索引搜尋
二分搜尋方法盲目地以數據組中的中間關鍵字開始搜素。雖然這已滿足了許多套用,但還有其它的方法提高其搜尋效率。靈活的索引搜尋方法使用了一個索引表以加快搜尋速度。索引表中含有數據組的子數據組。搜尋從該索引表開始,一旦表中某項匹配上,則搜尋繼續在有序數據組中進行。根據表中的信息,搜尋子程式可以縮小其搜尋的範圍。
必須通過從有序數據組中選擇出數據項來對索引表進行初始化。數據項按等距離選擇,而不是考慮搜尋關鍵字的前幾個字元。當數據一旦被修改並重新排序之後,要對索引表重新進行初始化。
為了解索引搜尋是如何工作的,讓我們來考慮一個例子。假如我們要在下列數據組中查找Lindar:
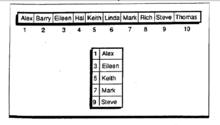
Alex Barry Eileen Hal Kelth Linda Mark Pick Steve Thomas
索引表中必頂存放該數據表中的某些關鍵宇,如圖所示。索引表中有五項。為使索引搜素方法有效,搜尋表必須小於要搜尋的數據組。要尋找搜尋關鍵字U。如,首先要搜素素引表。把素引表中的項逐一與搜素關鍵字比較,一直到找到大於或等於該搜素關鍵字的項為止。在我們的例子中,搜尋到Mark時停止。然後,我們根據Mark對應的下標值(7)以及對應前一關鍵字Kelth的下標值(5)在源數據組中尋找搜素關鍵宇。正如你所看到的,索引表能夠幫助我們縮小在源數據組中尋找搜尋關鍵字的範圍。
 索引搜尋
索引搜尋索引包含與安裝的內容中的主題相關聯的關鍵字列表。 每個主題可能有多個關鍵字與之關聯,並且每個關鍵字可能與多個主題相關聯。 和使用書中的索引一樣使用此索引。
索引搜尋的實現
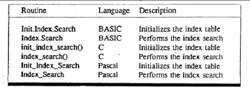
由於需要一定的數據結構和額外的代碼來表示和處理索引表,因而與前面介紹的所有其它搜尋方法相比,索引搜尋方法的實現較為複雜。為實現索引搜尋方法,我們用了兩個子程式。我們在圖中用各種Turbo語言把它們列出。
 索引搜尋
索引搜尋在進行搜尋之前,必頂調用Inlt-Index-Search,初始化子程式來建立索引表。該子程式遍歷以數組方式存放的數據組並把相應的關健字放人索引表中,我們必須確定在數據組中關性字的間距由下面的語句計算出來:
Skip:=Numdata div MAX-TABLE-SIZE;
這裡的Numdata是數據組據組中的元素個數。MAX-TABLE-SIZE是索引表的長度。完成該計算之後,就可以用REPEAT-UNTIL循環把相應的關健字放在索引表中,要記住索引表中的每一項都含有兩個成份:關鍵字及其在數據組中的位置。在Turbo C和Pascal中,索引表用記錄數據表示。在Turbo BASIC中,用兩個數組表示.有關實現的更加詳細的
說明將對應實現的各種語言加以討論.
