引言
搜尋引擎是資訊時代的基礎服務之一,搜尋引擎服務的核心為全文檢索。常用的全文檢索,一般以關鍵字的檢索為主,對於不同的語言需要不同的處理方法。
對於常規的全文搜尋來說,基本的功能就是分詞加上倒排序表。
全文檢索對於分詞技術和字典的依賴,使得全文搜尋實施的難度加大。對於不同語種需要不同的字典和分詞技術,對於同一語種不同專業的文檔也需要不同的分詞技術和字典,不同字典和分詞技術也影響了系統的通用性。搜尋引擎的服務隨著信息量的增大,存在索引時間長,搜尋速度慢等問題 。
以語句為單位,構建基於語句的搜尋引擎,繪製文字的語義樹,搜尋按自然語句的形式搜尋,並提供自然語句或者辭彙後續的文字,以此進一步的搜尋。
全文索引技術綜述
全文索引主要解決文字信息的搜尋問題,結構化信息的檢索依託資料庫的索引技術實現,對於文檔類的信息,就需要轉換為結構化信息的全文搜尋來完成。
為了提高索引的效率,套用了基於字典的關鍵字索引,引進分詞技術,同義詞和停止詞技術,這樣做主要目的是減少索引的個數,通過詞的引入減少倒排序的存儲來實現效率的提升。關鍵字的搜尋,沒有考慮字詞之間的關係,沒有語義方面的考量。
全文索引隨著數據量的增大,會出現效率低下的問題,為了提高效率,會修改配置,降低索引的維度和次數來提高,例如給定關鍵字條索引,自動分析文檔編寫摘要,用摘要索引來代替全文索引。為了保證搜尋匹配的效率, 有效的索引方法是十分關鍵的, 特別是需要考慮語義匹配的時候, 索引就會變得更為複雜 。
如何通過語句來進行文檔和語句的關係索引,直接用自然語句進行搜尋,是本文研究的課題。
語句索引和檢索
有了基於字詞的全文索引,自然有基於語句的全文索引。由於行文規則的確定,語句的數量是一個可測的集合,遠小於基於字詞組合的集合維度,數量級小,粒度大,索引的存儲量相對小。
語句索引技術需要解決的核心問題主要有:
1、語句索引問題。
2、查詢語句的匹配問題。
語句的索引主要通過語義樹來實現,對語句進行語義特徵編碼,通過連結表的形式來存儲。語句的匹配問題有很多方法,選擇實用便捷的方法是系統主要考量的 。
語義特徵編碼
語句的索引問題是語句索引和搜尋的核心。利用語義特徵編碼解決語句的統一編碼問題,不再基於自然語句做字元串的匹配,解決了語句匹配的問題。通過特徵編碼實現語句的快速查找,組織語義樹實現了文章信息的自然索引,可以順著文字的脈絡進行搜尋。
語義特徵編碼定義:實現語句中的文字統一映射到一個線性空間,文字在語句中的特徵信息編碼主要由該文字本身和該文字在語句中之前的文字決定的。該特徵編碼決定了文字和語句中之前文字,關聯文字順序的信息。通過該編碼可以直接查詢到該語句片段。下面介紹採用線性的維度來構建語義樹。
語句中的文字通過增量哈希算法映射到統一的線性空間,形成特徵標識,最長可以為128bit,一般64bit即可,空間容量為2的128次方或2的64次方。
語義特徵編碼採用哈希算法實現,具體的實現方法如下:
1、對於語句排列定義如下:
i.最小文字單元為w;
ii.W表示句中第i個最小文字單元;
2、特徵序列編碼如下:
i.T表示W的特徵編碼
3、公式如下:
T=Tencode(T+w);當i=0時為T=Tencode(w)
4、Tencode為特徵編碼公式。一般為hash算法,然後取一定的位數。
特徵編碼的意義主要是利用哈希算法,構建句中文字最小單元的特徵編碼,特徵編碼主要指的是語句截至到該最小單元的編碼。
統一的編碼格式映射到線性的空間,方便檢索。32位的編碼空間有一定的碰撞幾率,64位幾乎沒有碰撞。
利用語義特徵編碼保存一段有序的文字片段,存儲和檢索均採用該特徵編碼。
語義樹構建
語義樹指的是用樹形圖來表示語句,樹的節點為最小文字單元,最小文字單元一般來說指的是文字辭彙,中文的為單個文字,英文的為辭彙。通俗來講就是文字的樹。
建立語義樹,先給出語義三元組的定義:
{T,W,T};當i=0時,為{T,W,0}或者{T,W}。
具體含義為:語義特徵信息編碼,文字,前語義特徵信息編碼。
語義三元組構建語義樹。
