
基本介紹
網路數據處理是網路信息計量學的重要組成部分,也是當前網路界、新聞傳播界、信息管理界都十分關注的熱點研究領域之一。有科學價值的資料庫,應能實現基於資料庫的數據挖掘和科學研究。資料庫是支持知識發現的基礎工程。要獲得高信息含量的、有用的知識,理想情況是原始數據是不含噪聲的正確數據。
數據是組成資料庫的基本單元,構建高質量的資料庫,必須對原始數據進行數據預處理,也就是所說的數據最佳化。
最佳化模型
數據分析最佳化模型
對數據進行分析重組可以很大程度上減少數據轉化過程中的為了轉化而進行的查詢次數,也能最大程度上的提高快取命中率。首先我們判定哪些欄位需要進行轉化。如果僅有一個欄位需要轉化,那么只需將數據根據相關欄位進行分組重排。這組數據的欄位轉化關係可以完全加入到快取中。而且可以保證的是這個組的數據處理完畢後,其他的組不會用到這個快取中的數據。也就是說這個欄位被移除快取後,就不會再加入快取了。如果有多個欄位,就要通過抽樣試驗分析欄位問的相關性,按相關性的順序進行數據重組。
程式設計師在進行數據抽取時只要聲明要轉化欄位和相關性欄位就可以了。並把它保存在配置檔案中。轉化欄位非常容易的識別出,但是相關性欄位除了一些常識性的可以立刻判斷出,如一個部門的人重疊性很高,一個品牌的汽車重疊性很高。但有很多,用戶也無法識別。框架提供了相關性抽樣試驗數據學習方法,抽取三個不相關數據子集,分別進行相關性命中率測試,取命中率平均值。最高的就為最相關的欄位。
用戶編寫的SQL語句,要先進行語法語義分析。先分析這個SQL有哪些欄位。去最佳化配置檔案中找出待轉化欄位和相關欄位,判斷該SQL是要加入分組條件還是分組加排序條件。第二就是看看該SQL是不是會進行全盤掃描。如果會導致全盤掃描轉化為按照索引進行掃描。最後根據以上兩個方面進行SQL重寫,生成符合要求的SQI,讓取出的數據變得有規律,使得下一步進行數據轉化,快取命中率大大提高。
1.對檔案的分析過程
這部分主要是如果數據源是文本檔案,如EXCEL表格時,根據文本類型,調用文本檔案的一些操作函式,根據配置檔案的規則,對EXCEL按照某些列進行排序,形成有規律的數據。再被引入到系統之中。方法和SQL類似。
2.數據重組
從數據分析模型中已經得知需要按照哪些屬性進行重組,重組屬性的優先權。如果數據源是檔案,我們需要對檔案進行排序。如果數據源是資料庫,那么我們需要對查詢SQL按照屬性優先權進行重寫。
SQL最佳化模型
主要是對數據轉化時,有些屬性需要根據從目標資料庫查詢出的數據才能轉化的情況。為了使快取置換的時間變短,需要對查詢SQL進行最佳化。經過SQL語句的預處理,將SQL語句分離成片段,找到片段中的各個部分,將片段主體部分拆分出來,根據規則最佳化SQL語句,還原整個SQL語句6個部分。
1.SQL語句的預處理
在對SQL語句進行分析之前,有必要對它進行一些預處理,這樣能減輕不少後面編程的負擔。預處理的主要工作是對SQL進行標準化,方便後續的處理。標準化是要去空格,統一成小寫格式,多行變為一行
2.將SQL語句分離成片段
預處理後,SQL語句變為我們想要的格式。接下來將這個字元串按照某種限定符分為幾個部分。
3.找到片段中的各個部分
有了表示片段的正則表達式,找到片段後從中分離出片段起始標誌start片段主體body和片段結束標誌end就很容易了。
4.對主體部分進行更深入的分析
5.將片段還原成主體
我們經過前四部分,已經將SQL分析完畢,但我們最終的目的還是將SQL還原,我們的目的是將前四部分分析的記過整合起來
6.最佳化SQL語句
快取最佳化模型
和以往系統在初始化時初始快取不同,這個快取是業務快取,且是不斷變換的。需要在數據抽取階段時進行初始化,隨著數據類別的變化,快取內容也要不斷的進行替換。
如果有多個屬性需要進行轉變。優先權高的屬性使用的快取不需要置換。而優先權較低的快取內容需要進行置換。因為置換的內容聯繫性較強。也就是說用到的幾率都是相近的,因此,最近沒被用到的,往往最容易被用到。所以使用LRU置換算法。
最佳化流程
主要流程分三個方面,分別是數據採集、數據分析和數據處理。下面將分別介緇這三個步驟所要完成的主要功能。
