括語言機制的運作、語言規律的挖掘、語言的教學與傳播、 語言的交際與運用。因此從套用的角度來看,語言信息處理的任務和學科內容可用“層面”概念來表述,研究發現,語言信息處理應包含四個層面:語言運作技術信息化、語言研究工具信息化、語言教學手段信息化、語言交際方式信息化。這四個層面是語言學和信息科學的不同部分以及其他的學科相結合的產物,是在信息化時代語言系統運作和套用的新模式。
語言運作技術層面
語言的運作包括語言信息的編碼、傳遞和解碼。其中編碼和解碼由人的大腦完成,信息傳遞通過外部信道進行。人類對於語言的使用主要依賴兩種能力:一種是辭彙記憶能力,另一種是語言規則的套用能力,即如何將詞、短語和句子組成順序性或層次性的結構的能力。辭彙的記憶構成了人腦中的心理詞庫 (mental lexicon),而規則的套用能力則來源於語 言習得過程中長期積累而形成的心理語法 (mentalgrammar) 。這兩種能力共同驅動大腦進 行語言信息的編碼和解碼,從而實現自然語言的生成和理解。 語言運作技術的信息化,就是讓計算機模擬大腦的語言運作機制,實現機器自動生成 和理解語言信息。在當今信息爆炸的時代,人們日常需要接觸和處理的語言信息數量驚人 的龐大,僅靠人力已經難以應付,因此迫切需要藉助計算機來處理這些海量的語言信息, 以減輕勞動強度,提高工作效率。所以,從這個角度上說,自然語言處理的目標並不僅僅是實現通過自然語言進行人機對話,還需要讓計算機在一定範圍內代替人腦完成各種以自 然語言為對象的複雜工作任務,比如機器翻譯、自動文摘、信息檢索、信息過濾、語音識別與合成等等。 語言運作技術信息化的核心是自然語言的理解和生成。這涉及到語言學、計算機科學、 數學、哲學、邏輯學、認知心理學、物理學等學科領域,其關鍵問題是要科學合理地揭示自然語言的運作機制和規律規則, 並建立行之有效的數學模型和語言知識的形式化表示方法。根據人腦處理語言的兩種主要能力,我們認為語言運作技術信息化的實現主要依賴於 兩個方面的工作:語言資源建設和語法、語義的算法設計。機器理解和生成自然語言的根 本前提是我們預先告訴機器足夠多的語言知識 ,有了這些語言知識庫的支持,機器才能根 據自然語言的語法規則建立的數學模型來模擬人腦的語言運作機制,從而實現信息化的語 言運作。因此,語言資源建設是基礎中的基礎。
語言研究工具層面
語言學是一門實證科學,研究語言系統本身是怎樣運動和發展的。實證研究通常先做出一些假設,然後運用觀察、歸納和類比等方法得到結果來檢驗假設的真實性。 語言的內在規律存在於語言事實中,因此語言學研究結果的科學性取決於對語言事實 觀察和描寫的精度、廣度和深度,以及對語言規律解釋的邏輯周延性。語言事實浩如煙海, 語言規律也並不具備科學公理般的嚴謹,因此語言學的研究一直是一個艱難的探索過程, 在研究的工具和技術上,往往離不開從其他學科中的借鑑。 事實上整個科學發展史,語言學的研究在各個歷史階段一直在從當時主導的學術思潮 和科學技術中吸收養分。比如在中世紀的歐洲,經院哲學大行其道,表現在語言方面就是 傳統語法的推行。傳統語法亦稱規範語法,它像法律條文一樣,硬性規定一套語法規則, 讓人們按照這些規則去說去寫,而不顧及它們是否與實際生活中的語言相符,也不考慮語言本身的發展變化。文藝復興時期自然科學擺脫了神學的束縛而迅速發展起來,語言學家們也開始歷史、客觀地進行語言研究。那時的語言學家們吸取了生物進化論和動植物分類 學的觀點和方法,對語言進行對比和譜系分類,並在此基礎上發展起來了歷史比較語言學。 到了十八世紀拉瓦錫引導的“化學革命”對語言研究有著巨大影響。語言學家們開始採用化學結構式的方法來研究語言,將語言劃分為不同層次:音素、語素、詞、詞組、分句、 句子,力圖從一堆素材里按照嚴格的分析手段,一步一步地得到其中的結構成分。在二次 世界大戰後,科學技術出現了一系列劃時代的進展,對事物的研究從定性的描述逐漸過渡 到定量的研究,數學在整個自然科學體系中的地位日益凸顯,與語言學也發生了密切的聯 系,生成語言學應運而生。生成語言學家把語言看成是一個數學的目標,建立了類似於數 學中的公理和推理規則 。 在當前的資訊時代,信息技術已經成為所有學科的輔助研究工具,語言學也不例外。