現在我們已對索引表的初始化作了說明,索引方法的實質,就是把數據組,我們稱之為搜尋數組,以及索引表作為參數傳遞。
要使用索引查找主題
在“索引”選項卡上,執行以下任一任務:
備註 當篩選器按鈕顯示在帶有框線的較暗的背景上時,條目必須包含你指定的文本。 如果沒有顯示背景和框線,則條目必須以你指定的文本開頭。
您可以通過進入關鍵在“索引”中定位信息。 本主題建議使用有用的索引方式搜尋“幫助”。
索引搜尋提示
使用索引是直接的進程;但是,了解輸入關鍵字可以提高索引搜尋的工作效率的最佳方式。
通用準則
•在索引項中滾動。 並非所有主題都用相同方式已編制索引,且最能夠幫助您的主題在列表中可能比預期的高或低。
•因為索引的忽略,省略如 "an" 或 "the" 的文章。
•如果未找到預期的項,則反轉您輸入的單詞。
•例如,如果“調試內聯程式集代碼”不顯示任何相關項,嘗試鍵入“assembly code, debugging inline”。
•篩選器與“索引”選項卡一起使用,以減少結果數。
語法提示
如果找不到您輸入的詞或詞組,請嘗試以下操作:
•鍵入單詞的前幾個字母或根。 通過輸入一個部分字元串,可以獲取對索引單複數形式的關鍵字的主題。
•例如,輸入“propert”開始對 properties 和 property 的搜尋。
•輸入要完成任務的謂詞的動名詞(-ing)形式。 若要查找更為具體的索引項,請追加您想要的準確描述的單詞。
•例如,鍵入“running”獲得更多項 或鍵入“running programs”則獲取的更少。
•輸入獨立的形容詞。 若要縮小結果,請追加您想要準確描述的單詞。
•例如,輸入“COM+”得到廣泛的結果項而用“COM+組件”獲取更少。
•輸入要查找的同義詞或動詞。
•例如,如果輸入了“building”動名詞嘗試代替“creating”。
索引搜尋引擎
索引搜尋引擎就像一個電話號碼簿一樣,按照各個網站的性質,把其網址分門別類排在一起,大類下面套著小類,一直到各個網站的詳細地址,一般還會提供一些各個網站的內容簡介。用戶不使用關鍵字(Keywords)即可進行查詢,只要找到相關目錄,就完全可以找到相關的網站(注意:是相關的網站,而不是這個網站上某個網頁的內容)。儘管如此,這類搜尋引擎也會提供關鍵字查詢功能,但在查詢時,它只能夠按照網站的名稱、網址、簡介等內容進行查詢,所以它的查詢結果也僅僅是網站的URL地址而已。由於這類搜尋引擎的數據一般由網站提供,因此它的搜尋結果並不完全準確,並不是嚴格意義上的搜尋引擎。目錄索引中最有代表意義的當屬Yahoo!、Open Directory、LookSmart等。 與之相對的另一種搜尋引擎是全文檢索搜尋引擎。
全文檢索搜尋引擎
這類搜尋引擎是通過“蜘蛛”程式在網際網路上提取各個網站的信息來建立自己的資料庫,並向用戶提供查詢服務,是一種真正意義上的搜尋引擎。如AlaVista、Google、Excite、Hotbot、Lycos等。
全文檢索搜尋引擎資料庫中的數據來源分兩種一是定期搜尋,也就是每隔一段時間搜尋引擎就主動派出“蜘蛛”程式,對一定IP位址範圍內的網際網路站進行檢索,一旦發現新的網站,就會自動提取網站的信息和網址加入自己的資料庫。二是網站提交的信息,即網站所有者主動向搜尋引擎提交地址,搜尋引擎會在一定時間內派出“蜘蛛”程式搜尋所提交的網站的相關信息,並存入自己的資料庫中。總的說來,都是“蜘蛛”程式搜尋到的網頁的具體內容。所以當我們用這種搜尋引擎進行搜尋時,能夠精確到具體網頁,哪怕是網頁上用戶看不到的一個小標記也可以搜尋出來。
當用戶以關鍵字查找信息時,搜尋引擎會在其資料庫中進行搜尋,當找到與用戶要求相符的網站後,按照其特定的算法排列順序,然後將網頁連結反饋給用戶。
其實,網際網路發展到今天,搜尋引擎和目錄索引已經開始相互融合,原來一些全文檢索搜尋引擎現在也提供目錄索引服務,有些則在搜尋結果中直接列出其他目錄索引的網站,比如Google就在其搜尋結果中列出Open Directory的網站;而像Yahoo!這樣的目錄索引也開始和Google的搜尋引擎合作,從而擴大搜尋範圍。
目錄索引與全文搜尋引擎的區別
目錄索引雖然有搜尋功能,但在嚴格意義上算不上是真正的搜尋引擎,僅僅是按目錄分類的網站連結列表而已。用戶完全可以不用進行關鍵字(KeyWords)查詢,僅靠分類目錄也可找到需要的信息。目錄索引搜尋引擎中最具代表性的莫過於大名鼎鼎的雅虎,其他還有Open Directory Project(DMOZ)、LookSmart、About等。國內的搜狐、新浪、網易搜尋也都屬於這一類。
目錄索引與全文搜尋引擎的區別在於它是由人工建立的,通過“人工方式”將站點進行了分類,不像全文搜尋引擎那樣,將網站上的所有文章和信息都收錄進去,而是首先將該網站劃分到某個分類下,再記錄一些摘要信息,對該網站進行概述性的簡要介紹,用戶提出搜尋要求時,搜尋引擎只在網站的簡介中搜尋。它的主要優點有:層次、結構清晰,易於查找;多級類目,便於查詢到具體明確的主題;在內容提要、分類目錄下有簡明扼要的內容,可以使用戶一目了然。缺點是搜尋範圍較小、更新速度慢、查詢交叉類目時容易遺漏。
