一、概述
 漢編圖示
漢編圖示漢語程式設計語言,即沈志斌教授發明的一種電腦程式設計語言,簡稱“漢編”,或者“漢語言”。它是一種採用漢民族語言文字進行電腦編程的語言系統,支持基於漢語字、詞編程,符合計算機符號語言規範,並繼續向自然語言發展。它已經取得國家專利,國家發明專利號:ZL94107330.0國際專利主分類號:G06F17/00)。
中國是個多民族的國家,語種眾多,有:漢語,藏語,滿語等;中文字型也非常多,如篆書、金書、隸書、楷書等。嚴格來說稱“漢語編程”而不稱之為“中文編程”。因為,漢語是中國的官方語言,所以,但一般情況下,稱中文編程時,也特指漢語編程。
漢語程式設計語言,是中文程式語言的一個分支,但由於研發時間比較早,當時中國大陸少有其它中文程式語言面世,所以,發明者也稱其為“漢語編程”。
在當今中文程式語言發展多樣化的情況下,我們一般簡稱沈志斌教授在二十世紀九十年代實研發的漢語程式設計語言為“漢編”,簡稱吳濤先生在二十一世紀初研發的易語言漢語編程為“易語言”。
二、編譯原理
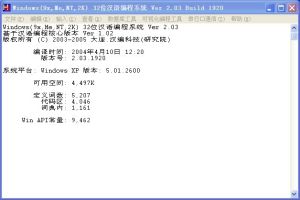 漢編編譯器
漢編編譯器
傳統的編譯原理主要是詞法分析、語法分析、語義分析、中間代碼生成、代碼最佳化和目標代碼生成的編譯翻譯過程。
漢編編譯器對傳統編譯過程進行了性發展,形成了分析詞法生成詞典,分析語法生成局部代碼,組裝局部代碼生成目標程式三個中間模糊過程。
漢編編譯器簡化了現有編譯過程多層次、多結構、多環節,極大地提高了編譯效率,編譯生成的目標代碼空間緊湊,數據空間無縫隙連線,如果有一個位元組受到侵犯,整個程式就會發生意想不到的中斷過程,最大限度地防止為病毒程式留有貯存的計算機空間,提高程式的抗干擾能力。
三、發展歷程
漢編的發展早於1993年,看起來像Forth,是中國人自己研發的完全以漢語為描述語言的電腦程式設計語言,它完全具有中國自主智慧財產權。作為一種計算機語言,它和現在流行的大部分計算機語言具有一些共同的特點,都是人機對話必須的工具語言。但該語言絕非曾流行過的任何一種計算機語言的簡單漢化,或是為某種軟體製造一個中文環境。這是一個完全由中國人自行開發,由中國人自我掌握全部原始碼,從形式到內容全面符合中國人的思維方式,使用漢文字表達的面向對象、面向問題電腦程式設計語言。“漢語編程”具有自成平台、面向對象、面向問題、所見即所得、高度安全性、強大的繁衍功能、高度兼容性以及資源占用少、速度快等特點,開闢了計算機語言發展的新紀元。自2003年以後只見推廣,雖未見新版編譯器發布,但允許學習者自己向指令集(詞典)裡面,擴充更多的命令詞!
四、與 JAVA、C++ 的異同
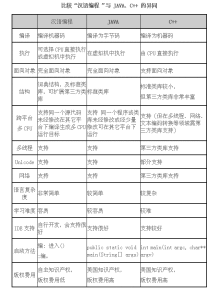 比較漢編與JAVA、C++的異同
比較漢編與JAVA、C++的異同五、編程實例
(一)、製作簡視窗
1、在編譯器上輸入如下(不包括實心五角星)代碼:
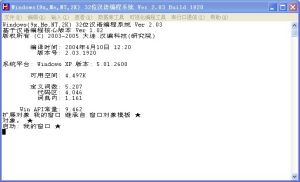 簡單視窗代碼
簡單視窗代碼2、運行結果如下:
 運行結果
運行結果3、上述程式代碼結構如下:
擴展對象 <用戶自定義視窗名> 繼承自 視窗對象模板
對象。
啟動: <用戶自定義視窗名>
(二)、新詞編寫
漢語言的視窗編程還是好理解的,初學者往往對數摞不太容易理解,主要是數據運算比較抽象了,傳統程式語言的參數都用變數來標識,而漢編語言的指令參數可以直接通過數摞來提供,這樣就造成了抽象性加強。當然,初學者,可以不使用數摞來傳遞參數,比如,平方的編寫。
1、使用變數來傳遞參數如下:
編平方
{底數\--}
底數底數*
。
((雙括弧裡邊的內容為解釋
註:平方{底數\--}相當於傳統編程中的平方(底數)
其中{這裡為輸入參數\這裡為中間變數定義--這裡為輸出結果}
直接使用數摞傳遞參數,這些可以不定義
))
2、使用數摞直接傳遞參數如下:
編平方
♂*
。
((雙括弧裡邊的內容為解釋
平方的計算過程為:
數1*數1在漢編中,用後綴表示法表示為:
數1數1*
簡化為:
數1♂*
♂的功能是複製數摞頂層的一個數,這裡即複製數1
我們在編寫平方這個詞的時候,就要考慮到,平方的功能,平方,這個詞必須能計算所以數字的平方值,所以,底數不能放在詞(指令或函式)裡邊,必須通過參數提供,因此,就有如下形式:
編平方
♂*
。
這樣,在初學才看來,就顯得抽象了,我們看到這個詞的時候,第一感覺就是要想到,這個詞,有一個參數,而♂複製的數字正是參數,這樣才能理解平方這個詞的含義。
有人會說,假如,有些新詞參數有多個,非復複雜,用戶無法判斷參數的是什麼,有多少,又怎么辦呢,其實,漢編中,也有標準的參數解釋法則,上面的平方新詡編寫,規範的形式如下:
編平方(數字1---)
♂*
。
注參數注釋採用(輸入參數---返回結果)的形式,當然,這只是注釋而已,這裡產沒有定義任何變數、字元串之類的。
))
(三)、數摞操作
漢編與傳統程式語言的不同:引入了數摞概念;漢語言中,數摞可以用來存放數字,進行各種運算。
示例代碼如下(下面是在編譯器上輸入的漢語言代碼,不含實心五角星和“看數摞”、“顯”後面的內容):
 數摞操作
數摞操作同義詞複製♂★
看數摞數摞已空!★
5★.
