
研究背景
背景
在最近幾十年中,許多研究人員對實時資料庫和實時數據管理進行了深入的研究。在流程工業控制領域,比較有代表性的實時資料庫產品有由OSI Software Inc開發的、著名的PIant Information 系統 和由Aspen TechnoIogy Inc開發的Info-PIus 系統。
數據壓縮是實時資料庫中一個比較關鍵的課題,為了節省存儲空間,一個歷史數據在被送入歷史資料庫前進行數據壓縮處理是必要的,因為需要確信寫入數據緩衝池的歷史數據是重要的。此外,正如大家所知,歷史數據壓縮算法對於解壓縮歷史數據也是非常重要的,需要高效的數據壓縮算法來滿足在實時資料庫中大量數據信息的存儲需要,為此,OSI Software Inc.開發了著名的旋轉門壓縮算法(SDA)。
為了有效使用磁碟存儲,需要對歷史數據進行實時壓縮,不僅需要很高的數據壓縮率,而且需要高精度的數據壓縮。
方向與現狀
國內外相關研究主要集中在數字地圖壓縮和模式識別後圖形的簡化,研究目標主要分3類:
min—ε,壓縮後形態點數目已知,要求形變最小;
min—#,壓縮後最大形變已知,要求形態點數最小;
min—rate,壓縮後最大形變已知,要求數據營最小。
1.min—ε,壓縮後形態點數目已知,要求形變最小;
2.min—#,壓縮後最大形變已知,要求形態點數最小;
3.min—rate,壓縮後最大形變已知,要求數據營最小。
歷史數據壓縮
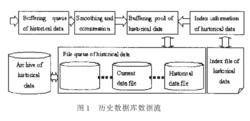 歷史資料庫數據流
歷史資料庫數據流當有歷史數據來臨時,根據感測器的測量精度高低,歷史數據首先通過必要的平滑處理和壓縮處理,確定是否需要存儲在歷史資料庫中。當確定要存儲後,首先將數據存儲在歷史數據緩衝池中,待緩衝存滿後,再將數據成塊地存入當前歷史檔案中,歷史數據檔案以佇列形式存放,當存滿後,選擇最早的歷史數據檔案作為可用的空歷史檔案(圖)。
圖中歷史數據緩衝佇列是實時資料庫系統的核心與歷史庫的連線橋樑,用於緩衝實時庫核心發來的實時數據。數據平滑是對測量噪聲進行處理,根據儀器的測量精度來確定數據是否需要平滑處理。數據壓縮是不可缺少的一步,通過壓縮處理確定需要存儲的關鍵數據點,然後將關鍵的數據點寫進歷史數據緩衝池中。歷史數據緩衝池是歷史數據在記憶體中的主要緩衝空間,用於存儲近期歷史數據,從而提高了近期歷史數據的存取效率,減少了不必要的磁碟操作。
歷史數據檔案佇列是歷史數據存儲的主要磁碟空間,在佇列中起碼要有一個歷史數據檔案,某時刻歷史數據的追加只在當前歷史數據檔案進行。當歷史檔案存滿以後,設定下一個可用的空歷史數據檔案為當前歷史數據檔案;當已無空檔案時,則將最早的檔案清空。
壓縮算法技術
LZW算法
基本處理過程
字典編碼的基本處理過程比較簡單。首先從輸入數據流中讀取待壓縮的文本串,放入先行緩衝區,然後進行編碼。把先行緩衝區中的內容與字典視窗中的內容進行比較,如果有相匹配的部分,則按規定的格式用代碼表示輸入字元串。經匹配、編碼後的數據流從先行緩衝區依次進入到字典視窗中,成為字典的一部分。由於文本視窗的大小是固定的,因此原有字典中的一部分內容將從視窗的另一端滑出。
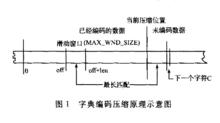 字典編碼壓縮原理示意圖
字典編碼壓縮原理示意圖這樣,數據不斷地由先行緩衝區一端補充到字典視窗,同時又不斷有數據從該視窗的另一端滑出,類似於用一個固定大小的視窗從輸入文本上滑過。因此,LZW壓縮算法又被稱為滑動窗壓縮。隨著視窗的滑動,字典的內容不斷地發生變化,就好像字典中舊的短語被拋棄,新的短語被加入到字典中,滑動視窗中總保持著最近剛處理過的文本。使用固定大小視窗進行術語匹配,而不是在所有已經編碼的信息中匹配,是因為匹配算法的時間消耗d太多,必須限制字典的大小才能保證算法的效率;隨著壓縮的進程滑動字典視窗,使其中總包含最近編碼過的信息,因為對大多數信息而言,要編碼的字元串往往在最近的上下文中更容易找到匹配串。字典編碼壓縮原理示意圖如圖所示。
處理對象