語義三元組包含了最小文字單元的上下連線關係。
用鏈式存儲的方式來構建語義樹。三元組存儲到資料庫中,文字的特徵信息為唯一索引,為了查找方便,在前特徵信息編碼建立索引,方便語義的檢索,
語義樹的作用主要有:
1、直觀的描述語句中文字和文字之間的連線;
2、給定語句的前文,可以方便的查找後續的文字;
3、語義匹配。進行語句的匹配,匹配檢索的語句和存儲的語句。
語義樹存儲
通過語義樹的構建提供一種快速匹配語義的方法,根據語義和文檔的關係,查找到相關的文檔信息。語義樹的存儲主要包括:語義樹、語義樹和文檔的關係和文檔。
語義樹的節點分為三類節點:位於句首的節點,其前節點或者父系節點為空;句中節點;句尾節點。由於語言的多樣性,有的節點可能同時具有三類中的一項或者多項。
在實驗系統中,“生物實驗室”的語義樹如下:
 自然語句搜尋
自然語句搜尋圖 1 “生物實驗室”語義樹
圖1為“生物實驗室”在系統中的語義樹存儲的展示圖,展示以“生物實驗室”為根節點的語義樹,每個文字均為一個節點,有的節點關係到文檔的記錄,有的僅僅是一個承接上下文的連結節點,或者說給節點沒有文檔標識。
點擊有文檔標識的節點既可以展示相關文檔。
 自然語句搜尋
自然語句搜尋圖 2 文檔信息顯示
“李白的詩”和“杜甫的詩”的語義樹如下:
 自然語句搜尋
自然語句搜尋圖 3 “李白的詩”和“杜甫的詩”語義樹
圖中展示的聯繫在一起的文字之間也是有連線符的,這樣的處理僅僅表示文字之間沒有分支。
語義樹展示的是字與字的關係,在自然語句中的聯繫形式。通過語義三元組的存儲,實現了自然語言的語義樹。
語義樹的存儲是通過資料庫來實現的。語義樹存儲四個欄位:文字特徵編碼,最小文字單元,前文字特徵編碼,是否為句尾。一般來說,在文字特徵編碼上建立唯一索引;前文字特徵編碼建立索引,這樣方便語義樹的查詢。
為了實現全文搜尋,還需要存儲語句和文檔的關係表和文檔。文檔和語句的關係表主要存儲兩個欄位:語句尾部特徵編碼和文檔識別Id,並以語句特徵標識為主鍵建立資料庫表。
如果需要存儲文檔,則建立文檔存儲表,一般在文檔ID上建立索引即可。
語義搜尋
文獻 提出語義相似度計算,認為語義相似度計算時自然語言處理關鍵技術之一。
要進行語義搜尋首先需要進行語句的適配,考慮到搜尋的效率,採用最大前綴匹配方法匹配語句,即在存儲的語句中找到最大前綴的匹配,這樣有利於簡化搜尋,提高搜尋的效率。
搜尋主要按以下步驟的來完成:對搜尋的語句進行語義特徵編碼,找到最大的匹配,然後根據最大的匹配找到適合的語句,最後根據該語句找到相關的文檔。
語義搜尋簡化搜尋的方式,主要進行前綴的最大化匹配,主要基於的前提是隨著語料的增多,可以滿足查詢;還在於按自然語言的習慣搜尋,而不是斷章取義的方式來進行。這樣簡化搜尋的空間,有利於快速搜尋。
語義搜尋的流程如下:
1、搜尋語句的特徵編碼,形成序列集合{T;i=0,1,2...n-1};
2、從T開始搜尋,如果有則找到,否則搜尋T;
3、假定找到T,如果T有文檔標識,則利用特徵編碼找文檔;
4、否者沿著T查找該特徵序列所在分支的文檔標識。即查找前特徵編碼為T的特徵編碼,一直遞歸找到位置。
系統實現與測試
開發語句的搜尋服務系統,採用資料庫存儲,主要包括:語義樹的存儲,語句和文檔的關係存儲和文檔的存儲。實現基於語義樹的查詢和聯想功能。
以百度知道的數據為例,27901630的標題索引,全文字系列,採用標點符號分割,非空格分詞的語言空格作為斷句符號。語義樹單元存儲條目為245009346,平均每標題占用8.78個。
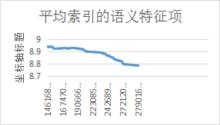 自然語句搜尋
自然語句搜尋圖 4 文檔數和語義特徵存儲平均值
結束語
採用對文本信息進行特徵序列的編碼,形成相關的語義樹,實質上提供了一種基於語句的全文搜尋服務,一種基於語義樹的索引方法和系統,一種不再依賴於分詞的全文索引引擎,一種適合不同語種的全文搜尋引擎,具有存儲空間小,索引速度和查詢速度快等特點。系統已經實現通過語義樹的索引全文,並提供相關的服務。