1.數據採集
軟體測試方案生成子系統根據不同的測試部門和不同的測試項目的具體要求確定相應的數據採集範圍,以實時數據和歷史數據作為基礎採集系統運行當中需要的數據。
2.數據分析
對於實時數據,系統將根據輸入的檔案或者命令,將其按照給定的設計要求保存到對應的數據變數和數組中,供測試管理人員生成新方案使用。
對於歷史數據,系統需根據不同的數據表內容,分析其中的有用信息,並對其進行深入的分析。
3.數據處理
每次系統運行開始時,對系統中的各種數據進行總結與整理,將其按照系統要去放入對應的變數或者數據表當中,以供下一步工作使用。
批量處理框架
研究背景
在計算機領域裡,很多系統的開發和使用都離不開準確的數據。而這些數據很多時候都是由別的系統或資源產生和提供的。數據在不同的系統之間雖然內含一致,但表現形勢不同。因此我們往往需要將數據從一個系統導入另一個系統中,而大部分數據需要經過處理後再導入。而這個過程會出現三個問題。
第一個問題是處理速度。如果數據量比較大,或者涉及資料庫表非常多,或者轉化過程邏輯很複雜,或者數據大部分都需要映射。那么處理數據和導入數據的過程就會占用大量的時間,在這段時間內很多因素都會導致批量處理過程的失敗,這就造成了系統的不穩定性。而有些批量處理數據過程也需要在短時間完成,以給用戶以良好的體驗過程。這個是論文解決的重點。
第二個問題就是導入過程往往是把抽取數據,轉化數據,導入數據過程和它們關聯的業務僅僅聯繫在一起。讓代碼變得耦合性高和雜亂無章。使得批量處理過程沒法擴展和重用。如果出現了一個新的業務的批量數據導入,就要做很多重複工作,甚至重新導數據。人們曾經利用MVC模式的struts框架成功分離了頁面元素和業務邏輯元素。那么導數據過程也可以利用框架分離準備數據過程和處理數據過程,讓程式設計師把業務邏輯都寫入一個業務邏輯類中。而取數據,插入數據過程由框架完成。
第三個問題是,在處理數據的過程中,對於過程中處理的異常狀況沒有恰當的處理。最壞的情況下是導完數據後,不知道哪些成功了,哪些失敗了。這樣導數據工作將變得毫無意義。稍微好一點的情況是知道導入失敗的記錄,然後利用記錄去手工調整。這樣雖然最後也能完成批量處理數據過程,但浪費了很多時間。框架會把異常記錄成為異常信息和異常關鍵字兩部分,根據異常信息進行微調,在根據異常關鍵字進行補發。
過程介紹
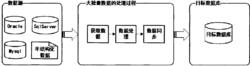 數據最佳化
數據最佳化大批量數據的處理是將數據從一個數據源經過處理和轉化後,同步到另一個數據源的過程。這個過程關注以下問題:從數據源讀取數據,數據的處理,數據的寫入。大批量數據處理過程有以下特點:數據源的多樣性造成取數據方式的多樣性。轉化過程比較複雜,有的設計運算,有時需要查詢,耗費大量時間。同步過程頻繁,如果數據量大,對目標資料庫寫入次數過多,消耗大量時間。
獲取數據是大批量數據處理過程的一個重要組成部分,它負責將分布的、異構數據源中的數據,如關係數據、數據檔案等的數據抽取出來,載入到記憶體中,以方便對數據發生重要的重構。
數據處理是將源數據轉換為目標數據的關鍵環節。它指的是對於數據源獲取到的數據,經過一系列的轉換來變為目標資料庫需要的數據的過程,通過比較源數據和目標數據的關係,實現了各種複雜的轉換,包括數據格式轉換,數據類型轉換,數據匯總計算,數據拼接等。
數據同步主要是將經過轉換和清洗的數據載入到目標資料庫中,供目標系統使用處理。
系統架構
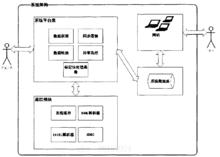 系統的體系結構圖
系統的體系結構圖開發人員利用該框架對大批量數據進行處理進行編程時,通過取數據組件獲取到數據,程式設計師設定一次性處理的數據量,並確定用什麼樣的規則對數據進行處理和轉化,將數據送入倉庫。另外,程式設計師需要設定消費者邏輯,如將數據寫入哪個表,並將這個邏輯傳入數據同步組件。剩下的問題程式設計師都不需要關注,框架會完成整個數據同步過程。如果同步過程是不穩定的,程式設計師需要調用異常處理函式。保證同步過程的順利進行。