看數摞[1]5★.
複製★..
看數摞[2]55★..
摞初始★
編平方
複製*。★
2平方顯4★
3平方顯9★
((
從上面代碼可以看出,漢語言代碼和C語言在表達形式和編譯方式上是有本質的不同的,下面通過對上面發出的小代碼注釋,來體驗數摞操作:
示例代碼如下(下面是在編譯器上輸入的漢語言代碼,不含實心五角星和“看數摞”、“顯”後面的內容,斜槓後面為,為代碼解釋):
漢編語言中,用反斜槓來表示單行解釋,用雙括弧表示多行解釋。
漢編採用詞典式架構,因此,漢編指令,即漢編詞,漢編詞分為編譯器已有的系統詞和用戶新編的新詞。
在漢編編譯器上,輸入一條指令按回車鍵後執行,★號表示執行成功。
))
同義詞複製♂★
\解釋:通過同義詞這個系統詞將新詞複製定為與♂功能相同(同義)。
看數摞數摞已空!★
\系統詞:看數摞,是用來查看數摞上的數的,現在,查看結果:數摞已空,說明數摞上沒有數
5★.
\在數摞上放入一個數:5
看數摞[1]5★.
\用看數摞系統詞查看數摞上的數,發現數摞上有一個數:5(中括弧內的數為數摞上數的總個數,中括弧後面為數摞上所有數字的顯示
複製★..
\執行剛才定義的新詞:複製,試試看能不能將數摞上的數複製
看數摞[2]55★..
\查看結果表明,數摞上的數變為兩個,說明,複製這個詞正確
摞初始★
\用摞初始這個系統詞來清除數摞上的數,使數摞為空
編平方
複製*。★
\編寫新詞:平方在漢編中,一個指令(詞)的編寫以編開頭,以。結尾
2平方顯4★
\測試新詞:平方,如上計算:2的平方(系統詞:顯,意思將數摞上的一個數顯示出來)
3平方顯9★
\再次測試:平方,如上計算:3的平方
\當然,我們也可以用看數摞來查看計算結果
摞初始
2平方看數摞[1]4★.
\測試新詞:平方,如上計算:2的平方
3平方看數摞[2]49★..
\再次測試:平方,如上計算:3的平方
((注意:顯這個詞僅僅是顯示數摞上的一個數,而看數摞,是查看數摞上的所有數;顯這個系統詞顯示數摞上的數的時候,同時會清除在數摞上顯示的該數,而看數摞這個詞僅僅是查看數摞上的所有數字,而不會清除數摞上的數字。))
六、發明者簡介
沈志斌1956年9月8日生於南京,1974年12月入伍。1983年曾因發明“發動機不解體測功儀”而獲全軍科技成果進步獎,並榮立一等功,並破格保送到解放軍南京工程學院本科班深造,畢業後分配到北京軍區指揮自動化工作站任工程師。漢語編程的基礎構想和基礎算法及其基本功能驗證,便始於此。1995年沈志斌離開部隊後,曾分別就職於航天工業部和信息產業部,後到國家漢語編程研究院和北京國之經典漢語編程科技總公司任總工程師。沈志斌之於漢語編程就當相比爾•蓋茨之於windows作業系統。沈志斌和他的團隊歷經20多年的研發,終於讓漢語成為一種新型的計算機語言,並廣泛套用在編程中。其成果有:《漢語程式設計語言》、《漢語編程基礎教程》﹑漢語編程資料庫開發環境、漢語編程單片機的計算機系統(專利)、非接觸式IC卡可程式讀寫器(專利)等等。但是任何一項影響較大的發明都不應該是一個人的功勞,而應該歸功於人類歷史的進步,就像漢語編程的發明就是根源於中國五千年的燦爛文明,中國具有世界上最多人口的語言民族,漢語編程是必然應該被開發出來也必然應該被廣泛利用的。
