方法
常用的數據增強方法有:
• 旋轉 | 反射變換(Rotation/reflection): 隨機旋轉圖像一定角度; 改變圖像內容的朝向;
• 翻轉變換(flip): 沿著水平或者垂直方向翻轉圖像;
• 縮放變換(zoom): 按照一定的比例放大或者縮小圖像;
• 平移變換(shift): 在圖像平面上對圖像以一定方式進行平移;
• 可以採用隨機或人為定義的方式指定平移範圍和平移步長, 沿水平或豎直方向進行平移. 改變圖像內容的位置;
• 尺度變換(scale): 對圖像按照指定的尺度因子, 進行放大或縮小; 或者參照SIFT特徵提取思想, 利用指定的尺度因子對圖像濾波構造尺度空間. 改變圖像內容的大小或模糊程度;
• 對比度變換(contrast): 在圖像的HSV顏色空間,改變飽和度S和V亮度分量,保持色調H不變. 對每個像素的S和V分量進行指數運算(指數因子在0.25到4之間), 增加光照變化;
• 噪聲擾動(noise): 對圖像的每個像素RGB進行隨機擾動, 常用的噪聲模式是椒鹽噪聲和高斯噪聲;
• 顏色變化:在圖像通道上添加隨機擾動。
• 輸入圖像隨機選擇一塊區域塗黑,參考《Random Erasing Data Augmentation》。
例子
場景數據有800萬張,365個類別,各個類別的樣本數據非常不平衡,很多類別的樣本數達到了4萬張,有的類別樣本數還不到5千張。這樣不均勻的樣本分布,給模型訓練帶來了難題 。
Label Shuffling平衡策略
受到冠軍團隊的Class-Aware Sampling方法的啟發下,海康威視提出了Label Shuffling的類別平衡策略。具體步驟如下:
首先對原始圖像列表按照標籤順序進行排序。
然後計算每個類別的樣本數,並且得到樣本最多的那個類別的樣本數
根據這個最多的樣本數,對每一類隨機產生一個隨機排列的列表
然後用每個類別的列表中的數對各自類別的樣本數求余,得到一個索引值,從該類的圖像中提取圖像,生成該類的圖像隨機列表;
然後把所有類別的隨機列表連在一起,做個Random Shuffling,得到最後的圖像列表,用這個列表進行訓練。
1.首先對原始圖像列表按照標籤順序進行排序。
2.然後計算每個類別的樣本數,並且得到樣本最多的那個類別的樣本數
3.根據這個最多的樣本數,對每一類隨機產生一個隨機排列的列表
4.然後用每個類別的列表中的數對各自類別的樣本數求余,得到一個索引值,從該類的圖像中提取圖像,生成該類的圖像隨機列表;
5.然後把所有類別的隨機列表連在一起,做個Random Shuffling,得到最後的圖像列表,用這個列表進行訓練。
Label Smoothing策略
Label Smoothing Regularization(LSR)就是為了緩解由label不夠soft而容易導致過擬合的問題,使模型對預測less confident。LSR的方法原理:
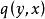 數據集增強
數據集增強  數據集增強
數據集增強  數據集增強 數據集增強
數據集增強 數據集增強  數據集增強 數據集增強 數據集增強
數據集增強 數據集增強 數據集增強 假設表示label的真實分布;表示一個關於label,且獨立於觀測樣本(與無關)的固定且已知的分布,通過下面公式(1)重寫label y的分布:
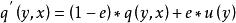 數據集增強
數據集增強 (1)
 數據集增強 數據集增強 數據集增強 數據集增強
數據集增強 數據集增強 數據集增強 數據集增強 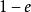 數據集增強 數據集增強 數據集增強
數據集增強 數據集增強 數據集增強 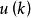 數據集增強 數據集增強 數據集增強
數據集增強 數據集增強 數據集增強 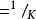 數據集增強
數據集增強  數據集增強
數據集增強 其中,屬於[0,1]。把label的真實分布與固定的分布按照和的權重混合在一起,構成一個新的分布。這相當於對label中加入噪聲,y值有e的機率來自於分布。為方便計算,一般服從簡單的均勻分布,則,表示模型預測類別數目。因此,公式(1)表示成公式(2)所示:
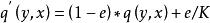 數據集增強
數據集增強 (2)
注意,LSR可以防止模型把預測值過度集中在機率較大類別上,把一些機率分到其他機率較小類別上。