Lzw算法有3個重要的對象:輸入數據流、輸出編碼流和一張用於編碼的字元串表。輸入數據流是指被壓縮數據;輸出編碼流是指壓縮後輸出的編碼流;字元串表存儲的是數據的索引號,相同塊的數據只輸出第一塊的索引號,從而實現了數據的壓縮。其壓縮算法的過程為:
(1)初始化索引號及字元串表。將索引號賦初值,同時將字元串表清零;
(2)從數據流中讀入字元作為前綴,並將其賦給變數old;
(3)從數據流中讀入字元放到變數new中;
(4)變數old左移8位與變數new相加,組成新的字元串,並查找字元串表,若表中存在組成的新字元串,則取出表中索引號給變數old,轉到過程(3);若表中不存在,則將變數old中的數據輸出,然後判斷表中索引號是否大於最大設定值(如12位編碼的最大設定值為4096),若小於最大設定值則將新的字元串的值放到當前索引號的位置,同時索引號加1,然後轉到過程(2);若索引號大於最大設定值,則說明字元串表滿,則輸出串結束符,接著從過程(1)重新開始數據壓縮。
矢量壓縮技術
矢量壓縮技術主要分為近似方法和量化編碼方法2類。近似方法通過減少組成矢量的點進行壓縮;量化編碼方法根據某些方式將矢量坐標量化為相關性較強的形式。然後編碼壓縮。
近似方法由Douglas等於1973年提出,國內外一些學者對其進行了改進,近似方法壓縮過程效率較低,時間和空間複雜度為O(N ),使用動態規劃可提高其效率,將空間複雜度降為O(N),時間複雜度降為O(N)~O(N ).
量化編碼方法的相關研究主要有Shekhar等提出的聚類方法,Kolesnikov等提出的鏈碼方法[和基於動態規劃的方法。聚類方法的空間複雜度為O(N),時間複雜度大於O(N),並且需要額外空間存儲字典;動態規劃方法空間複雜度為O(N),時間複雜度為O(N)~O(N );鏈碼方法將曲線轉化成鏈碼序列,然後使用上下文相關的文本壓縮算法壓縮,效率較低,當容限較小時,鏈碼序列較長,壓縮效果較差。
近似方法和量化編碼方法的時間空間複雜度較高,不能在移動計算環境中實時壓縮解壓縮海量數據。目前移動計算環境中常用的曲線壓縮方法是類型轉換方法,這種方法將坐標由浮點數轉化為整型數存儲,其優點是速度可以滿足實時性要求,缺點是壓縮程度有限。
壓縮算法比較
判斷一個壓縮算法好壞的一個重要指標是比較它的解壓縮誤差。對於測試數據集,當誤差約束滿足時,當前測試點通過壓縮測試、不需要存儲;否則,它將被記錄,並被存儲到資料庫中,此時,新的存儲點將取代原來的上一個存儲點,並作為新的、數據壓縮的起始點。
判斷壓縮算法好壞的另一個指標是數據壓縮率,這是實時資料庫中壓縮算法的一個很重要指標,這裡定義為(M-N)/M,其中,M 為總測試點數,N 是存儲點數。
實時壓縮系統
系統結構與組成原理
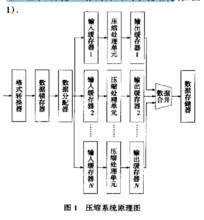 壓縮系統原理圖
壓縮系統原理圖為充分發揮硬體具有的並行計算能力,在設計上採用多路並行、數個功能、時序完全相同的壓縮處理單元同步工作的陣列式系統結構。
在同一時刻,各個壓縮處理單元以連鎖步伐方式同步完成同種操作,即同時完成對圖像數據的讀取、量化、編碼、存儲。系統處理速度為壓縮處理單元的N倍。多路並行和陣列處理,提高了系統的模組化程度,使得系統容易通過擴充處理單元來加快處理速度以適應不同的要求,保證了系統具有高速實時壓縮能力及良好的擴展和重構能力.整個系統工作原理及過程如下:
壓縮系統以數據驅動的方式工作,原始圖像數據以行掃描方式經過格式轉換器,轉變為4×4數據塊,轉換後的數據經鎖存後,由數據分配器,按固定時序送人各個輸入數據快取區,壓縮處理單元從數據快取區讀人數據,而後其內部的分類器、量化器同時計算處理,編碼器、緩衝器以流水線方式順序處理,壓縮結果經緩衝器進入輸出快取區,經數據合併後,送人數據存儲器或傳輸信道;由於圖像數據子區複雜程度不一致,當連續出現紋理複雜塊時,壓縮倍率降低,輸出數據量大,有可能導致信道阻塞,反之,當連續出現平坦塊時,壓縮倍率高,輸出數據量小,可能導致信道空閒;為此,應根據輸出快取區內數據量動態調整壓縮倍率,這可以通過改變分類器的閾值 、 實現.輸入/輸出快取區的設立達到了數據輸入、壓縮、輸出並行流水處理的效果。