語言研究工具的信息化包括兩個方面,即語料獲取、存儲、檢索的信息化以及語言規律與語言學知識發掘過程的信息化。這涉及到信息技術的多個方面,如文本處理技術、網路技術、資料庫技術、軟體工程以及計算語言學本身的分詞技術、語料庫技術等。 與人腦相比,計算機的顯著優勢在於其海量的存儲功能和高速的數據檢索、排序與計算功能,這兩個方面正是語言學研究特別需要的。觀察到的語言知識越全面、越細緻,得 到的語言規則越精確、越科學,因此大規模的語料庫是現代語言學研究必不可少的工具; 而各類分析處理語料的專門軟體和資料庫工具,則會使語言學家如虎添翼,極大地提高工作效率。 就目前的狀況而言,各種類型的數位化語料庫如雨後春筍般不斷湧現,其規模也越來 越大,結構越來越科學,內容越來越豐富,這部分資源已經在語言學研究中發揮著重要的作用。可是另一個方面,專門為語言學研究而開發的輔助軟體卻十分匱乏,這種狀況嚴重製約了語言研究工具信息化的進程。
語言教學手段層面
語言教學是套用語言學最早和最主要的研究領域,語言教學方法和教學手段的探索則 一直貫穿整個套用語言學的發展歷史。現代信息技術與語言教學的結合源於現代計算機技 術發明後不久。在計算機出現後十年左右時間,美國就開始了計算機輔助教學的研究,二 十世紀五十年代則套用到語言教學領域,到了六十年代計算機輔助語言教學(Computer Assisted Language Learning,簡稱 CALL)已經逐漸盛行起來,迄今為止已有四十多年的歷史。 四十多年來語言教學觀經歷了從行為——結構主義到認知主義再到社會認知主義的變遷。 同時計算機技術也實現了從大型主機到個人計算機再到網路型的、多媒體計算機的巨大飛躍。在二者的共同影響下,語言教學手段信息化也取得了長足的進步。進入二十一世紀以來,多媒體與網路技術、虛擬學習環境、人工智慧在語言教學中的運用,為以網路為中心的計算機輔助語言教學提供了更加廣闊的天地。無論從 CALL 本身的發展還是人們對 CALL 的認識與運用,都推動了信息技術與語言教學(尤其是外語教學)的整合發展。CALL 的作用也受到了前所未有的重視,被視為外語(與第二語言)教與學的“利器”,已成為一種流行的語言教學手段。 技術的迅速發展和理論研究的相對滯後帶來了一系列的問題和矛盾,引發了諸多的爭鳴。比如教師和學生在新的語言教學模式下角色的定位問題、語言學習過程對機器的過分依賴引發的技術異化問題、語言學習者的情感因素與情感互動需求與缺乏情感冷冰凍的機 器之間的矛盾、信息化環境下語言習得規律的變化與發展等等。這些問題是語言教學手段信息化必須面對的問題,期待著進一步的理論研究。對這些問題的深入研究,是語言教學 手段信息化從目前廣泛的實踐嘗試階段走向理論發展成熟階段所面臨的新挑戰,也是時代 賦予語言信息處理研究的歷史使命。
語言交際方式層面
語言交際方式分語音交際與文字交際,從古到今它們分別沿著不同的技術軌跡向信息化的方式發展。語音交際經歷了空氣傳播——有線電(電話、有線電視和廣播)——無線電(對 講機、行動電話、無線電視和廣播)——語音數字編碼技術(網路電話、語音聊天)的發展歷程,文字交際則經歷了書信(鴻雁傳書、郵政傳遞)——電傳電報傳真(FAX)——無線尋呼機(BP)——電腦網路(EMAIL、BBS、IRC)——手機簡訊(SMS)的發展歷程。 在網路通訊和手機等現代移動通訊高度普及的今天,信息化交際是除了面對面的語言交際外人類最主要的交際方式。據統計,2008 年全球手機簡訊傳送量高達 2.3 萬億條。來 自中國電信部門的統計數據顯示,僅 2009 年 1 月 25 日除夕當天,通過中國行動網路傳送 的簡訊達 46 億條,通過中國聯通網路傳送的簡訊達 4.97 億條 。這從一個側面反映了人類 的語言交際方式已經全面進入了信息化時代。人類交際過程中對語言信息的傳送與反饋具有很強的即時性要求,我們可以預言這種需求決定了今後以手機為代表的嵌入式手持信息處理終端必將主導語言交際方式信息化發展的主流方向。因此,手持嵌入式系統的語言技術套用解決方案是語言交際方式信息化的 關鍵因素。這些技術包括嵌入式系統中的字型檔設計及其調用技術、字元顯示技術、文字輸入技術、語音處理技術、文本檢索與信息抽取技術等 。
